细说Http中的Keep-Alive和Java Http中的Keep-Alive机制
什么是Keep-Alive
这个词看着有点熟,很多地方好像都见过。
TCP的KeepAlive,Http的KeepAlive,现在就连一些前端框架都有类似KeepAlive的东西了(比如VUE.js,保持路由)。
本文介绍HTTP和TCP中的KeepAlive机制,其他方面不在本文讨论范围。
Http中的Keep-Alive
HTTP 持久连接(HTTP persistent connection,也称作HTTP keep-alive或HTTP connection reuse,翻译过来可以是保持连接或者连接复用)是使用同一个TCP连接来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方式。
HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成 之后立即断开连接(HTTP协议为无连接的协议),每次请求都会经过三次握手四次挥手过程,效率较低;当使用 Keep-Alive 模式时,客户端到服务器端的连接不会断开,当出现对服务器的后继请求时,客户端就会复用已建立的连接。
下图是每次新建连接和连接复用在通信模型上的区别:
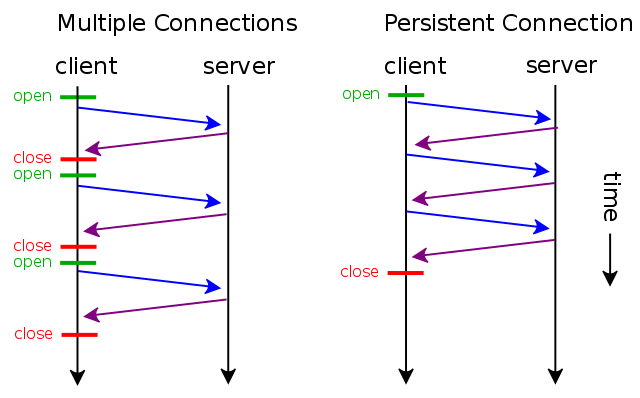
在Http 1.0中, Keep-Alive 是没有官方支持的,但是也有一些Server端支持,这个年代比较久远就不用考虑了。
Http1.1以后, Keep-Alive 已经默认支持并开启。客户端(包括但不限于浏览器)发送请求时会在Header中增加一个请求头 Connection: Keep-Alive ,当服务器收到附带有 Connection: Keep-Alive 的请求时,也会在响应头中添加Keep-Alive。这样一来,客户端和服务器之间的HTTP连接就会被保持,不会断开(断开方式下面介绍),当客户端发送另外一个请求时,就可以复用已建立的连接。
现在的Http协议基本都是Http 1.1版本了,不太需要考虑1.0的兼容问题
Keep-Alive真的就这么完美吗
当然不是,Keep-Alive也有自己的优缺点,并不是所有场景下都适用
优点
- 节省了服务端CPU和内存适用量
- 降低拥塞控制 (TCP连接减少)
- 减少了后续请求的延迟(无需再进行握手)
缺点
对于某些低频访问的资源/服务,比如一个冷门的图片服务器,一年下不了几次,每下一次连接还保持就比较浪费了(这个场景举的不是很恰当)。Keep-Alive可能会非常影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间,额外占用了服务端的连接数。
连接复用后会有什么问题
在没有连接复用时,Http 接收端(注意这里是接收端,并没有特指Client/Server,因为Client/Server都同是发送端和接收端)只需要读取Socket中所有的数据就可以了,解决“拆包”问题即可;但是连接复用后,无法区分单次Http报文的边界,所以还需要额外处理报文边界问题。当然这个通过Http中Header的长度字段,按需读取即可解决。
粘包拆包的介绍可以参考另一篇文章 细说 Netty 中的粘包和拆包
Http 连接复用后包边界问题处理
由于Http中Header的存在,通过定义一些报文长度的首部字段,可以很方便的处理包边界问题。
在Http中,有两种方式处理包边界问题:
Content-Length处理包边界
这个是最通常的处理方式,接收端处理报文时首先读取完整首部(Header),然后通过Header中的 Content-Length 来确认报文大小,读取报文时按此长度读取即可,超出长度的报文(“粘包”)不读取,不够长度的报文缓存等待继续读取(“拆包”)。
Chunked处理包边界
对于无法确认总报文大小的情况,可以使用Chunked的方式来对报文进行分块传输,每一块内标示报文大小。比如Nginx,开启Gzip压缩后,就会开启Chunked的传输方式。
通过Wireshark抓包,可以很直观的看初Chunked的原理:
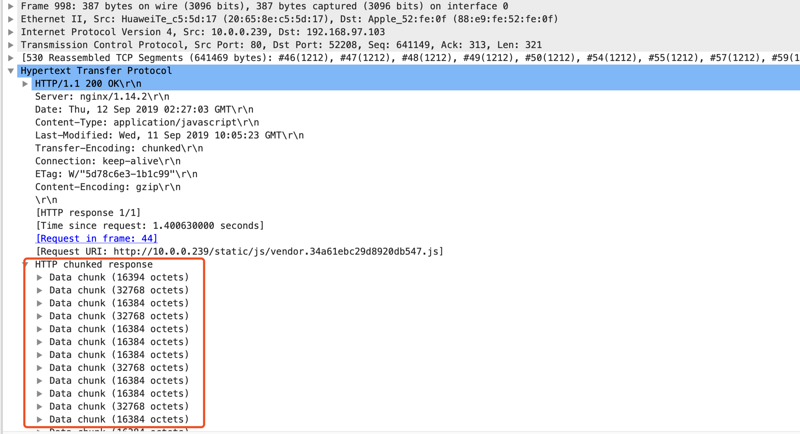
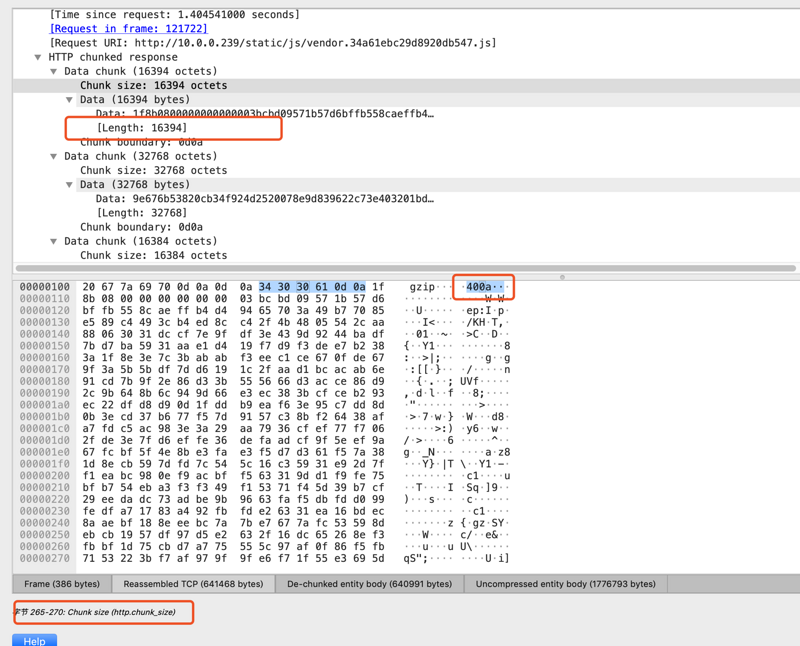
注意,这里的chunk包,和tcp segment不是一回事,chunk只是应用层的一个分包,而tcp的segment 是对应用层报文再次进行分组
每个chunk报文前,会携带当前chunk的大小。
Http 连接复用后怎样断开连接
通过Keep-Alive已经做到连接复用了,但复用之后什么时候断开连接呢,不然一直保持连接,造成资源的浪费。
Http协议规定了两种关闭复用连接的方式:
通过Keep-Alive Timeout标识
如果服务端Response Header设置了 Keep-Alive:timeout={timeout} ,客户端会就会保持此连接timeout(单位秒)时间,超时之后关闭连接。
现在在服务端设置响应Header:
Keep-Alive:timeout=5
通过Wireshark来看下配置了timeout的效果:
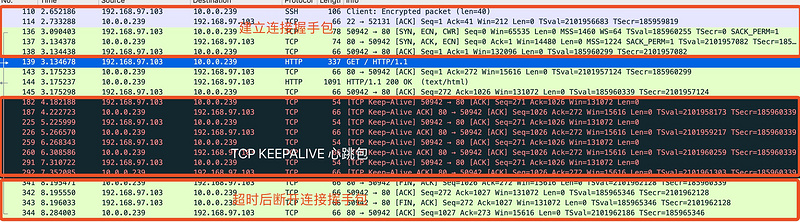
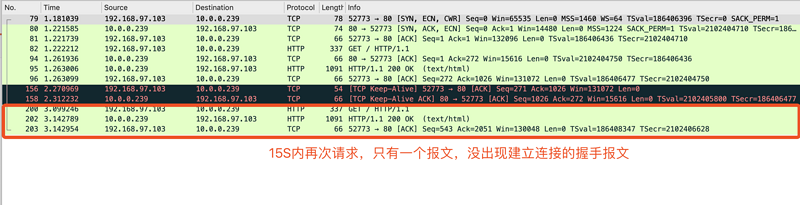
从上图可以看出,客户端发送请求后,在15S内(图上没有体现时间,就当15S吧)保持了连接不销毁,超时后经过了4次挥手,断开连接
但是如果在15S内再次请求,连接是可以复用的,不会重新3次握手。
下图是15S内再次请求的效果:
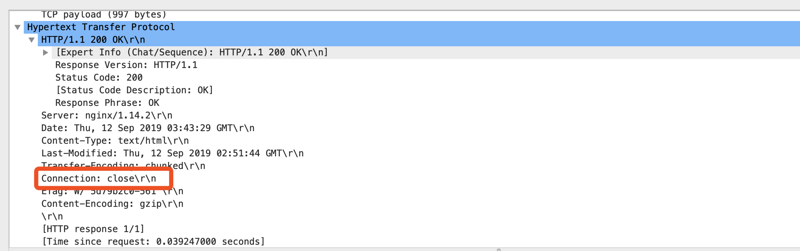
通过Connection close标识
还有一种方式是接收端通在Response Header中增加 Connection close 标识,来主动告诉发送端,连接已经断开了,不能再复用了;客户端接收到此标示后,会销毁连接,再次请求时会重新建立连接。
注意:配置close配置后,并不是说每次都新建连接,而是约定此连接可以用几次,达到这个最大次数时,接收端就会返回close标识(服务端配置方法下面会介绍)
下面来测试下效果,客户端发送两次请求:

通过wireshark截图可以发现,配置了Connection:close之后(服务端设置了请求只可以用1此,所所以请求完成就销毁连接),两次请求都重新建立了连接。
Nginx中设置Keep-Alive(服务端)
Keep-Alive timeout配置:
Syntax: keepalive_timeout timeout [header_timeout]; Default: keepalive_timeout 75s; Context: http, server, location 第一个参数设置一个超时,在此期间保持活动的客户机连接将在服务器端保持打开状态。如果为0则禁用保Keep-Alive。第二个可选参数在“Keep-Alive: timeout=time”响应头字段中设置一个值。 “Keep-Alive: timeout=time”报头字段被Mozilla和Konqueror识别。MSIE在大约60秒内自动关闭保持连接。
Keep-Alive requests(连接可用次数)配置:
Syntax: keepalive_requests number; Default: keepalive_requests 100; Context: http, server, location 设置通过一个保持活动连接可以服务的请求的最大数量。在发出最大数量的请求之后,连接关闭。
Tomcat中设置Keep-Alive(服务端)
在 <Connector> 标签中配置属性:
Keep-Alive timeout配置:
keepAliveTimeout="超时时间" ,默认值是使用为connectionTimeout属性设置的值 。值为-1表示没有(即无限)超时。
Keep-Alive requests(连接可用次数)配置:
maxKeepAliveRequests="连接可用次数" ,-1为永不失效。如果未指定,默认为100。
例如:
<Connector port="8080"
protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
keepAliveTimeout="超时时间(单位秒)"
maxKeepAliveRequests="连接可用次数" />
Apache HttpClient 设置Keep-Alive(客户端)
Apache HttpClient算是Java中最强的HttpClient了,也是最主流的(后端方向),功能强大。
Apache HttpClient在处理KeepAlive的地方设计的比较灵活,提供了可配置的接口,使用者可以使用Http标准的策略,也自定定制策略。
HttpClients.custom()
//连接是否复用策略,通过此策略返回是否复用
//DefaultClientConnectionReuseStrategy是默认的Http策略,不设置也可以
.setConnectionReuseStrategy(new DefaultClientConnectionReuseStrategy())
//连接复用后有效期(持久时间)策略,复用后通过此策略判断复用超时时间
//DefaultConnectionKeepAliveStrategy是默认的判断超时时间策略,读取的是Keep-Alive:timeout=超时时间
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.build();
TCP中的Keep-Alive
TCP中的KeepAlive和Http的Keep-Alive可不是一回事,HTTP中是做连接复用的,而TCP中的KeepAlive是“心跳监测”,定时发送一个空的TCP Segment,来监测连接是否存活。下面介绍下Java中设置TCP KeepAive的一些方式。
Netty中设置Keep-Alive
bootstrap.childOption(ChannelOption.SO_KEEPALIVE, true);
NIO(New NetWorking IO Lib)中设置Keep-Alive
channel.setOption(StandardSocketOptions.SO_KEEPALIVE,true);
BIO中设置Keep-Alive
Socket socket = serverSocket.accept(); socket.setKeepAlive(true);
参考
- https://zh.wikipedia.org/wiki...
- https://www.w3.org/Protocols/...
- http://hc.apache.org/
- http://nginx.org/
- http://tomcat.apache.org/tomc...
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

