LinkedHashMap 原理及源码分析
LinkedHashMap 原理及源码分析
设计简介
首先看看它的继承体系
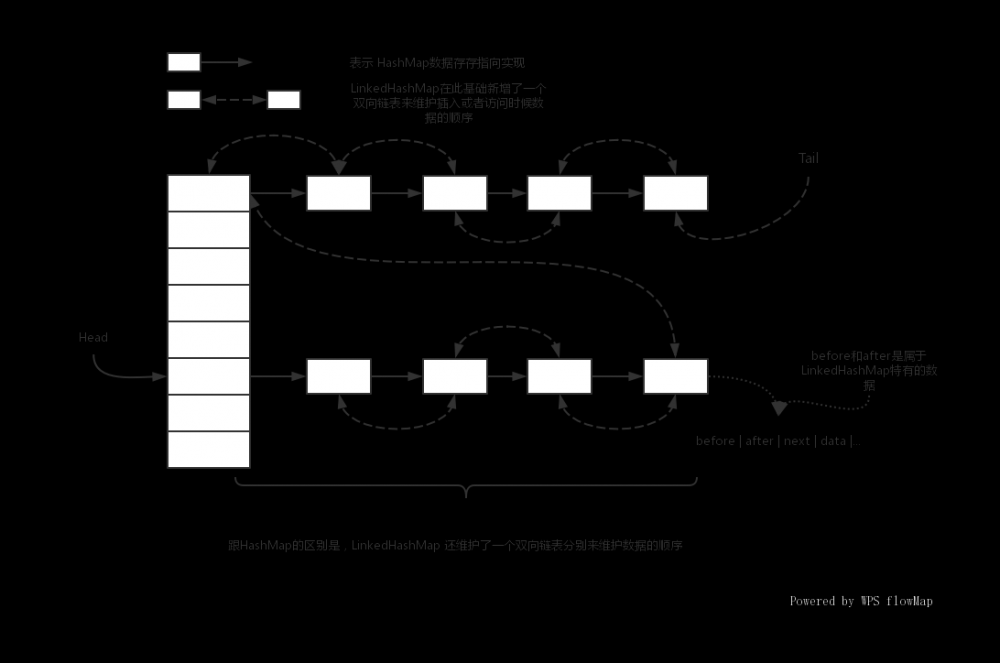
如下图是 LinkedHashMap 的数据结构,当然链表一样可能会转化为红黑树,这里没有画出来,但是它们的双向链表指向方式是一样
思考问题
- LinkedHashMap 和 HashMap 的区别
- LinkedHashMap 是如何保证插入顺序、访问顺序的
- 什么是 LRU 缓存淘汰策略
- LinkedHashMap,accessOrder 的含义
- LinkedHashMap 是否可以实现 LRU 缓存淘汰策略
- 其它的就是 HashMap 相关的思考这里就不再赘述
问题 3:什么是 LRU 缓存淘汰策略
理解这个问题能帮我们更好的理解 LinkedHashMap 排序的含义,LRU(Least Recently Used)最近最少使用策略,我们思考一下在我们使用缓存的时候,往往会划分一部分的内容提供使用,那么当内存不够用了该怎么办呢?是不是需要淘汰一部分不常使用的数据,淘汰策略有很多种,而 LRU 就是其中一种,他是指将最近最少使用的数据淘汰掉,LinkedHashMap 的做法是将最近访问过的就放在了链表最后,那么链表最前面的就是相对而言最近不常用的数据了,那么如果需要淘汰就可以淘汰掉头部的一部分数据即可。
其它的问题我们从源码分析中寻找答案。
变量定义
部分变量定义如下,暂时不理解没有关系后面代码会一个个说明
// 继承了 HashMap 的基础属性的双向链表结点
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
// 双向链表头结点
transient LinkedHashMap.Entry<K,V> head;
// 双向链表尾结点
transient LinkedHashMap.Entry<K,V> tail;
// 是否按访问顺序排序
// 注意这里的排序指的是实现类似的 LRU 功能,访问过的结点数据会被放置链表最后
final boolean accessOrder;
复制代码
这是 HashMap Node 结点的定义
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
复制代码
我们可以看到 Entry 继承了 HashMap 的 Node 在此基础上多了 2 个结点用来维护双向链表分别指向当前结点的前后 2 个结点
构造方法
/**
* 传入默认容量和装载因子去创建一个 HashMap
* 并且默认是不支持按照访问顺序排序的
* @param initialCapacity
* @param loadFactor
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 传入装载因子创建 HashMap 不支持按照访问书序排序
* @param initialCapacity
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
/**
* 根据默认参数创建一个 HashMap 不支持按照访问书序排序
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* 根据一个 Map 去创建 HashMap
* @param m
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
// 首先根据默认参数创建一个 HashMap
super();
// 不支持排序
accessOrder = false;
// 调用 HashMap 的 putMapEntries 方法将数据放入 HashMap 中
putMapEntries(m, false);
}
/**
* 传入默认容量和装载因子创建 HashMap 同时可以指定是否需要按照访问顺序排序
* @param initialCapacity
* @param loadFactor
* @param accessOrder
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
复制代码
可以看到 LinkedHashMap 的构造方法就分为了 2 种
- 去调用了 HashMap 的相关构造方法创建了对应的 HashMap
- 支持 accessOrder 的构造方法支持按照访问顺序排序
插入数据
当我们调用 put(key, val) 的时候我们发现实际上调用的是 HashMap 的 put 方法,调用的 HashMap 的 put 方法的同时在维护一个双向链表来实现 LinkedHashMap 的顺序保证,是通过调用子类的实现方法来完成的,看下面代码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果 table 为 null 先进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果 hash 后制定的槽位为 null 则直接放入数据即可
if ((p = tab[i = (n - 1) & hash]) == null)
// 创建结点
tab[i] = newNode(hash, key, value, null);
else {
// 槽位存在数据就需要检查槽位链表是否存在对应的数据
// 如果有根据策略选择是更新还是放弃
// 如果没有这执行插入
Node<K,V> e; K k;
// 已经存在对应的 key 直接进行赋值后续根据 putIfAbsent 决定是否更新
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果当前节点是一个树节点那么将数据放入红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// binCount 临时统计链表数量
for (int binCount = 0; ; ++binCount) {
// 如果不存在对应的 key 则直接执行插入
if ((e = p.next) == null) {
// 创建一个新结点
p.next = newNode(hash, key, value, null);
// 当链表中的数据数量大于等于 8 的时候
// 需要进行树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果已经存在对应的结点则直接返回后续根据 onlyIfAbsent 决定是否更新
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果存在待更新的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 是否更新数据
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 调用子类的实现方法在访问之后做什么事情
afterNodeAccess(e);
return oldValue;
}
}
// 修改次数 + 1
// 该字段用于后续迭代器 fail-fast
++modCount;
// 数据量大于 threshold 进行 table 扩容
if (++size > threshold)
resize();
// 调用子类的实现方法在插入之后做什么事情
afterNodeInsertion(evict);
return null;
}
复制代码
上面这段代码是 HashMap 的 putVal 方法,看过 HashMap 源码分析的同学应该明白,在 LinkedHashMap 中我们主要看这 3 段代码
// 创建结点的时候就会同时设置 LinkedHashMap 的双向链表 tab[i] = newNode(hash, key, value, null); // 如果在插入数据的时候数据已经存在会调用这个方法 // 意识就是访问到了对应的数据是否需要进行某种排序设置 afterNodeAccess(e); // 如果插入数据成功会调用这个方法 // 意识是是否需要根据某个子类的缓存对应的功能做一些插入后的事情比如删除头部数据 afterNodeInsertion(evict); 复制代码
我们一个一个分析,首先看
newNode()
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// 将插入的结点放置到列表最后
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
复制代码
由这段代码我们就可以看出, 在 LinkedHashMap 中插入数据时候,数据的顺序是按照插入的先后顺序排序,先插入的数据排在前面
afterNodeAccess(e)
这段代码调用的是 LinkedHashMap 对应的实现,查找到了对应的数据根据判断条件决定是否要将其放置尾部,如下图所示
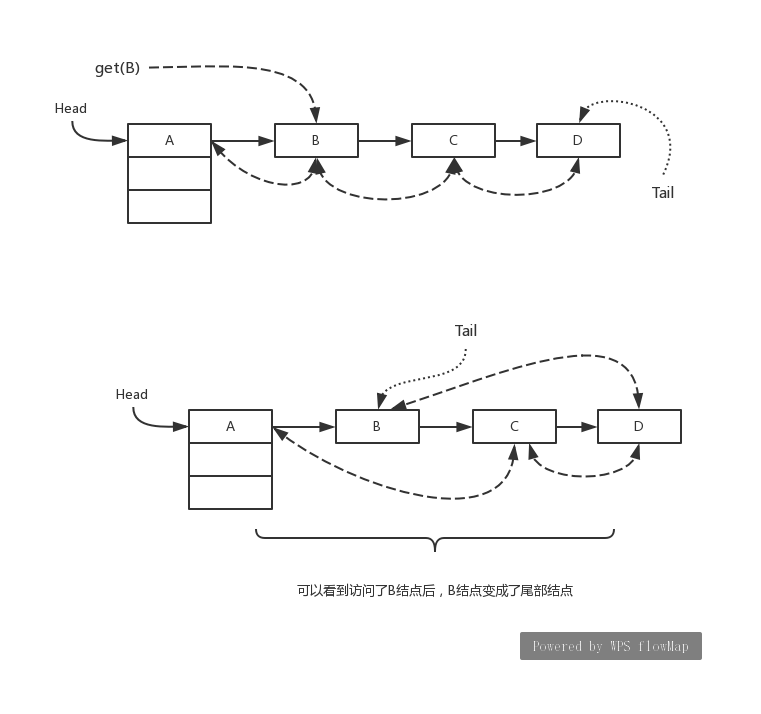
由上图可以看到,在调用 get(B) 之前的双向链表排序是 A->B->C->D,在调用了 get(B) 之后顺序就变为了 A->C->D->B,我们看下源码实现如下
// 将当前传入结点设置为尾结点
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果设置了需要按照访问顺序排序并且当前结点不是尾巴结点
if (accessOrder && (last = tail) != e) {
// 当前结点复制给 p,并且将当前结点的前后结点分别复制给 b, a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 需要将当前结点设置为尾结点所以尾巴结点的下一个结点肯定是 Null
p.after = null;
// 如果前一个结点没有数据,那么当前结点的下一个结点就是 head 结点
if (b == null)
head = a;
// 否则的话,前一个结点的下一个结点就是当前结点的下一个结点,相当于删除掉了当前结点 e
else
b.after = a;
// 如果当前结点的下一个结点不为 null
// 还需要将当前结点的下一个结点的前一个结点设置为当前结点的上一个结点相当于彻底的删除了当前结点 e
if (a != null)
a.before = b;
// 否则当前结点的下一个结点就是尾结点了
else
last = b;
// 如果 b 为 null,意味着就只有当前结点一个数据所以 head 也是它
if (last == null)
head = p;
else {
// 否则的话将 p 设置为链表的最后一个结点
p.before = last;
last.after = p;
}
// 最后再将当前结点设置为 tail 结点
tail = p;
// 修改次数 + 1 用于迭代器 fail-fast
++modCount;
}
}
复制代码
调用这个方法的时候,首先会去判断 accessOrder 设置是否为 true,也就是是否支持按照访问顺序排序,如果为 true
- 将当前结点放置尾部位置
- 结点移动后,调整它原先所处位置的前后结点的指向
- 只有 1 个或者 2 个结点的特殊处理
afterNodeInsertion
最后只要数据 put 成功,那么就会调用 afterNodeInsertion 这个方法在这里调用的是 HashMap 子类 LinkedHashMap 的相关实现,代码如下
// 在 HashMap 插入数据后回调
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 如果 evict 为 true
// 并且 removeEldestEntry 返回为 true
//(它会根据采用不同的缓存策略子类来订制对应的功能是否需要淘汰掉 first 结点)
// 默认不会执行
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
// 删除对应的 HashMap 结点
removeNode(hash(key), key, null, false, true);
}
}
复制代码
可以看到这个方法给我们提供了插入数据的时候是否需要淘汰链表头部数据的功能,removeNode() 调用的是 HashMap 中的 removeNode() 方法
删除数据
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 如果 table 中存在 key 对应的 hash 值
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 如果 key 就是对应槽位的 key 则找到数据
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// 去槽位链表中查找
else if ((e = p.next) != null) {
// 如果是一个树去树节点中查找
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
// 遍历槽位链表查找对应的数据
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 如果找到了 key 对应的值
// 根据后续的判断确定是否需要删除对应的数据结点
// 默认 remove, matchValue: false 需要进行删除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 如果是树节点则删除树中的结点
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
// 如果是 table 槽位上的值,则将其下一个结点复制到槽位上
else if (node == p)
tab[index] = node.next;
// 如果在槽位链表上删除当前节点
else
p.next = node.next;
// 修改次数 + 1 用于迭代器 fail-fast
++modCount;
// 数据长度 - 1
--size;
// 删除后要做的事情留个子类实现
afterNodeRemoval(node);
return node;
}
}
return null;
}
复制代码
这段代码在将 HashMap 原理分析的时候就讲过了,这里我们主要关注的是 afterNodeRemoval(node); 这个方法,我们知道 LinkedHashMap 使用的是双向链表维护结点数据的顺序,那么当删除一个数据的时候可能也要维护对应的双向链表数据,就是调用这个方法来完成的,代码如下
// HashMap 结点被删除后
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 清空当前结点指针
p.before = p.after = null;
// 如果没有前一个结点了,那么 e 之后的结点就为 head 结点
if (b == null)
head = a;
// 否则的话上一个结点的下一个结点为 e 的下一个结点也就是删除了 e 点
else
b.after = a;
// 如果当前结点的下一个结点为 Null 的话就说明当前结点本来就是 tail 结点
// 需要将其前一个结点设置为 tail 结点
if (a == null)
tail = b;
// 否则的话 e 的下一个结点指向 e 的上一个结点相当于彻底的删除了 e
else
a.before = b;
}
复制代码
这段代码就是链表的结点的删除操作,断开一个结点后
- 连接前后结点
- 删除当前结点
- 考虑结点所处的位置做特殊处理(首部,尾部)
- 只有一个数据的处理情况
获取数据
/**
* 获取数据
* @param key
* @return
*/
public V get(Object key) {
Node<K,V> e;
// 通过 HashMap 的 getNode() 方法获取对应的结点
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果需要按照访问顺序排序
if (accessOrder)
// 调整结点位置实现按照访问顺序排序
// 将当前结点放到最后
afterNodeAccess(e);
return e.value;
}
复制代码
这段代码的功能就是去调用 HashMap 的 getNode 获取结点数据,如果需要按照访问顺序排序的话就会调用 afterNodeAccess 来设置数据的顺序
fail-fast
fail-fast 快速失败策略,指的是如果在遍历访问数据的时候,有其它线程修改了当前的 map 那么久会抛出 ConcurrentModificationException,我们挑选一个 key 的遍历访问来看(LinkedValues 等等都是一样的)
final class LinkedKeySet extends AbstractSet<K> {
// 几个基础访问很简单就是调用外层访问来实现对应的功能
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
// 可以通过迭代器进行迭代访问所有的 key
public final void forEach(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
// 从 head 开始遍历
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key);
// 如果访问的时候发现 LinkedHashMap 被修改了抛错 ConcurrentModificationException
// 也就是 fail-fast
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
复制代码
可以看到主要就是通过 modCount 这个字段保证的,在讲述 put 等源码分析的时候,都可以看到成功后有一个 modCount++ 的操作,假设我们在 T1 时刻调用了 forEach 方法,发现 modCount = 5,我们进行遍历的时候发现这个数据变了那么久会抛出异常
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

