Java SE基础巩固(八):序列化
在数据处理中,将数据结构或者对象转换成其他可用的格式,并做持久化存储或者将其发送到网络流中,这种行为就是序列化,反序列化则是与之相反。
现如今流行的微服务,服务之间相互使用RPC或者HTTP进行通信,当一发发送的消息是对象的时候,就需要对其进行序列化,否则接收方可能无法识别(微服务架构下,各个服务使用的语言是可以不一样的),当接受方接受消息的时候就按照一定的协议反序列化成系统可识别的数据结构。
现在Java序列化的方式主要有两种:一种是Java原生的序列化,会将Java对象转换成字节流,但这种方式会有危险,后面会说到,另一种是使用第三方结构化数据结构,例如JSON和Google Protobuf,下面我将简单介绍一下这两种方式。
1 Java原生序列化
这种方式序列化的对象所属的类必须实现了Serializable接口,该接口只是一个标记接口,没有任何抽象方法,所以实现该接口的时候不需要重写任何方法。要对Java对象做序列化,需要使用java.io.ObjectOutputStream类,它有一个writeObject方法,其参数是需要序列化的对象,要对Java对象做反序列化,需要使用java.io.ObjectInputStream类,他有一个readObject()方法,其没有参数。下面是一个对Java对象进行序列化和反序列化的示例:
ObjectOutputStream和ObjectInputStream都是BIO中面向字节流体系下的类,所以从这里可以推断出Java原生的序列化是面向字节流的。
public class User {
private Long id;
private String username;
private String password;
//setter and getter
}
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
String fileName = "E://Java_project//effective-java//src//top//yeonon//serializable//origin//user.txt";
User user = new User();
user.setId(1L);
user.setUsername("yeonon");
user.setPassword("yeonon");
//序列化
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(fileName));
out.writeObject(user); //写入
out.flush(); //刷新缓冲区
out.close();
//反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(fileName));
User newUser = (User) in.readObject();
in.close();
//比较两个对象
System.out.println(user);
System.out.println(newUser);
System.out.println(newUser.equals(user));
}
}
复制代码
代码使用了ObjectOutputStream和ObjectInputStream进行序列化和反序列化,代码非常简单,就不多说了。直接运行这个程序,应该会得到一个java.io.NotSerializableException异常,什么原因呢?因为User类没有实现Serializable接口,咱给他加上,如下所示:
public class User implements Serializable {
private Long id;
private String username;
private String password;
}
复制代码
现在再次运行程序,输出大概如下:
top.yeonon.serializable.User@61bbe9ba top.yeonon.serializable.User@4e50df2e false 复制代码
第一行输出是序列化之前的对象,第二行输出是经过序列化和反序列化之后的对象,从编号上来看,这两个对象是不同的,第三行是使用equals方法比较两个对象,输出是false?为什么,这两个对象即使不同,用equals方法比较应该返回true啊,因为他们的状态字段都是一样的?这其实是equals方法的问题,我们的User类没有重写euqals方法,所以使用的是Object类的equals方法,Object的equals方法只是简单的比较两者引用是否相同而已,如下所示:
public boolean equals(Object obj) {
return (this == obj);
}
复制代码
所以结果会返回false,但如果我们在User类里重写了equals方法,就可以有机会让euqlas方法返回true,关于如何正确实现euqals方法,就不是本文讨论的内容了,推荐看看《Effective Java》第三版Object主题的相关章节。
这就完成了一次序列化和反序列化操作,同时还在目录下创建了一个user.txt文件,该文件时一个二进制文件,里面的内容是虚拟机可识别的字节码,我们可以把这个文件传到另一台电脑上,如果那台电脑的JVM和这边电脑的一样,那么就可以直接使用ObjectInputStream读取并反序列这个对象了(还有一个前提是那边电脑的java程序里存在User类)。
介绍完Java原生的序列化和反序列化,接下来将介绍基于第三方结构化数据结构的序列化和反序列化,主要介绍两种格式:JSON和Google Protobuf。
2 JSON序列化和反序列化
JSON即 JavaScript Object Notation,是一种轻量级的数据交换语言,JSON的设计初衷是为了JavaScript服务的,广泛应用在Web领域,但现在JSON已经不仅仅用于JS和Web环境了,而变成一种独立于语言的结构化数据格式,而且JSON是基于文本的,其内容有极高的可读性,人类可以简单理解。
2.1 序列化和反序列化纯对象
下面我们使用java的一个第三方库jackson来演示如何将Java对象转换成JSON以及将JSON转换成Java对象:
public class Main {
//ObjectMapper对象,jackson中所有的操作都需要通过该对象
private static final ObjectMapper objectMapper = new ObjectMapper();
public static void main(String[] args) throws IOException {
User user = new User();
user.setId(1L);
user.setUsername("yeonon");
user.setPassword("yeonon");
//序列化成json字符串
String jsonStr = objectMapper.writeValueAsString(user);
System.out.println(jsonStr);
//反序列化成Java对象
User newUser = objectMapper.readValue(jsonStr, User.class);
System.out.println(newUser);
System.out.println(user);
System.out.println(newUser.equals(user));
}
}
复制代码
首先是创建一个ObjectMapper对象,jackson中所有的操作都需要通过该对象。然后调用writeValueAsString(Object)方法将对象转换成String字符串的形式,即序列化,通过readValue(String, Class<?>)方法将JSON字符串转换成Java对象,即反序列化。输出大致如下所示:
{"id":1,"username":"yeonon","password":"yeonon"}
top.yeonon.serializable.User@675d3402
top.yeonon.serializable.User@51565ec2
false
复制代码
需要注意的是第一行输出,这就是JSON格式的字符表示,关于JSON的语法、格式等建议网上查找资料学习,非常简单。另外三行和之前一样,之前都解释过,再次就不再解释了。
2.2 序列化和反序列化集合对象
Jackson的功能非常丰富、强大,不仅仅能序列化user这种纯对象,还可以序列化集合,只不过反序列化的时候麻烦一些而已(但仍然比较简单),如下所示:
public class Main {
//ObjectMapper对象,jackson中所有的操作都需要通过该对象
private static final ObjectMapper objectMapper = new ObjectMapper();
public static void main(String[] args) throws IOException {
User user1 = new User(1L, "yeonon", "yeonon");
User user2 = new User(2L, "weiyanyu", "weiyanyu");
User user3 = new User(3L, "xiangjinwei", "xiangjinwei");
Map<Long, User> map = new HashMap<>();
map.put(1L, user1);
map.put(2L, user2);
map.put(3L, user3);
//序列化集合
String jsonStr = objectMapper
.writerWithDefaultPrettyPrinter()
.writeValueAsString(map);
System.out.println(jsonStr);
//反序列化集合
JavaType javaType = objectMapper
.getTypeFactory()
.constructParametricType(Map.class, Long.class, User.class);
Map<Long, User> newMap = objectMapper.readValue(jsonStr, javaType);
newMap.forEach((k, v) -> {
System.out.println(v);
});
}
}
复制代码
序列化和之前一样,只不过这里使用了writerWithDefaultPrettyPrinter来将输出变得更加Pretty(漂亮)一些(建议不要在生产环境使用这个,因为这个占用的空间会比较多,不如原始的紧凑)。关键在反序列化那,如果还像之前一样直接调用 objectMapper.readValue(jsonStr, Map.class);会发现结果虽然是一个Map,但是里面包含的元素键和值却不是Long和User类型,而是String类型的建和List类型的的值,这显然不是我们想要的结果。
所以,对于集合,需要做更多额外的处理,首先产生一个JavaType对象,该对象表示将几种类型集合在一起组成一个新的类型,constructParametricType()方法接受两个参数,第一个参数是rawType,即原始类型,在代码中即Map,之后的表示集合里的元素类类型,因为Map有两种元素类型,所以传入两种类型,分别是Long和User,最后调用readValue()的另一个重载形式将字符串和javaType传入即可,此时便完成了反序列化的操作。
运行程序,输出结果大致如下所示:
{
"1" : {
"id" : 1,
"username" : "yeonon",
"password" : "yeonon"
},
"2" : {
"id" : 2,
"username" : "weiyanyu",
"password" : "weiyanyu"
},
"3" : {
"id" : 3,
"username" : "xiangjinwei",
"password" : "xiangjinwei"
}
}
----------------------------------
User{id=1, username='yeonon', password='yeonon'}
User{id=2, username='weiyanyu', password='weiyanyu'}
User{id=3, username='xiangjinwei', password='xiangjinwei'}
复制代码
Jackson还有很多强大的功能,如果想深入了解,建议自行搜索资料查看学习。下面介绍另一种结构化数据格式:Google Protobuf。
3 Google Protobuf序列化和反序列化
Protobuf是Google推出的序列化工具。它主要有以下几个特点:
- 语言无关、平台无关
- 简洁
- 高性能
- 良好的兼容性
语言、平台无关是因为它是基于某种协议的格式,在序列化和反序列化的时候都需要遵循这种协议,自然就能实现平台无关了。虽然其简洁,但并不易读,它不像JSON、XML等基于文本的格式,而是基于二进制格式的,这也是其高性能的原因,下图是它和其他工具的性能比较:
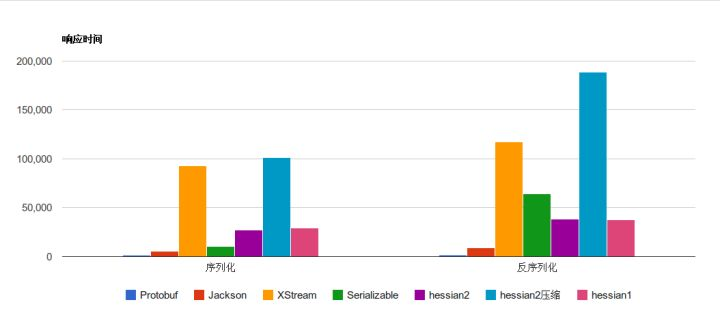
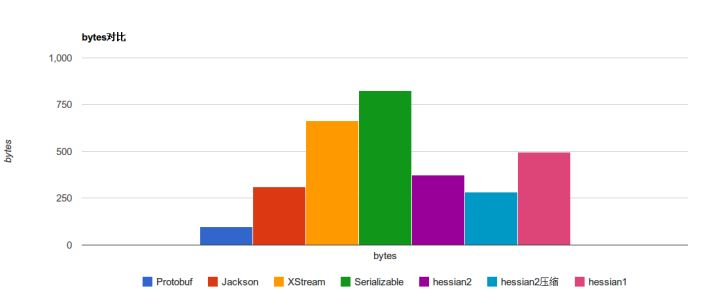
3.1 准备工作
首先,需要到官网下载对应的工具,因为我的电脑操作系统是win,所以下载的是protoc-3.6.1-win32.zip这个文件。下载好之后进入到bin目录,找到protoc.exe,这个玩意儿就是等会我们要用的了。
3.2 编写protobuf 文件
准备工作做好之后,就开始着手编写protobuf文件了,protobuf文件格式非常贴近C++,关于其格式更详细的内容,建议到官网上去查看,官网写得非常清楚,下面是一个示例:
syntax = "proto2";
option java_package = "top.yeonon.serializable.protobuf";
option java_outer_classname = "UserProtobuf";
message User {
required int64 id= 1;
required string name = 2;
required string password = 3;
}
复制代码
简单解释一下吧:
- syntax。即使用哪种语法,proto2表示使用proto2的语法,proto3表示使用proto3的语法。
- java_package可选项。表示java包名。
- java_outer_classname可选项。表示生成的java类名,不设置就默认以文件名的驼峰表示来作为类名。
- message。必须要有的,简单理解为表示类吧,例如代码中的message User就表示要生成一个User类。
- required。不是必须的,表示序列化的时候该字段必须要有值,否则序列化失败。
3.3 生成Java类
此时就要用到protoc.exe这个可执行文件了,执行如下命令:
protoc.exe -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/addressbook.proto 复制代码
SRC_DIR即源文件所在目录,DST_DIR即要将生成的类放在哪个目录下,下面是我的测试用例:
protoc.exe -I=C:/Users/72419/Desktop/ --java_out=E:/Java_project/effective-java/src C:/Users/72419/Desktop/user.proto 复制代码
执行完毕之后,可以在E:/Java_project/effective-java/src目录下看到top目录,从这开始,就是根据之前在protobuf文件里设置的包名继续创建目录了,所以,最终我们会在E:/Java_project/effective-java/src/top/yeonon/serializable/protobuf/目录下看到一个UserProtobuf.java文件,这就是生成的Java类了,但这不是我们真正想要的类,我们真正想要的应该是User类,User类实际上是UserProtobuf类的一个内部类,不能直接实例化,需要通过Buidler类来构建。下面是一个简单的使用示例:
public class Main {
public static void main(String[] args) throws InvalidProtocolBufferException {
UserProtobuf.User user = UserProtobuf.User.newBuilder()
.setId(1L)
.setName("yeonon")
.setPassword("yeonnon").build();
System.out.println(user);
//序列化成字节流
byte[] userBytes = user.toByteArray();
//反序列化
UserProtobuf.User newUser = UserProtobuf.User.parseFrom(userBytes);
System.out.println(user);
System.out.println(newUser);
System.out.println(newUser.equals(user));
}
}
复制代码
首先使用相关的Builder来构建对象,然后通过toByteArray生成字节流,此时就可以将这个字节流进行网络传输或者持久化了。反序列化也非常简单,调用parseFrom()方法即可。运行程序,输出大致如下:
id: 1 name: "yeonon" password: "yeonnon" true 复制代码
发现这里返回的是true,和上面的都不一样,为什么呢?因为工具再生成该User类的时候,还顺便重写了equals方法,该euals方法会比较两个对象的字段值,这里字段值啥的肯定是一样的,所以最终会返回true。
以上就是Protobuf的简单使用了,实际上Protobuf远不止这些功能,还有很多强大的功能,由于我自己也是“现学现卖”,所以就不献丑了,建议网上搜索资料进行深层次的学习。
4 序列化和单例模式
单例模式的最基本要求是整个应用程序中都只存在一个实例,无论哪种实现方法,都是围绕整个目的来做的。而序列化可能会破坏单例模式,更准确的说是反序列化会破坏单例。为什么呢?其实从上面的介绍中,已经大概知道原因了,我们发现反序列化之后的对象和原对象并不是同一个对象,即整个系统中存在某个类的不止一个实例,显然破坏了单例,这也是为什么Enum类(Enum都是单例的)的readObject方法实现是直接抛出异常(在关于枚举的那篇文章中有提到)。所以,如果要保持单例,最好不要允许其进行序列化和反序列化。
5 为什么序列化是危险的
之所以要进行序列化,是因为要将对象进行持久化存储或者进行网络传输,这样会导致系统失去对对象的控制权。例如,现在要将user对象进行序列化并通过网络传输给其他系统,如果在网络传输过程中,序列化的字节流被篡改了,而且没有破坏其结构,那么接受方反序列化的内容可能就和发送方发送的内容不一致,严重的可能会导致接收方系统崩溃。
又或者是系统接收了不知道来源的字节流,并将其反序列化,假设此时没有遭到网络攻击,即字节流没有被篡改,但反序列化的时间非常长,甚至会导致OOM或者StackOverFlow。例如如果发送放发送的是一种深层次的Map结构(即Map里内嵌了Map),假设有n层吧,那么接收方为了反序列化成java对象,就不得不一层一层解开,时间复杂度会是2的n次方,即指数级别的时间复杂度,机器很可能永远无法执行完毕,还有极大可能导致StackOverFlow并最终引起整个系统崩溃,很多拒绝服务攻击就是这样干的。值得一提的是,一些结构化的数据结构(例如JSON)可以有效避免这种情况。
6 小结
本文简单介绍了什么是序列化和反序列化,还顺便说了一下JSON和Protobuf的简单使用。序列化和反序列化是有一定危险的,如果不是有必要,要尽量避免,如果不得不使用,那么最好使用一些结构化的数据结构,例如JSON,Protobuf等,这样至少可以规避一种危险(在第5小结中有讲到)。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

