Java面经分类以及总结(1)--必会
1.定义区别:
①重载是指不同的函数使用相同的函数名,但是函数的参数个数或类型不同。调用的时候根据函数的参数来区别不同的函数。
②覆盖(也叫重写)是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。即函数名和参数都一样,只是函数的实现体不一样。
2.类的关系区别
覆盖是子类和父类之间的关系,是垂直关系;重载是同一个类中方法之间的关系,是水平关系。
3.产生方法区别
覆盖只能由一个方法或只能由一对方法产生关系;重载是多个方法之间的关系。
4.参数列表要求区别
覆盖要求参数列表相同;重载要求参数列表不同。
5.调用方法区别
覆盖关系中,调用方法体是根据对象的类型来决定;而重载关系是根据调用时的实参表与形参表来选择方法体的。
2. 子类能够重写父类中声明为 private 的方法吗?protected 方法呢?
private是私有的,其他类是不能访问的,子类也不可以访问,所以你可以重新实现父类的该方法,不会有冲突,但是你重新实现的方法,不叫重写也不叫重载,是一个该子类新增的方法,和子类的一般扩展方法一样
protected修饰符可以应用于类中的数据和方法。公共类中保护的数据或方法可以被它的子类或同一包中的任何类访问,即使子类在不同的包中也可以。
也就是说用protected修饰的方法,在同包的条件下的子类中可以被覆盖,而在不同包下的子类中只能被调用,是不能被覆盖的。
3. 父类中被 final 关键字修饰的方法可以被重写吗
-
final修饰的类,为最终类,该类不能被继承。如String 类
-
final修饰的方法可以被继承和重载,但不能被重写
-
final修饰的变量不能被修改,是个常量
4. 重载是编译时决定的还是运行时决定的?
对于重载(overloaded),调用方法的选择是在编译时确定的,是静态选择的; 而对于覆盖(overridden)方法的选择是动态的,在运行时确定的,选择的依据是被调用方法所在对象的运行时类型。
5. Java Object 类中有哪些方法?
equals:判断两个对象"相等"
hashCode:获取对象的哈希值
toString:把对象转为字符串
getClass:返回运行时的class,这个方法在Object中是个native方法。
以下5个都和多线程有关系。
notify
notifyAll
wait
wait(long timeout)
wait(long timeout, int nanos)
2个protected方法:
clone:
finalize:
1个private方法
registerNatives: 详细不知道是啥
6. 有重写过 hashcode 和 equals 方法吗?重写 equals 方法时需要遵守什么原则?
因为不重写 equals 方法,执行 user1.equals(user2) 比较的就是两个对象的地址(即 user1 == user2),肯定是不相等的
既然比较两个对象是否相等,使用的是 equals 方法,那么只要重写了 equals 方法就好了,干嘛又要重写 hashCode 方法呢?
其实当 equals 方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
-
自反性。对于任何非null的引用值x,x.equals(x)应返回true。
-
对称性。对于任何非null的引用值x与y,当且仅当:y.equals(x)返回true时,x.equals(y)才返回true。
-
传递性。对于任何非null的引用值x、y与z,如果y.equals(x)返回true,y.equals(z)返回true,那么x.equals(z)也应返回true。
-
一致性。对于任何非null的引用值x与y,假设对象上equals比较中的信息没有被修改,则多次调用x.equals(y)始终返回true或者始终返回false。
-
对于任何非空引用值x,x.equal(null)应返回false。
7.MySQL 默认的隔离级别
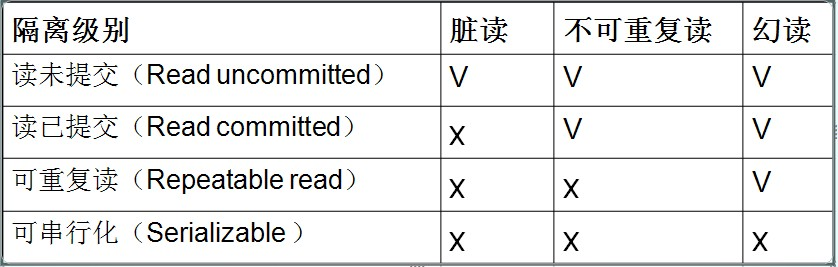
(1)所有事务都可以看到其他未提交事务的执行结果 (2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少 (3)该级别引发的问题是——**脏读(Dirty Read):读取到了未提交的数据** 复制代码
第2级别:Read Committed(读取提交内容)
(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的) (2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变 (3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。 |——>导致这种情况的原因可能有: (1)有一个交叉的事务有新的commit,导致了数据的改变; (2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit 复制代码
第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别 (2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行 (3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行 (4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题 复制代码
第4级别:Serializable(可串行化)
(1)这是最高的隔离级别 (2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。 (3)在这个级别,可能导致大量的超时现象和锁竞争 复制代码
8.Java序列化
- 序列化和反序列化的概念
- 序列化:把对象 转换为字节序列 的过程称为对象的序列化。
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
在代码运行的时候,我们可以看到很多的对象(debug过的都造吧), 可以是一个,也可以是一类对象的集合,很多的对象数据,这些数据中, 有些信息我们想让他持久的保存起来,那么这个序列化。 就是把内存里面的这些对象给变成一连串的字节描述的过程。 常见的就是变成文件 我不序列化也可以保存文件啥的呀,有什么影响呢?我也是这么问的。
- 什么情况下需要序列化
- 当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
- 当你想用套接字在网络上传送对象的时候;
- 当你想通过RMI传输对象的时候; (老实说,上面的几种,我可能就用过个存数据库的)
- 如何实现序列化
实现Serializable接口即可
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

