人人都想学架构(三)
本文是《从0开始学架构》专栏学习的第三篇,第四节和第五节分别说了存储高性能和计算高性能。
第四节主要说的是存储高性能,研究的课题就是MySQL这样的关系型数据库,NoSQL,缓存。
(一)MySQL
对于关系型数据库来说,比较熟悉的就是MySQL,如果将所有的读取压力全部放在单一的节点上,那肯定是慢的,所以我们可以基于主从和主备的机制进行 读写分离 。
理论上主备中的备是做数据冷备的,不提供在线访问;而主从的从才真正用于读写分离,分担主的压力;在实践中,主备的备也用于线上服务,所以主从和主备可以认为是一样的,主用于数据更新,从(备)用于查询,这样能够提高查询性能。
可主从和主备肯定会遇到同步延迟的问题,延迟一方面是MySQL同步机制导致的,另外是数据应用不当造成的,根据 我的经验 ,大部分延迟是因为在数据库上做了大量复杂SQL的查询。
如果确实出现延迟,那么应用就要有一些策略,比如:
-
写操作后,特定时间内查询主库,比较难控制,代码会显得很难看。
-
二次读取,现实中很难实施,因为你怎么知道副库延迟了?
如果确定知道延迟了,那么二次可以读取主库。
-
关键业务读取主库,非关键业务采取读写分离。
第二个优化MySQL存储性能的方法就是 分库分表 ,读写分离分散了读写操作的压力,但没有分散存储压力,尤其数据量超大的时候,查询性能就会低下了,解决方法就是拆分。
分库一般是基于业务来分,但这样也不一定解决问题,比如某个业务即使分库后,单库存储量还是非常大,这时候就要选择分表了,分表分为垂直发表和水平分表。
比如新浪博客的博文表垂直分为索引表和内容表,索引表和内容表结合起来才是博文数据,考虑到内容字段非常大,所以垂直拆分是合适的,因为索引表变得非常小,而它的查询频率很高,相应查询性能就比较高了。
就算垂直分表后,单表的记录可能还是会非常大,这时候就要水平分表了,比如某个人的博文数据在一张表,另外个人的博文数据在另外一张表。
水平分表比垂直分表引入更多的复杂性,主要就是路由策略,可以采取Hash路由的方式,也可以采用路由表的方式,Hash路由相对还是很均衡的,但如果将来要再拆分,就要重新导入导出数据了;而路由表的方式除了影响性能,本身还可能遇到瓶颈和可用性问题,优势是将来再拆分就比较方便了。就 我的经验 ,还是采用Hash路由方式更简单,另外也不要迷信分库分表,MySQL的性能其实没有那么脆弱。
分库分表劣势在于将同一份数据拆成多份了,这样就无法使用很多SQL功能,比如join,count,order by等SQL就用不了了,事务也完成不了了,只能采取和分布式系统一样的事务解决方案了。
读写分离、路由策略、负载均衡、连接池,很多中间件支持这些功能,但不知道有没有大型公司使用,引入中间件可能会带来新问题,数据库中间件可能能锦上添花,但优秀的MySQL管理机制不一定要通过中间件来完成,规约也是很好的方式。
(二)NoSQL
除了MySQL外,现在流行的还有NoSQL系统,MySQL和NoSQL本质上是完全不同的模型,所以最好不要强行比较,双方各有自己的应用场景,应该互相补充。
NoSQL系统对于理解分布式系统非常有好处,有很多类型的软件,这个专栏也是点到为止,我建议找其他资料进一步学习,如果是初学,可以了解下不同NoSQL系统适用的场景。
选型NoSQL和Mysql的时候,考虑几个指标,数据量、并发量、实时性、一致性要求、读写分布和类型、安全性、运维性等,根据这些指标分为:
-
管理型系统,如运营类系统,首选关系型。
-
大流量系统,如电商单品页的某个服务,后台选关系型,前台选内存型。
-
日志型系统,原始数据选列式,日志搜索选倒排索引。
-
搜索型系统,指站内搜索,非通用搜索,如商品搜索,后台选关系型,前台选倒排索引。
-
事务型系统,如库存、交易、记账,选关系型+缓存+一致性协议,或新型关系数据库。
-
离线计算,如大量数据分析,首选列式,关系型也可以。
-
实时计算,如实时监控,可以选时序数据库,或列式数据库。
从上面看出,Nosql主要分为四种:
-
K-V 存储:
解决关系数据库无法存储数据结构的问题,以 Redis 为代表。
-
文档数据库:
解决关系数据库强 schema 约束的问题,以 MongoDB 为代表。
-
列式数据库:
解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表。
-
全文搜索引擎:
解决关系数据库的全文搜索性能问题,以 Elasticsearch 为代表。
除了HBase以外,其他几种软件都是我要继续加强的。
(三)缓存
缓存无处不在,浏览器缓存,页面缓存,数据缓存,边缘缓存,虚拟内存,寄存器Cache,此处重点介绍数据缓存。
数据缓存原理很简单,选择软件也很简单,作用就是缓解后端压力(一次生成,多次使用),复合结果存储到缓存中(避免复杂运算)。
缓存本身不复杂, 我的经验 是根据业务选择缓存策略,思考该不该缓存,已经使用缓存可能带来的问题。
缓存穿透表示缓存没有发生作用,第一种情况是后端数据即使为空,缓存中也应该设置一个标志位,否则缓存以为没有缓存数据,每次都会重新查询后端。第二种情况没太看明白,意思是一些业务即使使用缓存,但在查询的时候缓存基本上是失效的,还是会查询后端,比如爬虫分页,这种情况即使有缓存设计,但也没有什么用,还多浪费了一次缓存查询,在业务上,如果设计不好或遇到爬虫遍历就会出现这种问题,命中率极低,而且还没有太好的解决方法。 我的经验 ,分页一般第一页使用缓存就可以了。
缓存雪崩表示缓存失效后(比如过期时间一致或某个缓存服务器重启了),多个进程可能会同时更新一个缓存,导致对后端的频繁访问。解决方案是使用分布式锁或后台更新(定时读取,队列通知)。
缓存热点,比如缓存服务器有十个节点,但由于热点集中在一个节点上,这样可能90%的请求落在这个节点上,导致极大的负载,可以通过冗余多份相同数据的节点解决该问题。
我的经验是仔细了解自己的业务,根据缓存软件的特性择决,选择合适的策略去解决业务,这一块其实有很多技巧,但是显得不是那么正规。
第五节介绍了如何让Web服务器性能更好,在单机性能达到极致后,还可以采用集群方案。
(一)单机高性能
1:PPC(Process per Connection)
主进程接收到一个连接后,fork出一个子进程处理请求,一个疑问(子进程响应的时候还要经过主进程吗?),除了fork代价高的问题,主进程和子进程可能还要进行IPC通信。
2:prefork
提前预生成子进程,由子进程accept新连接,Apache prefork采取的就是这种形式,这种方式解决了PPC fork带来的损耗。
3:TPC(Thread per Connection)
创建一个线程处理新连接,线程比进程更轻量,但会存在互斥和共享的问题,可能会出现死锁问题,另外一个线程出现问题可能会导致其他线程退出,稳定性需要注意。
4:prethread
和TPC相比,会预先创建线程池,由线程accept新连接,Apache MPM wokrer模式就是采用多进程和多线程的模型。
上述几种机制理解起来比较简单,不足在于处理大规模的请求,性能会极具下降,我会专门写一篇文章介绍Apache三种I/O处理机制。
5:Reactor
上述几种机制,不管是子进程还是子线程,它们同时只能处理一个连接,因为进程会阻塞在某个连接的read操作上,这样即使其他连接有数据可读,进程也无法处理。
可以将read改为非阻塞操作,然后轮询连接,查看数据是否就绪,不过这种处理方式不优雅。
更好的解决方案就是I/O异步多路复用:
-
当多条连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,而无须再轮询所有连接,常见的实现方式有 select、epoll、kqueue 等(操作系统支持的)。
-
当某条连接有新的数据可以处理时, 操作系统会通知进程 ,进程从阻塞状态返回,开始进行业务处理。
这个多路复用的“多路”代表多个连接,“复用”代表多个连接复用一个阻塞对象,这个阻塞对象和具体的实现有关。
多路复用也叫Reactor或Dispatcher(I/O多路复用统一监听事件,收到事件后分配给某个进程)。
Reactor 模式的核心组成部分包括 Reactor 和处理资源池(进程池或线程池),其中 Reactor 负责监听和分配事件,处理资源池负责处理事件。
Reactor模式的具体实现方案:
-
Reactor 的数量可以变化:
可以是一个 Reactor,也可以是多个 Reactor。
-
资源池的数量可以变化:
以进程为例,可以是单个进程,也可以是多个进程(线程类似)。
(1)单进程/线程,单Reactor模型
整个结构就是单进程单线程,所以一般是一个Reactor,如下图:
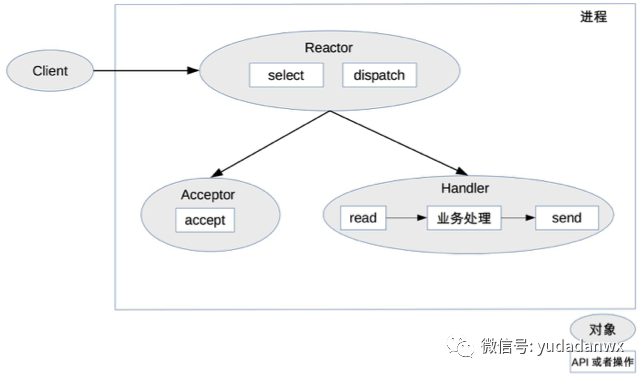 缺点就是单个Handler在处理某个连接上的业务时,整个进程无法处理其他连接的事件,很容易导致性能瓶颈(改为非阻塞I/O不就可以了吗?这里不是很明白)。
缺点就是单个Handler在处理某个连接上的业务时,整个进程无法处理其他连接的事件,很容易导致性能瓶颈(改为非阻塞I/O不就可以了吗?这里不是很明白)。
Redis就是采用这种模型,Redis大部分是内存操作,所以不会阻塞Handler。
(2)多线程,单Reactor模型
这是为了弥补上面这种模型缺点而来的,具体的业务由子线程单独处理,然后将结果发送给Handler处理(read和send),不过请求量很多的时候,单Reactor模型处理所有事件的监听和响应,可能会出现瓶颈。

(3)多进程/多线程,多Reactor模型
多进程或多线程有多个Reactor,然后每个进程或线程处理监听,具体的任务交给每个进程或线程的Handler处理。Nginx和Memcached就是采用这样的模型。
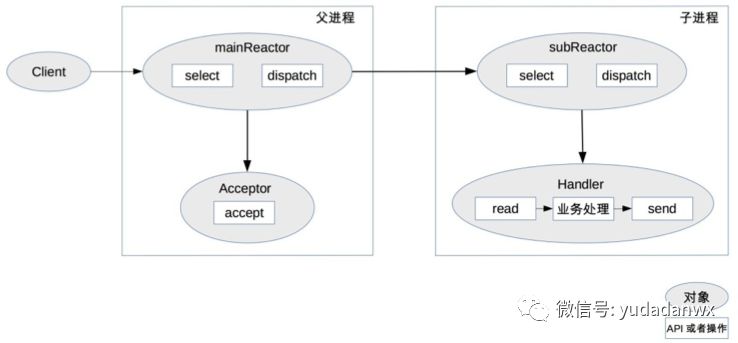
说明,以上我理解的不是很透彻,后续要结合代码实现进一步实现。
(二)集群高性能
这个比较简单,使用负载均衡就可以分配任务,从而提高性能。
主要包含:
-
DNS负载均衡:
一般用于地理级别的负载均衡。
-
四层负载均衡:
一般是硬件或内核级别的,比如LVS,用于集群级别的负载均衡,比如下面挂七层负载均衡设备。
-
七层负载均衡:
一般挂在四层负载均衡设备下面,比如Nginx,用于机器级别的负载均衡。
关于负载均衡其实重点掌握网络协议,另外负载均衡算法分为:
-
轮询,加权轮询
-
Hash
-
负载,性能最优算法
如果你想购买这个专栏,可以扫描下面的二维码,这样会有返现。

正文到此结束
- 本文标签: 搜索引擎 http id 集群方案 索引 web Select 同步 sql queue 模型 代码 并发 db 解决方法 压力 运营 虚拟内存 redis 分布式锁 apache 遍历 负载均衡 HBase 线程池 分布式系统 多线程 Reactor 协议 分页 进程 src 数据 IO mongo mysql MongoDB DNS 性能问题 安全 文章 Elasticsearch 管理 缓存 服务器 软件 线程 schema UI 数据缓存 本质 CTO https 锁 集群 博客 分布式 大数据 连接池 Nginx 二维码 数据库 Connection NOSQL cache 一致性 时间 ip 操作系统
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

