使用Stream API优化代码
Java8的新特性主要是Lambda表达式和流,当流和Lambda表达式结合起来一起使用时,因为流申明式处理数据集合的特点,可以让代码变得简洁易读
放大招,流如何简化代码
如果有一个需求,需要对数据库查询到的菜肴进行一个处理:
- 筛选出卡路里小于400的菜肴
- 对筛选出的菜肴进行一个排序
- 获取排序后菜肴的名字
菜肴:Dish.java
public class Dish {
private String name;
private boolean vegetarian;
private int calories;
private Type type;
// getter and setter
}
复制代码
Java8以前的实现方式
private List<String> beforeJava7(List<Dish> dishList) {
List<Dish> lowCaloricDishes = new ArrayList<>();
//1.筛选出卡路里小于400的菜肴
for (Dish dish : dishList) {
if (dish.getCalories() < 400) {
lowCaloricDishes.add(dish);
}
}
//2.对筛选出的菜肴进行排序
Collections.sort(lowCaloricDishes, new Comparator<Dish>() {
@Override
public int compare(Dish o1, Dish o2) {
return Integer.compare(o1.getCalories(), o2.getCalories());
}
});
//3.获取排序后菜肴的名字
List<String> lowCaloricDishesName = new ArrayList<>();
for (Dish d : lowCaloricDishes) {
lowCaloricDishesName.add(d.getName());
}
return lowCaloricDishesName;
}
复制代码
Java8之后的实现方式
private List<String> afterJava8(List<Dish> dishList) {
return dishList.stream()
.filter(d -> d.getCalories() < 400) //筛选出卡路里小于400的菜肴
.sorted(comparing(Dish::getCalories)) //根据卡路里进行排序
.map(Dish::getName) //提取菜肴名称
.collect(Collectors.toList()); //转换为List
}
复制代码
不拖泥带水,一气呵成,原来需要写 24 代码实现的功能现在只需 5 行就可以完成了

高高兴兴写完需求这时候又有新需求了,新需求如下:
- 对数据库查询到的菜肴根据菜肴种类进行分类,返回一个
Map<Type, List<Dish>>的结果
这要是放在jdk8之前肯定会头皮发麻
Java8以前的实现方式
private static Map<Type, List<Dish>> beforeJdk8(List<Dish> dishList) {
Map<Type, List<Dish>> result = new HashMap<>();
for (Dish dish : dishList) {
//不存在则初始化
if (result.get(dish.getType())==null) {
List<Dish> dishes = new ArrayList<>();
dishes.add(dish);
result.put(dish.getType(), dishes);
} else {
//存在则追加
result.get(dish.getType()).add(dish);
}
}
return result;
}
复制代码
还好jdk8有Stream,再也不用担心复杂集合处理需求
Java8以后的实现方式
private static Map<Type, List<Dish>> afterJdk8(List<Dish> dishList) {
return dishList.stream().collect(groupingBy(Dish::getType));
}
复制代码
又是一行代码解决了需求,忍不住大喊 Stream API 牛批 看到流的强大功能了吧,接下来将详细介绍流

什么是流
流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算
如何生成流
生成流的方式主要有五种
- 通过集合生成,应用中最常用的一种
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); Stream<Integer> stream = integerList.stream(); 复制代码
通过集合的 stream 方法生成流
- 通过数组生成
int[] intArr = new int[]{1, 2, 3, 4, 5}; IntStream stream = Arrays.stream(intArr); 复制代码
通过 Arrays.stream 方法生成流,并且该方法生成的流是数值流【即 IntStream 】而不是 Stream<Integer> 。补充一点使用数值流可以避免计算过程中拆箱装箱,提高性能。 Stream API 提供了 mapToInt 、 mapToDouble 、 mapToLong 三种方式将对象流【即 Stream<T> 】转换成对应的数值流,同时提供了 boxed 方法将数值流转换为对象流
- 通过值生成
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); 复制代码
通过 Stream 的 of 方法生成流,通过 Stream 的 empty 方法可以生成一个空流
- 通过文件生成
Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset()) 复制代码
通过 Files.line 方法得到一个流,并且得到的每个流是给定文件中的一行
- 通过函数生成 提供了
iterate和generate两个静态方法从函数中生成流- iterator
Stream<Integer> stream = Stream.iterate(0, n -> n + 2).limit(5); 复制代码
iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断,只生成5个偶数- generator
Stream<Double> stream = Stream.generate(Math::random).limit(5); 复制代码
generate方法接受一个参数,方法参数类型为Supplier<T>,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断
流的操作类型
流的操作类型主要分为两种
- 中间操作 一个流可以后面跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的,仅仅调用到这类方法,并没有真正开始流的遍历,真正的遍历需等到终端操作时,常见的中间操作有下面即将介绍的
filter、map等 - 终端操作 一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。终端操作的执行,才会真正开始流的遍历。如下面即将介绍的
count、collect等
流使用
流的使用将分为终端操作和中间操作进行介绍
中间操作
filter筛选
List<Integer> integerList = Arrays.asList(1, 1, 2, 3, 4, 5); integerList.stream().filter(i -> i > 3).forEach(System.out::println); 复制代码
通过使用 filter 方法进行条件筛选, filter 的方法参数为一个条件
distinct去除重复元素
List<Integer> integerList = Arrays.asList(1, 1, 2, 3, 4, 5); integerList.stream().distinct().forEach(System.out::println); 复制代码
通过 distinct 方法快速去除重复的元素
limit返回指定流个数
List<Integer> integerList = Arrays.asList(1, 1, 2, 3, 4, 5); integerList.stream().limit(3).forEach(System.out::println); 复制代码
通过 limit 方法指定返回流的个数, limit 的参数值必须 >=0 ,否则将会抛出异常
skip跳过流中的元素
List<Integer> integerList = Arrays.asList(1, 1, 2, 3, 4, 5); integerList.stream().skip(2).forEach(System.out::println); 复制代码
通过 skip 方法跳过流中的元素,上述例子跳过前两个元素,所以打印结果为 2,3,4,5 , skip 的参数值必须 >=0 ,否则将会抛出异常
map流映射
所谓流映射就是将接受的元素映射成另外一个元素
List<String> stringList = Arrays.asList("Java 8", "Lambdas", "In", "Action");
stringList.stream().map(String::length).forEach(System.out::println);
复制代码
通过 map 方法可以完成映射,该例子完成中 String -> Integer 的映射,之前上面的例子通过 map 方法完成了 Dish->String 的映射
flatMap流转换
将一个流中的每个值都转换为另一个流
List<String> stringList = Arrays.asList("Hello", "World");
List<Stream<String>> str = stringList.stream()
.map(world -> world.split(" "))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
复制代码
map(world -> world.split(" ")) 的返回值为 Stream<String[]> ,我们想获得的结果为 Stream<String> ,可以通过 flatMap 方法完成 Stream<String[]> ->Stream<String> 的转换
元素匹配
提供了三种匹配方式
- allMatch匹配所有
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); if (integerList.stream().allMatch(i -> i > 3)) { System.out.println("值都大于3"); } 复制代码
通过 allMatch 方法实现
- anyMatch匹配其中一个
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); if (integerList.stream().anyMatch(i -> i > 3)) { System.out.println("存在大于3的值"); } 复制代码等同于for (Integer i : integerList) { if (i > 3) { System.out.println("存在大于3的值"); break; } } 复制代码
存在大于3的值则打印, java8 中通过 anyMatch 方法实现这个功能
- noneMatch全部不匹配
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); if (integerList.stream().noneMatch(i -> i > 3)) { System.out.println("值都小于3"); } 复制代码通过noneMatch方法实现
终端操作
统计流中元素个数
- 通过count
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); Long result = integerList.stream().count(); 复制代码
通过使用 count 方法统计出流中元素个数
- 通过counting
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); Long result = integerList.stream().collect(counting()); 复制代码
最后一种统计元素个数的方法在与 collect 联合使用的时候特别有用
查找
提供了两种查找方式
-
findFirst查找第一个
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); System.out.println(integerList.stream().filter(i -> i > 3).findFirst()); 复制代码
通过
findFirst方法查找到第一个大于三的元素并打印 -
findAny随机查找一个
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); System.out.println(integerList.stream().filter(i -> i > 3).findAny()); 复制代码
通过
findAny方法查找到其中一个大于三的元素并打印,因为内部进行优化的原因,当找到第一个满足大于三的元素时就结束,该方法结果和findFirst方法结果一样。提供findAny方法是为了更好的利用并行流,findFirst方法在并行上限制更多【本篇文章将不介绍并行流】
reduce将流中的元素组合起来
假设我们对一个集合中的值进行求和
-
jdk8之前
int sum = 0; for (int i : integerList) { sum += i; } 复制代码 -
jdk8之后通过reduce进行处理
int sum = integerList.stream().reduce(0, (a, b) -> (a + b)); 复制代码
一行就可以完成,还可以使用方法引用简写成:
int sum = integerList.stream().reduce(0, Integer::sum); 复制代码
reduce接受两个参数,一个初始值这里是0,一个BinaryOperator<T> accumulator来将两个元素结合起来产生一个新值, 另外reduce方法还有一个没有初始化值的重载方法
获取流中最小最大值
- 通过min/max获取最小最大值
Optional<Integer> min = menu.stream().map(Dish::getCalories).min(Integer::compareTo); Optional<Integer> max = menu.stream().map(Dish::getCalories).max(Integer::compareTo); 复制代码
min获取流中最小值,max获取流中最大值,方法参数为Comparator<? super T> comparator - 通过minBy/maxBy获取最小最大值
Optional<Integer> min = menu.stream().map(Dish::getCalories).collect(minBy(Integer::compareTo)); Optional<Integer> max = menu.stream().map(Dish::getCalories).collect(maxBy(Integer::compareTo)); 复制代码
minBy 获取流中最小值, maxBy 获取流中最大值,方法参数为 Comparator<? super T> comparator
- 通过reduce获取最小最大值
Optional<Integer> min = menu.stream().map(Dish::getCalories).reduce(Integer::min); Optional<Integer> max = menu.stream().map(Dish::getCalories).reduce(Integer::max); 复制代码
比较喜欢最后一种获取最小最大值的方式,简洁明白
通过summingInt求和
int sum = menu.stream().collect(summingInt(Dish::getCalories)); 复制代码
等同于通过 reduce :
int sum2 = menu.stream().map(Dish::getCalories).reduce(0, Integer::sum); 复制代码
更倾向于使用第一种方式,与 reduce 求和相比它更申明式 如果数据类型为 double 、 long ,则通过 summingDouble 、 summingLong 方法进行求和
通过averagingInt求平均值
double average = menu.stream().collect(averagingInt(Dish::getCalories)); 复制代码
如果数据类型为 double 、 long ,则通过 averagingDouble 、 averagingLong 方法进行求平均
通过summarizingInt同时求总和、平均值、最大值、最小值
IntSummaryStatistics intSummaryStatistics = menu.stream().collect(summarizingInt(Dish::getCalories)); double average = intSummaryStatistics.getAverage(); //获取平均值 int min = intSummaryStatistics.getMin(); //获取最小值 int max = intSummaryStatistics.getMax(); //获取最大值 long sum = intSummaryStatistics.getSum(); //获取总和 复制代码
如果数据类型为 double 、 long ,则通过 summarizingDouble 、 summarizingLong 方法
进阶通过groupingBy进行分组
Map<Type, List<Dish>> result = dishList.stream().collect(groupingBy(Dish::getType)); 复制代码
在 collect 方法中传入 groupingBy 进行分组,其中 groupingBy 的方法参数为分类函数。还可以通过嵌套使用 groupingBy 进行多级分类
Map<Type, List<Dish>> result = menu.stream().collect(groupingBy(Dish::getType,
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
})));
复制代码
进阶通过partitioningBy进行分区
分区是特殊的分组,它分类依据是true和false,所以返回的结果最多可以分为两组
Map<Boolean, List<Dish>> result = menu.stream().collect(partitioningBy(Dish :: isVegetarian)) 复制代码
等同于
Map<Boolean, List<Dish>> result = menu.stream().collect(groupingBy(Dish :: isVegetarian)) 复制代码
这个例子可能并不能看出分区和分类的区别,甚至觉得分区根本没有必要,换个明显一点的例子:
List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5); Map<Boolean, List<Integer>> result = integerList.stream().collect(partitioningBy(i -> i < 3)); 复制代码
返回值的键仍然是布尔类型,但是它的分类是根据范围进行分类的,分区比较适合处理根据范围进行分类
通过joining拼接流中的元素
String result = menu.stream().map(Dish::getName).collect(Collectors.joining(", "));
复制代码
默认如果不通过 map 方法进行映射处理拼接的 toString 方法返回的字符串,joining的方法参数为元素的分界符,如果不指定生成的字符串将是一串的,可读性不强
总结
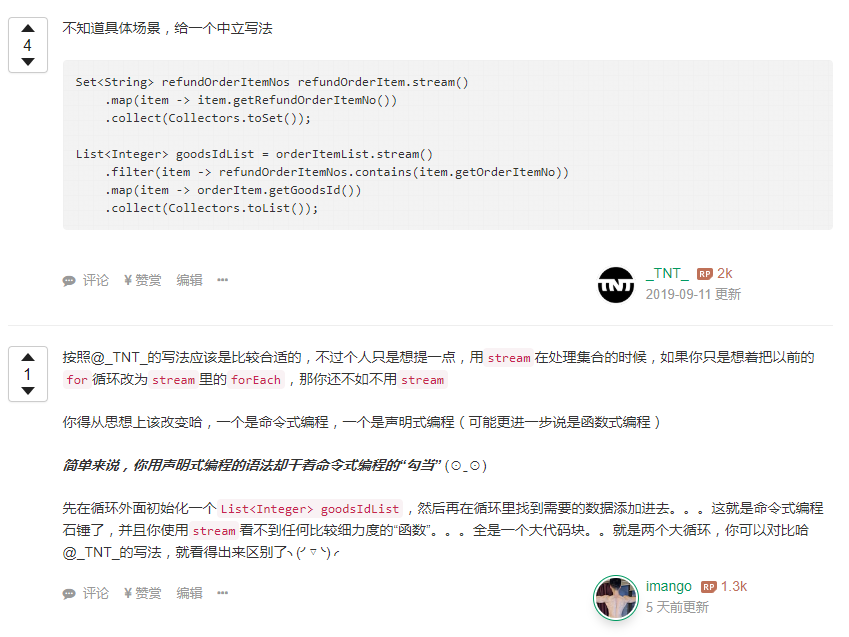
通过使用 Stream API 可以简化代码,同时提高了代码可读性,赶紧在项目里用起来。讲道理在没学 Stream API 之前,谁要是给我在应用里写很多 Lambda , Stream API ,飞起就想给他一脚。我想,我现在可能爱上他了【嘻嘻】。同时使用的时候注意不要将声明式和命令式编程混合使用,前几天刷 segment 刷到一条:

imango 老哥说的很对,
别用声明式编程的语法干命令式编程的勾
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

