浅谈 volatile 实现原理
synchronized 是一个重量级的锁,的 volatile 则是轻量级的 synchronized ,它在多线程开发中保证了共享变量的“可见性”。如果一个变量使用 volatile ,则它比使用 synchronized 的成本更加低,因为它不会引起线程上下文的切换和调度。
Java 编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量。 通俗点讲就是说一个变量如果用 volatile 修饰了,则 Java 可以确保所有线程看到这个变量的值是一致的。如果某个线程对 volatile 修饰的共享变量进行更新,那么其他线程可以立马看到这个更新,这就是所谓的线程可见性。
内存模型相关概念
理解 volatile 其实还是有点儿难度的,它与 Java 的内存模型有关,所以在理解 volatile 之前我们需要先了解有关 Java 内存模型的概念。
操作系统语义
计算机在运行程序时,每条指令都是在CPU中执行的,在执行过程中势必会涉及到数据的读写。我们知道程序运行的数据是存储在主存中,这时就会有一个问题,读写主存中的数据没有 CPU 中执行指令的速度快,如果任何的交互都需要与主存打交道则会大大影响效率,所以就有了 CPU 高速缓存。CPU高速缓存为某个CPU独有,只与在该CPU运行的线程有关。
有了 CPU 高速缓存虽然解决了效率问题,但是它会带来一个新的问题:数据一致性。
在程序运行中,会将运行所需要的数据复制一份到 CPU 高速缓存中,在进行运算时 CPU 不再也主存打交道,而是直接从高速缓存中读写数据,只有当运行结束后,才会将数据刷新到主存中。
举一个简单的例子:
i = i + 1; 复制代码
当线程运行这段代码时,首先会从主存中读取 i 的值( 假设此时 i = 1 ),然后复制一份到 CPU 高速缓存中,然后 CPU 执行 + 1 的操作(此时 i = 2),然后将数据 i = 2 写入到告诉缓存中,最后刷新到主存中。
其实这样做在单线程中是没有问题的,有问题的是在多线程中。如下:
假如有两个线程 A、B 都执行这个操作( i++ ), 复制代码
按照我们正常的逻辑思维主存中的i值应该=3 。
但事实是这样么?分析如下:
两个线程从主存中读取 i 的值( 假设此时 i = 1 ),到各自的高速缓存中, 然后线程 A 执行 +1 操作并将结果写入高速缓存中,最后写入主存中,此时主存 i = 2 。 线程B做同样的操作,主存中的 i 仍然 =2 。所以最终结果为 2 并不是 3 。 这种现象就是缓存一致性问题。 复制代码
解决缓存一致性方案有两种:
通过在总线加 LOCK# 锁的方式 通过缓存一致性协议 复制代码
第一种方案存在一个问题,它是采用一种独占的方式来实现的,即总线加 LOCK# 锁的话,只能有一个 CPU 能够运行,其他 CPU 都得阻塞,效率较为低下。
第二种方案,缓存一致性协议(MESI 协议),它确保每个缓存中使用的共享变量的副本是一致的。其核心思想如下:当某个 CPU 在写数据时,如果发现操作的变量是共享变量,则会通知其他 CPU 告知该变量的缓存行是无效的,因此其他 CPU 在读取该变量时,发现其无效会重新从主存中加载数据。
Java内存模型
上面从操作系统层次阐述了如何保证数据一致性,下面我们来看一下 Java 内存模型,稍微研究一下它为我们提供了哪些保证,以及在 Java 中提供了哪些方法和机制,来让我们在进行多线程编程时能够保证程序执行的正确性。
在并发编程中我们一般都会遇到这三个基本概念:原子性、可见性、有序性。我们看下volatile 。
原子性
原子性:即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
原子性就像数据库里面的事务一样,我们看下面一个简单的例子即可:
i = 0; // <1> j = i ; // <2> i++; // <3> i = j + 1; // <4> 复制代码
上面四个操作,有哪个几个是原子操作,那几个不是?如果不是很理解,可能会认为都是原子性操作,其实只有 1 才是原子操作,其余均不是。
- 在 Java 中,对基本数据类型的变量和赋值操作都是原子性操作。
- 包含了两个操作:读取 i,将 i 值赋值给 j 。
- 包含了三个操作:读取 i 值、i + 1 、将 +1 结果赋值给 i 。
- 同 <3> 一样
那么 64 位的 JDK 环境下,对 64 位数据的读写是否是原子的呢?
实现对普通long与double的读写不要求是原子的(但如果实现为原子操作也OK) 实现对volatile long与volatile double的读写必须是原子的(没有选择余地) 复制代码
另外,volatile 是无法保证复合操作的原子性
可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
在上面已经分析了,在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。
Java提供了 volatile 来保证可见性。
当一个变量被 volatile 修饰后,表示着线程本地内存无效。
当一个线程修改共享变量后他会立即被更新到主内存中;
当其他线程读取共享变量时,它会直接从主内存中读取。
synchronize 和锁都可以保证可见性。
有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。
在 Java 内存模型中,为了效率是允许编译器和处理器对指令进行重排序,当然重排序它不会影响单线程的运行结果,但是对多线程会有影响。
Java 提供 volatile 来保证一定的有序性。最著名的例子就是单例模式里面的 DCL(双重检查锁)。
剖析 volatile 原理
volatile 可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在 JVM 底层,volatile 是采用“内存屏障”来实现的。
上面那段话,有两层语义:
保证可见性、不保证原子性 禁止指令重排序 复制代码
第一层语义就不做介绍了,下面重点介绍指令重排序。
指令重排序
在执行程序时为了提高性能,编译器和处理器通常会对指令做重排序:
编译器重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。 处理器重排序。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。 复制代码
指令重排序对单线程没有什么影响,他不会影响程序的运行结果,但是会影响多线程的正确性。既然指令重排序会影响到多线程执行的正确性,那么我们就需要禁止重排序。那么JVM是如何禁止重排序的呢?
由此引出happen-before原则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作,happens-before 于书写在后面的操作。
- 锁定规则:一个 unLock 操作,happens-before 于后面对同一个锁的 lock 操作。
- volatile 变量规则:对一个volatile变量的写操作,happens-before 于 后面 对这个变量的读操作。注意是后面的.
- 传递规则:如果操作 A happens-before 操作 B,而操作 B happens-before 操作C,则可以得出,操作 A happens-before 操作C
- 线程启动规则:Thread 对象的 start 方法,happens-before 此线程的每个一个动作。
- 线程中断规则:对线程 interrupt 方法的调用,happens-before 被中断线程的代码检测到中断事件的发生。
- 线程终结规则:线程中所有的操作,都 happens-before 线程的终止检测,我们可以通过Thread.join() 方法结束、Thread.isAlive() 的返回值手段,检测到线程已经终止执行。
- 对象终结规则:一个对象的初始化完成,happens-before 它的 finalize() 方法的开始
我们着重看第三点 Volatile规则:对 volatile变量的写操作,happen-before 后续的读操作。
为了实现 volatile 内存语义,JMM会重排序,其规则如下:
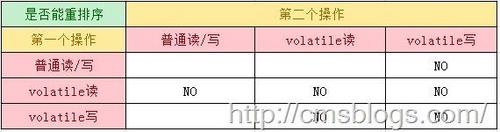
当第二个操作是 volatile 写操作时,不管第一个操作是什么,都不能重排序。 这个规则,确保 volatile 写操作之前的操作,都不会被编译器重排序到 volatile 写操作之后。 复制代码
对 happen-before 原则有了稍微的了解,我们再来回答这个问题 JVM 是如何禁止重排序的?
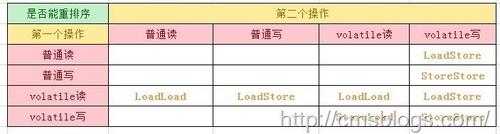
观察加入 volatile 关键字和没有加入 volatile 关键字时所生成的汇编代码发现, 加入volatile 关键字时,会多出一个 lock 前缀指令。 lock 前缀指令,其实就相当于一个内存屏障。 内存屏障是一组处理指令,用来实现对内存操作的顺序限制。 volatile 的底层就是通过内存屏障来实现的。 复制代码
下图是完成上述规则所需要的内存屏障:
总结
volatile 看起来简单,但是要想理解它还是比较难的,这里只是对其进行基本的了解。
volatile 相对于 synchronized 稍微轻量些,在某些场合它可以替代 synchronized ,但是又不能完全取代 synchronized 。只有在某些场合才能够使用 volatile,使用它必须满足如下两个条件:
对变量的写操作,不依赖当前值。 该变量没有包含在具有其他变量的不变式中。 复制代码
volatile 经常用于以下场景:状态标记变量、Double Check .一个线程写多个线程读。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

