JVM体系结构详解
点击蓝色“ 程序猿DD ”关注我
回复“ 资源 ”获取独家整理的学习资料!
作者 | 康仔
来源 | 公众号「锅外的大佬」
每个Java开发人员都知道字节码将由 JRE (Java运行时环境)执行。但是很多人不知道JRE是 Java Virtual Machine (JVM)的实现,它分析字节码、解释代码并执行代码。作为开发者,了解JVM的体系结构非常重要,因为它使我们能够更有效地编写代码。在本文中,我们将更深入地了解Java中的JVM体系结构和JVM的不同组件。
什么是JVM呢?
虚拟机 是物理机的软件实现。 Java是用 WORA(编写一次运行到任何地方) 的概念开发的,它在 VM 上运行。 编译器将Java文件 编译 成Java .class文件,然后将.class文件输入JVM, JVM加载并执行类文件。 下面是JVM的架构图。
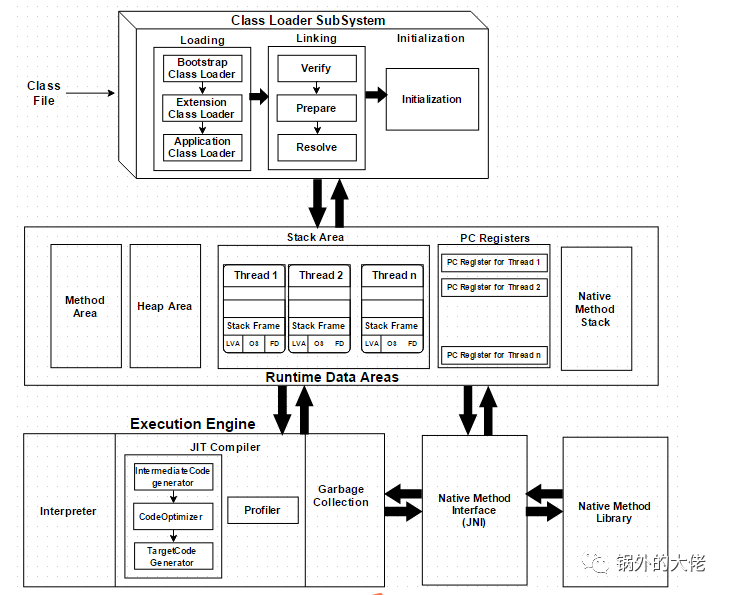
JVM是如何工作的?
如图所示,JVM分为三个主要子系统:
-
类加载器子系统
-
运行时数据区
-
执行引擎
1. 类加载器子系统
Java的动态类加载功能由类加载器子系统处理。 它装载的链接。 在运行时而不是编译时首次引用类时初始化类文件。
1.1 加载
类将由该组件加载。 引导类加载器、扩展类加载器和应用程序类加载器是有助于实现这一目标的三个类加载器。
-
引导类加载器 – 负责从引导类路径加载类,除了 rt.jar 什么也没有。 这个加载程序将获得最高优先级。
-
扩展类加载器– 负责加载ext文件夹**(jre/lib)**中的类。
-
应用程序类加载器–负责加载应用程序级类路径、所述环境变量的路径等。
上述类加载器在加载类文件时将遵循委托层次结构算法。
1.2 链接
-
验证– 字节码验证器将验证生成的字节码是否正确,如果验证失败,我们将得到验证错误。
-
准备– 内存将为所有静态变量分配默认值。
-
解析– 所有符号内存引用将被来自方法区域的原始引用所替换。
1.3 初始化
这是类加载的最后阶段;在这里,所有静态变量都将被赋初始值,并且静态块也会被执行。
2. 运行时数据区
运行时数据区被分为五个主要组件:
-
方法区 – 所有类级数据都将存储在这里,包括静态变量。 每个JVM只有一个方法区,它是资源共享的。
-
堆 –所有对象及其对应的实例变量和数组都将存储在这里。 每个JVM也仅有一个堆。 由于方法区和堆被多个线程共享内存,因此存储的数据不是线程安全的。
-
栈 –每个线程将创建一个单独的运行时栈。 每个方法调用都会在栈内存中生成一个条目,称为栈帧。 所有本地变量都将在栈内存中创建。 栈区域是线程安全的,因为它不是内存共享的。
栈区域被分为三个部分:
-
局部变量数组– 与方法相关,涉及到局部变量以及相应的值都将存储在这里。
-
操作数堆栈–如果需要执行任何中间操作,操作数堆栈充当运行时工作区来执行操作。
-
帧数据 – 所有与方法对应的符号都存储在这里。 在任何 异常 情况下,catch块信息都将保存在帧数据中。
-
PC寄存器– 每个线程将有单独的PC寄存器,以保持当前执行指令的地址一旦指令执行,PC寄存器能顺利地更新到下一条指令。
-
本地方法栈 – 本机方法栈保存着本地方法信息。 对于每个线程,都将创建一个单独的本机方法栈。
3. 执行引擎
被分配给 运行时数据区 的字节码将由执行引擎执行。 执行引擎读取字节码并逐个执行。
-
解释器 – 解释器更快地解释字节码,但执行速度很慢。 解释器的缺点是,当一个方法被多次调用时,每次都需要一个新的解释。
-
JIT编译器
– JIT编译器消除了解释器的缺点。 执行引擎将在转换字节码时使用解释器的帮助,但是当它发现重复的代码时,它使用JIT编译器,JIT编译整个字节码并将其更改为本机代码。 此本机代码将直接用于重复的方法调用,从而提高系统的性能。
-
中间代码生成器– 生成中间代码
-
代码优化器– 负责优化上面生成的中间代码
-
目标代码生成器– 负责生成机器代码或本地代码
-
分析器– 一个特殊的组件,负责寻找热点,即方法是否被多次调用。
-
垃圾收集器 :收集和删除未引用的对象。 可以通过调用
System.gc()触发垃圾收集,但不能保证执行。 JVM的垃圾收集收集创建的对象。
Java本地接口(JNI): JNI将与本地方法库交互,并提供执行引擎所需的本地库。
本机方法库: 这是执行引擎所需的本机库的集合。
-END-
留言交流不过瘾
关注我,回复“ 加群 ” 加入各种主题讨论群

-
JDK13 GA发布:5大特性解读
-
Chrome 开发者工具的各种骚技巧
-
一个MySQL时间戳精度引发的血案
-
ThreadPoolExecutor 的八种拒绝策略 | 含番外!
-
阿里程序员推荐的15 款常用开发者工具

点一点“ 阅读原文 ”小惊喜在等你
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

