Spring -- 定时任务调度的发展
Java领域的调度最早一般认为是 Timer ,接着由 Quratz 创造调度器(Scheduler)、任务(Job)和触发器(Trigger)三个核心概念后开始发展,接着在JDK1.5时 ScheduledThreadPoolExecutor 出现,逐渐成为主流的单机定时调度方式,Spring的定时任务底层适配了 Quratz 以及 ScheduledThreadPoolExecutor ,提供更加方便的使用形式,并没有提供新的调度器实现,再接着发展则是抽离出来 任务触发部分 ,独立集群部署,以应对数以万计的定时任务,即以 Elastic-job , xxl-job 等为代表的分布式调度平台。本文主要描述单机调度与分布式调度的常见实现原理,由于平台众多,如有错误还请指出。
Timer调度
Timer 虽然古老,但是调度该有的东西基本都有,因此仍然值得一说。其使用如下所示, TimerTask 为Job,提交一个job,即提交到执行队列(最小堆)中一个任务, Timer 本身是Scheduler,也是Trigger,其内部持有一个线程,该线程会循环扫描任务优先级队列,发现可执行任务则执行,未发现或任务未到时间则等待下去。
清单1: Timer调度示例
// 相当于创建一个调度器
Timer timer = new Timer();
// 提交一个job任务
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println(111);
}
}, 2000L);
至于内部优先级队列实现,以及任务循环实现与 ScheduledThreadPoolExecutor 类似,因此在下面 ScheduledThreadPoolExecutor 中详细说明。
ScheduledThreadPoolExecutor调度
Timer 的缺陷是单线程执行,一个任务阻塞就会导致后续任务延迟, ScheduledThreadPoolExecutor 简单来说为多线程版的 Timer ,除此之外还提供了任务隔离,异常处理等功能。
ScheduledThreadPoolExecutor 为 ThreadPoolExecutor 的子类,本质上执行流程仍是线程池的那一套逻辑,核心在于 BlockingQueue 的实现类 DelayedWorkQueue 。 DelayedWorkQueue 在数据结构上和Timer保持一致,为小根堆,根节点为当前要执行的任务,每次线程去获取根节点即可拿到最近需要执行的任务。
清单2:小根堆示意
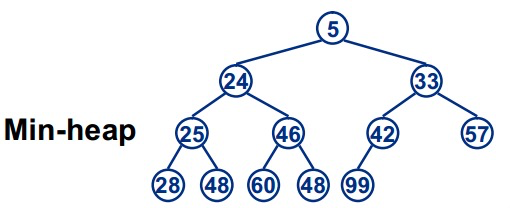
针对固定频率任务比如每5分钟一次,如何实现循环呢?答案是当一个任务执行结束前,计算出下次执行时间,然后重新添加到队列,队列则自动根据优先级调整顺序。多线程是针对多任务并发执行,针对单个任务仍然可以看作是单线程执行,同样如果任务执行时间超过执行周期,那么也会导致任务延迟。
ps:这里 ScheduledThreadPoolExecutor 针对多线程下任务抢占线程切换消耗做了leader/follow模式优化,有兴趣可以看下源码。
Spring调度
在Spring中可以很容易用 @Scheduled 注解开启一个定时任务,其内部适配了 Quratz 以及 ScheduledThreadPoolExecutor 两种实现,默认为 ScheduledThreadPoolExecutor ,其中针对 ScheduledThreadPoolExecutor 额外提供了cron定时形式,实现原理与固定类似,如下图所示,在 ReschedulingRunnable 类中执行完毕后,会再次开启下一个定时任务。
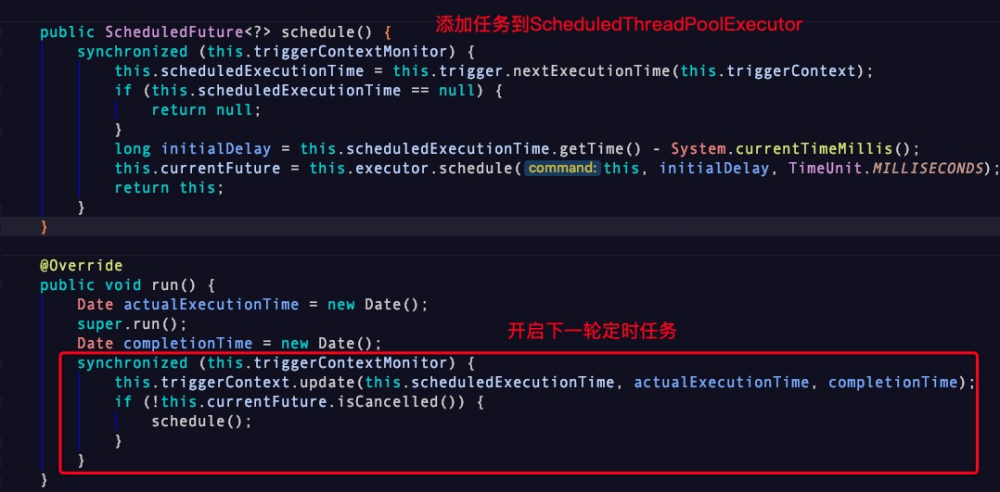
PS:关于Spring如何切入到Bean注册流程,扫描出对应 @Scheduled 注解对应的方法,注册对应定时器,这一流程也值得学习,有兴趣的同学可以从 ScheduledAnnotationBeanPostProcessor 类开始看。
时间轮调度
上述的调度实际上都是依赖于优先级队列,除此之外还有 time wheel 算法,如下图所示,原理是把时间按照bucket进行分配,比如下面一轮8个格子,假设一个格子1秒,指针从0开始走,当走到1时,发现其对应两个任务需要分别走2轮和4轮后才能执行,因此继续下去,当再次走到0时,对应所有任务轮数减1,因此针对该bucket上的任务需要 round() * 8 + N 秒才能被执行。
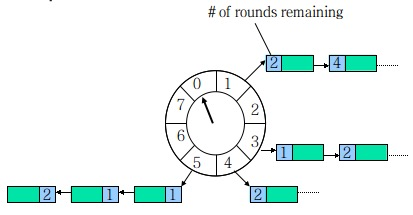
单时间轮会因为调度周期导致任务的 round() 变得很大,需要走很多轮才能被执行,同时一个bucket可能挂在很多个任务,导致效率降低,因此出现了变种算法层级时间轮,即多个时间轮嵌套,上级时间轮对应的 round() 变为0后,则下方到下级,直到最底层时间轮才被执行。
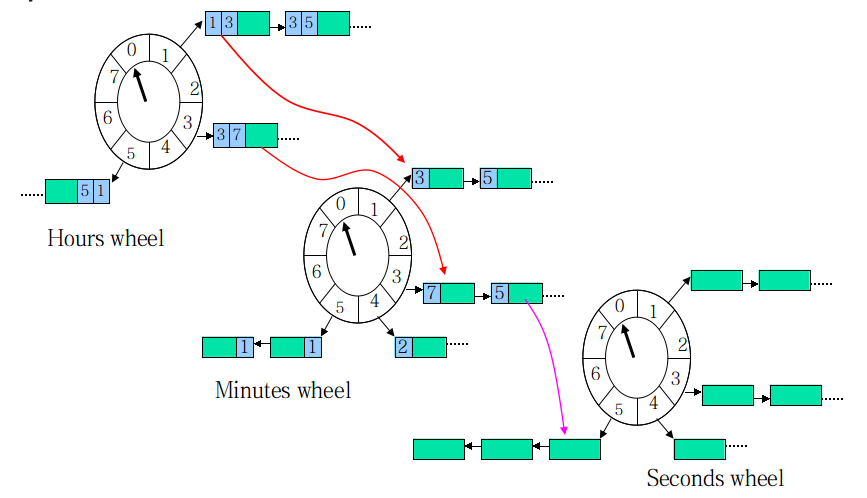
分布式调度
在分布式环境下,单机调度有着复杂的问题,比如多台机器一起触发,需要业务上做幂等,或者使用分布式锁+重试策略,以防万一还需要提供手动触发能力。对于量比较大的计算,无法充分发挥集群优势,只能落到单台机器执行等等问题。
无论单机还是分布式,调度框架模型始终 调度器(Scheduler)、任务(Job)和触发器(Trigger) 三大组件,而分布式的策略是把 触发器(Trigger) 集群化,任务触发消息通过其他服务转交给对应业务系统,业务系统承担 调度器(Scheduler)、任务(Job) ,执行完毕后反馈给触发器。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

