Spring Batch 4.2.0.RC1 发布,改进性能
Spring Batch 4.2.0.RC1 已发布 ,这是一个使用 Spring 和 Java 编写离线和批处理应用程序的框架。本次更新主要针对核心框架的性能方面进行了改进。
接下来了解一下具体的改进内容,总共包括四个方面:
- 增强 Step Partitioning 功能
- 改进 Job Stop
- Faster Writes with the
JpaItemWriter - Optimized Bean Mapping with the
BeanWrapperFieldSetMapper
增强 Step Partitioning 功能
一直以来,Spring Batch 框架都没有对启动 partitioned step 进行过良好的优化。在该版本中,团队深入研究了分区过程,以找出导致此性能问题的根本原因。分区过程的主要步骤之一是找到最后执行的 step(以查看当前执行是否为重新启动的 partitioned step)。团队由此发现了最后执行的 step 在给定的内存实例中会从所有任务执行中加载所有的 step 执行,这明显会降低效率。
为此,团队使用一个 SQL 查询(数据库级别的查询)替换了这些代码,仅返回最后执行的 step。最后的结果也非常不错,根据 partitioned-step-benchmark 基准测试的结果,使用此方法将 step 执行划分为 5000 个分区最终将速度提升了将近 10 倍:
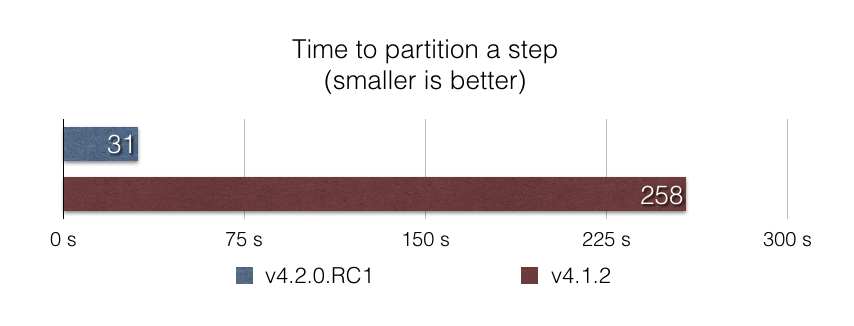
改进 Job Stop 功能
这个功能的改进思路和上面的类似,也是通过改用 SQL 查询来提升执行效率,最终结果如下
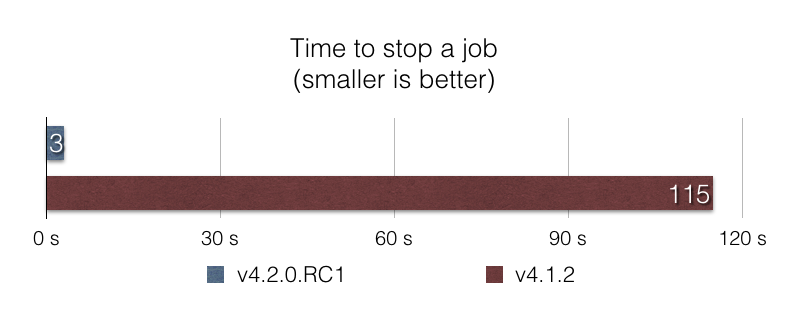
使用 JpaItemWritershi 实现更快的写入
JpaItemWritershi 使用 javax.persistence.EntityManager#merge 函数在 JPA 持久化的上下文中写入条目。当条目的状态未知或已知为更新状态时,这是有意义的。但在许多已知数据是新数据并应视为插入数据的文件提取任务中,使用 javax.persistence.EntityManager#merge 的效率并不高。
在此版本中,团队在 JpaItemWriter 中引入了一个新的可选项,以在上述的场景中使用 persist 而非 merge 。通过这个可选项,根据 jpa-writer-benchmark 基准测试,文件提取任务使用 JpaItemWriter 在数据库插入 100 万个条目的速度比之前快了 2 倍。
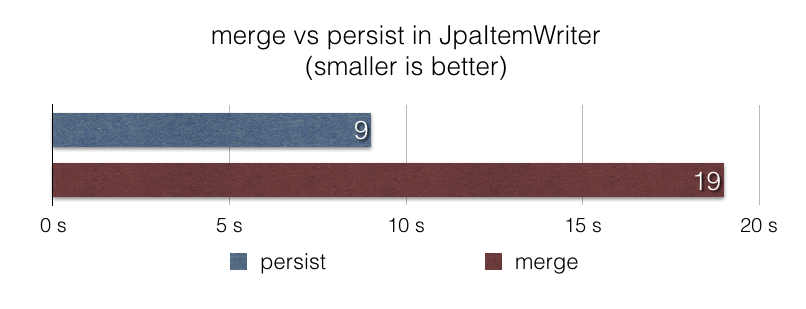
使用 BeanWrapperFieldSetMapper 对 Bean Mapping 进行优化
BeanWrapperFieldSetMapper 提供了一个十分实用的特性,它可以让我们用一个给定的 JavaBean (驼峰命名、嵌套属性等)的字段名进行模糊匹配。当字段名与列的名称匹配时,可通过将 distanceLimit 的参数设置为 0 来启用完全匹配。
此版本修复了 BeanWrapperFieldSetMapper 的性能问题,根据 bean-mapping-benchmark 基准测试 的结果,条目的映射速度比之前快了 1.5 倍。
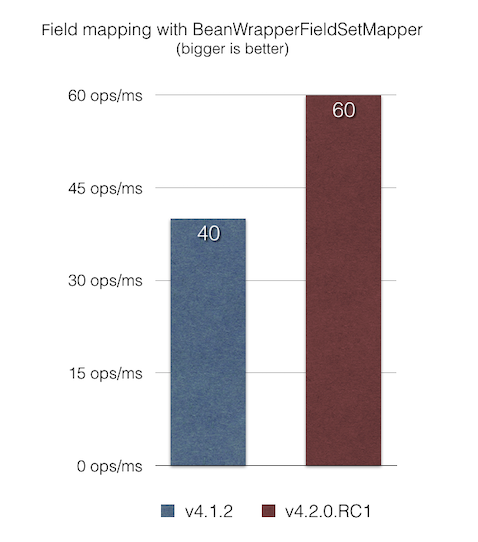
最后,所有基准测试均在 Macbook Pro(16GB RAM, 2.9 GHz Intel Core i7 CPU, MacOS Mojave 10.14.5, Oracle JDK 1.8.0_201)设备中进行。相关的测试基准源码如下:
- partitioned-step-benchmark: https://github.com/benas/spring-batch-sandbox/tree/master/batch2716
- stop-benchmark: https://github.com/benas/spring-batch-sandbox/tree/master/batch2422
- jpa-writer-benchmark: https://github.com/benas/spring-batch-sandbox/tree/master/batch2462
- bean-mapping-benchmark: https://github.com/benas/spring-batch-sandbox/tree/master/batch1801
下一个版本是 Spring Batch 4.2.0 的候选版,将于 9 月 30 日发布。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

