Spring Cloud Sleuth+Zipkin
| 编辑推荐: |
|
本文来自于csdn,Spring Cloud Sleuth是 Spring Cloud为分布式服务链路跟踪提供的解决方案。本文我们将详细介绍与分析 Spring Cloud Sleuth + Zipkin 的实现原理。 |
Spring Cloud Sleuth+Zipkin原理分析 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。 针对微服务化应用链路追踪的问题,Google在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。目前链路追踪组件主要有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
Spring Cloud Sleuth
提供链路追踪。通过sleuth可以很清楚的看出一个请求都经过了哪些服务;可以很方便的理清服务间的调用关系。
可视化错误。对于程序未捕捉的异常,可以结合zipkin分析。
分析耗时。通过sleuth可以很方便的看出每个采样请求的耗时,分析出哪些服务调用比较耗时。当服务调用的耗时随着请求量的增大而增大时,也可以对服务的扩容提供一定的提醒作用。
优化链路。对于调用频繁的服务,可以并行调用或针对业务做一些优化措施等。
基本概念
分布式服务跟踪系统主要包括下面三个关键点:

(1)Trace:它是由一组有相同Trace ID的Span串联形成一个树状结构。为了实现请求跟踪,当请求请求到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识(即前文提到的Trace ID),同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识,直到返回请求为止,我们通过它将所有请求过程中的日志关联起来;
(2)Span:它代表了一个基础的工作单元,例如服务调用。为了统计各处理单元的时间延迟,当前请求到达各个服务组件时,也通过一个唯一标识(即前文提到的Span ID)来标记它的开始、具体过程以及结束。通过span的开始和结束的时间戳,就能统计该span的时间延迟,除此之外,我们还可以获取如事件名称、请求信息等元数据。
(3)Annotation:它用于记录一段时间内的事件。内部使用的最重要的注释是:
cs - Client Sent - 客户端发送一个请求,这个注解描述了这个Span的开始。
sr - Server Received - 服务端获得请求并准备开始处理它,其中(sr – cs) 时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)– 该注解表明请求处理的完成(当请求返回客户端), (ss – sr)时间戳就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)- 表明此时Span的结束,(cr – cs)时间戳便可以得到整个请求所消耗的时间。
采样率
如果服务的流量很大,全部采集对传输、存储压力比较大。这个时候可以设置采样率,sleuth 可以通过配置 spring.sleuth.sampler.probability=X.Y(如配置为1.0,则采样率为100%,采集服务的全部追踪数据),若不配置默认采样率是0.1(即10%)。也可以通过实现bean的方式来设置采样为全部采样(AlwaysSampler)或者不采样(NeverSampler):如
@Bean public Sampler defaultSampler() { return new AlwaysSampler(); }
sleuth采样算法的实现是 Reservoir sampling(水塘抽样)。实现类是 PercentageBasedSampler。
源码简析
Spring Cloud Sleuth可以追踪以下类型的组件:async,hystrix,messaging,websocket,rxjava,scheduling,web(SpringWebMvc,Spring WebFlux, Servlet),webclient(Spring RestTemplate),feign,zuul。通过spring-cloud-sleuth-core的jar包结构,可以很明显的看出,sleuth支持链路追踪的组件(web下面包括http、client和feign):
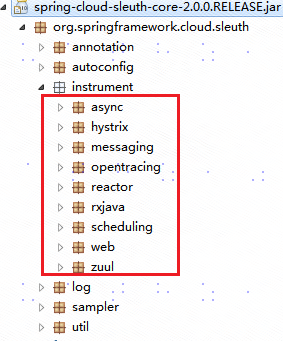
web
webflux通过注册TraceWebFilter, webmvc通过实现HandlerInterceptorAdapter,Servlet通过定义AOP切面对@RestController、@Controller、Callable对请求进行trace拦截,完成span的新建、传递和销毁。可以设置spring.sleuth.web.enabled为false禁用所有web请求的sleuth跟踪。
async
通过TraceAsyncAspect对@Async注解进行拦截,通过 TraceRunnable 和 TraceCallable来对runnable和callable进行包装和利用LazyTraceExecutor来代替java的Executor。Spring Cloud Sleuth利用以上方式进行span的新建和销毁。 如果需要禁用的话,可以设置spring.sleuth.async.enabled为false。如果禁用,与异步相关的机制就不会发生。
hystrix
原理是使用HystrixPlugins添加trace相关的plugin,自定义了一个HystrixConcurrencyStrategy子类SleuthHystrixConcurrencyStrategy 。若需要禁用可以设置spring.sleuth.hystrix.strategy.enable为false。
messaging
Spring Cloud Sleuth提供了TracingChannelInterceptor,是基于Spring message的ChannelInterceptorAdapter/ExecutorChannelInterceptor,它发布/订阅事件都是会进行span的新建和销毁的。可以设置spring.sleuth.integration.enabled为false禁用该机制。
websocket
将TracingChannelInterceptor拦截类注册到ChannelRegistration中进行trace拦截。
rxjava
通过自定义RxJavaSchedulersHook的子类SleuthRxJavaSchedulersHook,它使用TraceAction来包装实例中Action0。这个钩子对象,会根据之前调度的Action是否已经开始跟踪,来决定是创建还是延续使用span。可以通过设置spring.sleuth.rxjava.schedulers.hook.enabled为false来关闭这个对象的使用。可以定义一组正则表达式来对线程名进行过滤,来选择哪些线程不需要跟踪。
scheduling
原理是建立TraceSchedulingAspect 切面对Scheduled注解进行trace拦截,对span进行创建和销毁。可以通过设置spring.sleuth.scheduled.enabled为false来使该切面无效。
feign
Spring Cloud Sleuth默认通过TraceFeignClientAutoConfiguration提供feign的集成,可以设置spring.sleuth.feign.enabled为false来使其无效。
zuul
注册Zuul过滤器TracePostZuulFilter来传递tracing信息(请求头使用tracing数据填满),可以设置spring.sleuth.zuul.enabled为false来关闭Zuul服务。
Zipkin
Zipkin是Twitter的一个开源项目,我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的API接口来辅助查询跟踪数据以分布式系统的监控程序,通过UI组件帮助我们及时发现系统中出现的延迟升高问题以及系统性能瓶颈根源。
基本概念
下面展示Zipkin的基础架构,它主要由4个核心组件构成:
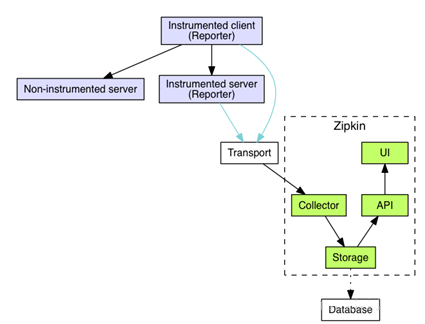
Collector(收集器组件):主要负责收集外部系统跟踪信息,转化为Zipkin内部的Span格式。
Storage(存储组件):主要负责收到的跟踪信息的存储,默认为存储在内存中,同时支持存储到Mysql、Cassandra以及ElasticSearch。
API(Query): 负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用。
Web UI(展示组件):提供简单的web界面,方便进行跟踪信息的查看以及查询,同时进行相关的分析。
Instrumented Client 和Instrumented Server,是指分布式架构中使用了Trace工具的两个应用,Client会调用Server提供的服务,两者都会向Zipkin上报Trace相关信息。在Client 和 Server通过Transport上报Trace信息后,由Zipkin的Collector模块接收,并由Storage模块将数据存储在对应的存储介质中,然后Zipkin提供API供UI界面查询Trace跟踪信息。Non-Instrumented Server,指的是未使用Trace工具的Server,显然它不会上报Trace信息。
追踪流程
流程图如下:
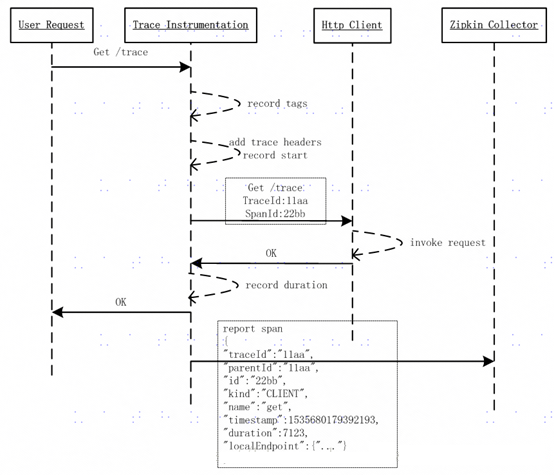
由上图可以看出,用户的应用发起Http Get(User Request)请求(请求路径/trace),经过spring cloud Sleuth的Trace框架(Trace Instrumentation)拦截,并依次经过如下步骤,最后记录Trace信息到Zipkin中:
记录tags信息;
将当前调用链的Trace信息记录到Http Headers中;
记录当前调用的时间戳(timestamp);
发送http请求,并携带Trace相关的Header,如TraceId:11aa, SpanId:22bb;
调用结束后,记录当次调用所花的时间(duration);
将步骤1-5,汇总成一个Span(最小的Trace单元),上报该Span信息给Zipkin Collector。
Web UI界面
下面用一个简单的Web应用来演示如何向Zipkin上报追踪数据。 首先打开Zipkin Web UI界面,点击 Find Traces,显示如下界面:
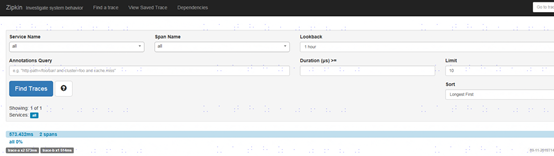
继续点击,查看详情,可以看到trace-a调用trace-b的跟踪链信息,trace-a整个过程耗时573.432ms,其中调用Backend服务耗时514.113ms;其中点击左侧跟踪栈的trace-a和trace-b,可以分别打开每条跟踪栈的详细信息。点击页面右上角的JSON,可以看到该Trace的所有数据。界面如下:

如果调用链路中发生服务调用失败,zipkin会默认使用红色展示信息,点击红色的span,可以看到详细的失败信息。如下图:
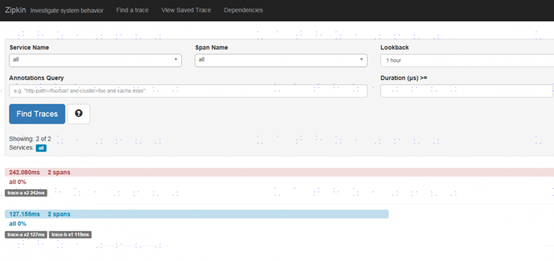
点击Dependencies页面,可以看到下图,trace-a和trace-b的依赖关系图。
在复杂的调用链路中假设存在一条调用链路响应缓慢,如何定位其中延迟高的服务呢?在使用分布式跟踪系统之前,我们一般只能依次分析调用链路上各个系统中的日志文件,而在使用了Sleuth+Zipkin提供的WebUI界面后,我们很容易搜索出一个调用链路中延迟高的服务。
应用程序集成
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。同时也可以只是简单的将数据记在日志中。
仅使用sleuth+log配置 这种方式只需要引入jar包(Maven中加入spring-cloud-starter-sleuth依赖)即可。如果配置log,这样会打印出如下的日志:

比原先的日志多出了 [trace-b,671e132878ee472b,84c7a5d82ccfaab9,false] 这些内容:[appname,traceId,spanId,exportable]。
appname:服务名称
traceId/spanId:链路追踪的两个术语,前文有介绍
exportable:是否是发送给zipkin。
2.sleuth+zipkin+http
sleuth收集跟踪信息通过http请求发给zipkin。这种需要启动一个zipkin,zipkin用来存储数据和展示数据。zipkin如果不配置存储的话,默认是在内存中的。如果存储在内存中,当重启应用后,数据就会丢失了。
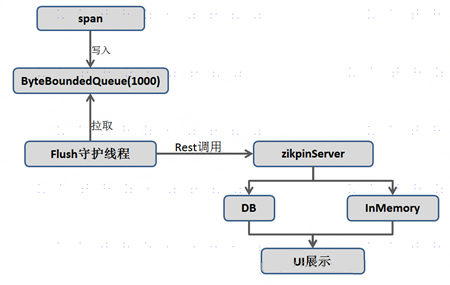
sletuh+streaming+zipkin 这种方式通过spring cloud streaming将追踪信息发送到zipkin。spring cloud streaming目前只支持kafka和rabbitmq。Zipkin Collector从消息中间件中读取数据并存储:

正文到此结束
- 本文标签: zipkin 时间 Sleuth zip 开源 message js MQ 数据 Hystrix Cassandra core tag tab bean 线程 分布式 SDN zuul java dependencies 文章 struct AOP UI 分布式系统 App stream 源码 src Action find Spring REST Google Feign spring REST ACE ip IO 配置 Elasticsearch CTO 微服务 服务器 dist Twitter tar id API Spring cloud mysql json http servlet executor sql rabbitmq 注释 Spring Cloud Sleuth web client Transport 服务端 开源项目 原理分析 正则表达式 实例 统计 2019 maven plugin 压力
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

