java多线程编程核心技术
一,共享资源 使用sleep()观察数据紊乱
**注意:**以下几份代码其中生产者(Producer.java),消费者(Consumer.java),和测试类(TestDemo.java)都完全一样主要对共享资源文件(Resource.java)操作
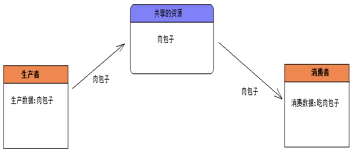
Resource.java
共享资源
//共享资源对象
public class Resource {
private String name;
private String gender;
// 让生产者调用设置共享资源的成员变量以供消费者的打印操作
public void push(String name, String gender) {
this.name = name;
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.gender = gender;
}
// 供消费者从共享资源取出数据
public void pop() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(this.name + "-" + this.gender);
}
复制代码
Producer.java
生产者
public class Producer implements Runnable {
public Resource resource = null;
public Producer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
resource.push("凤姐", "女");
} else {
resource.push("春哥", "男");
}
}
}
复制代码
Consumer.java
消费者
public class Consumer implements Runnable {
// 消费者拥有共享资源对象以便实现调用方法执行打印操作
public Resource resource = null;
// Creatr Constructor
public Consumer(Resource resource) {
this.resource = resource;
}
// 重写run()方法 执行pop()方法打印结果
@Override
public void run() {
for (int i = 0; i < 50; i++) {
resource.pop();
}
}
复制代码
TestDemo.java
测试代码
public class TestDemo {
public static void main(String[] args) {
// 创建共享资源对象 开启线程
Resource resource = new Resource();
new Thread(new Producer(resource)).start();
new Thread(new Consumer(resource)).start();
}
复制代码
分析结果:凤姐-男 凤姐-女 凤姐-男 发现性别乱序了 刚开始打印 凤姐-男 生产者先生产出春哥哥-男,此时消费者没有消费,生产者继续生产出姓名为凤姐,此时消费者开始消费了.
二,使用同步锁 避免数据紊乱
Resource.java
共享资源
//共享资源对象
public class Resource{
private String name;
private String gender;
//生产者向共享资源存储数据
synchronized public void push(String name, String gender) {
this.name = name;
try{
Thread.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
this.gender = gender;
}
// 消费者从共享资源对象取数据
synchronized public void pop(){
try{
Thread.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
System.out.println(this.name + "-" +this.gender);
}
复制代码
出现性别紊乱的情况.
- 解决方案:只要保证在生产姓名和性别的过程保持同步,中间不能被消费者线程进来取走数据.
- 可以使用同步代码块/同步方法/Lock机制来保持同步性.
三,怎么实现出现生产一个数据,消费一个数据.
-
应该交替出现: 春哥哥-男-->凤姐-女-->春哥哥-男-->凤姐-女.....
-
解决方案: 使用 等待和唤醒机制.
-
wait():执行该方法的线程对象释放同步锁,JVM把该线程存放到等待池中,等待其他的线程唤醒该线程. notify:执行该方法的线程唤醒在等待池中等待的任意一个线程,把线程转到锁池中等待. notifyAll():执行该方法的线程唤醒在等待池中等待的所有的线程,把线程转到锁池中等待. 注意:上述方法只能被同步监听锁对象来调用,否则报错IllegalMonitorStateException..
Resource.java
共享资源
//共享资源对象
public class Resource {
private String name;
private String gender;
private boolean isEmpty = true;// 表示共享资源对象是否为空的状态 第一次为空要设置默认值为true
// 生产者向共享资源对象中存储数据
synchronized public void push(String name, String gender) {
try {
while (!isEmpty) { // 当共享资源对象有值时 ,不空等着消费者来获取值 使用同步锁对象来调用
// 表示当前线程释放同步锁进入等待池只能被其他线程唤醒
this.wait();
}
this.name = name;
Thread.sleep(100);
this.gender = gender;
// 生成结束
isEmpty = false;// 设置共享资源对象为空
this.notify();// 唤醒一个消费者
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 消费者从共享资源对象中取数据
synchronized public void pop() {
try {
while (isEmpty) {// 当前共享资源为空 等待生产者来生产
// 使用同步锁对象来调用此方法 表示当前线程释放同步锁进入等待池只能被其他线程唤醒
this.wait();
}
// 消费开始
Thread.sleep(100);
System.out.println(this.name + "-" + this.gender);
// 消费结束
isEmpty = true;
// 唤醒其他线程
this.notify();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
复制代码
四, 线程通信-使用Lock和Condition接口
wait和notify方法,只能被同步监听锁对象来调用,否则报错IllegalMonitorStateException. 那么现在问题来了,Lock机制根本就没有同步锁了,也就没有自动获取锁和自动释放锁的概念. 因为没有同步锁,所以Lock机制不能调用wait和notify方法. 解决方案:Java5中提供了Lock机制的同时提供了处理Lock机制的通信控制的Condition接口.
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
//共享资源对象
public class Resource {
private String name;
private String gender;
private boolean isEmpty = true;
private final Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
// 生产者向共享资源存储数据
public void push(String name, String gender) {
lock.lock();
try {
while (!isEmpty) {
condition.await();
}
// 开始生成
this.name = name;
Thread.sleep(100);
this.gender = gender;
// 生成结束
isEmpty = false;
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();// 释放锁
}
}
// 消费者向共享资源获取数据
public void pop() {
lock.lock();
try {
while (isEmpty) {
condition.await();
}
Thread.sleep(100);
System.out.println(this.name + "-" + this.gender);
// 消费结束
isEmpty = true;
condition.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
复制代码
五,线程的生命周期
-
线程状态

-
说法 一
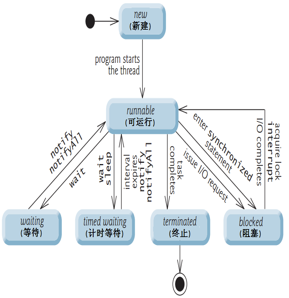
-
说法 二
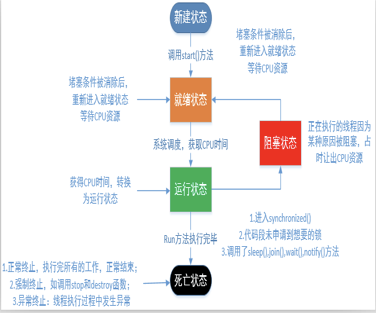
有人又把阻塞状态,等待状态,计时等待状态合称为阻塞状态.
线程对象的状态存放在Thread类的内部类(State)中:
注意:Thread.State类其实是一个枚举类. 因为线程对象的状态是固定的,只有6种,此时使用枚举来表示是最恰当的.
-
1:新建状态(new):使用new创建一个线程对象,仅仅在堆中分配内存空间,在调用start方法之前. 新建状态下,线程压根就没有启动,仅仅只是存在一个线程对象而已. Thread t = new Thread();//此时t就属于新建状态
当新建状态下的线程对象调用了start方法,此时从新建状态进入可运行状态. 线程对象的start方法只能调用一次,否则报错:IllegalThreadStateException.
-
2:可运行状态(runnable):分成两种状态,ready和running。分别表示就绪状态和运行状态。 就绪状态:线程对象调用start方法之后,等待JVM的调度(此时该线程并没有运行). 运行状态:线程对象获得JVM调度,如果存在多个CPU,那么允许多个线程并行运行.
-
3:阻塞状态(blocked):正在运行的线程因为某些原因放弃CPU,暂时停止运行,就会进入阻塞状态. 此时JVM不会给线程分配CPU,直到线程重新进入就绪状态,才有机会转到运行状态. 阻塞状态只能先进入就绪状态,不能直接进入运行状态. 阻塞状态的两种情况:
-
1):当A线程处于运行过程时,试图获取同步锁时,却被B线程获取.此时JVM把当前A线程存到对象的锁池中,A线程进入阻塞状态.
-
2):当线程处于运行过程时,发出了IO请求时,此时进入阻塞状态.
-
4:等待状态(waiting)(等待状态只能被其他线程唤醒):此时使用的无参数的wait方法,
- 1):当线程处于运行过程时,调用了wait()方法,此时JVM把当前线程存在对象等待池中.
-
5:计时等待状态(timed waiting)(使用了带参数的wait方法或者sleep方
-
6:终止状态(terminated):通常称为死亡状态,表示线程终止.
-
1):正常执行完run方法而退出(正常死亡).
-
2):遇到异常而退出(出现异常之后,程序就会中断)(意外死亡).
线程一旦终止,就不能再重启启动,否则报错(IllegalThreadStateException).
在Thread类中过时的方法(因为存在线程安全问题,所以弃用了): void suspend() :暂停当前线程 void resume() :恢复当前线程 void stop() :结束当前线程
六, 联合线程:
线程的join方法表示一个线程等待另一个线程完成后才执行。join方法被调用之后,线程对象处于阻塞状态。 有人也把这种方式称为联合线程,就是说把当前线程和当前线程所在的线程联合成一个线程。
class Join extends Thread{
public void run(){
for(int i=0;i<50;i++){
System.out.println("join:"+i);
}
}
}
//联合线程
public class UniteThread {
public static void main(String[] args) throws Exception {
System.out.println("begin.....");
Join joinThread = new Join();
for(int i=0;i<50;i++){
System.out.println("main:"+i);
if(i==10){
//启动join线程
joinThread.start();
}
if(i==20){
//强制执行该线程,执行结束再执行其他线程
joinThread.join();
}
}
System.out.println("end");
}
}
复制代码
七, 后台线程
后台线程:在后台运行的线程,其目的是为其他线程提供服务,也称为“守护线程"。JVM的垃圾回收线程就是典型的后台线程。 特点:若所有的前台线程都死亡,后台线程自动死亡,前台线程没有结束,后台线程是不会结束的。 测试线程对象是否为后台线程:使用thread.isDaemon()。 前台线程创建的线程默认是前台线程,可以通过setDaenon(true)方法设置为后台线程,并且当且仅当后台线程创建的新线程时,新线程是后台线程。 设置后台线程:thread.setDaemon(true),该方法必须在start方法调用前,否则出现IllegalThreadStateException异常。
public class DaemonThread extends Thread {
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(super.getName() + "-" + i);
}
}
public static void main(String[] args) {
System.out.println(Thread.currentThread().isDaemon());
for (int i = 0; i < 50; i++) {
System.out.println("main:" + i);
if (i == 10) {
DaemonThread t = new DaemonThread();
t.setDaemon(true);
t.start();
}
}
}
}
复制代码
八,线程池的用法
// Executors.newCachedThreadPool();
//创建一个缓冲池,缓冲池容量大小为Integer.MAX_VALUE
// Executors.newSingleThreadExecutor();
//创建容量为1的缓冲池
// Executors.newFixedThreadPool(int);
//创建固定容量大小的缓冲池
class MyTask implements Runnable {
public MyTask() {
}
@Override
public void run() {
//do something
}
}
ExecutorService executor = Executors.newFixedThreadPool(5)
MyTask myTask = new MyTask();
executor.execute(myTask);
复制代码
对于单次提交数据的数量,当然单次数量越少越快,但是次数会变多,总体时间会变长,单次提交过多,执行会非常慢,以至于可能会失败,经过多次测试数据量在几千到一万时是比较能够接受的。 选择那种线程池呢,是固定大小的,还是无限增长的。当线程数量超过限制时会如何呢?这几种线程池都会抛出异常。 有一定经验的同志会不屑的说阻塞的线程池,基本就比较靠谱,例如加上等待队列,等待队列用一个阻塞的队列。小的缺点是一直创建线程,感觉也不是非常的合理。
-
带队列的线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new ArrayBlockingQueue(5)); 复制代码
使用生产者与消费者对程序进行改进
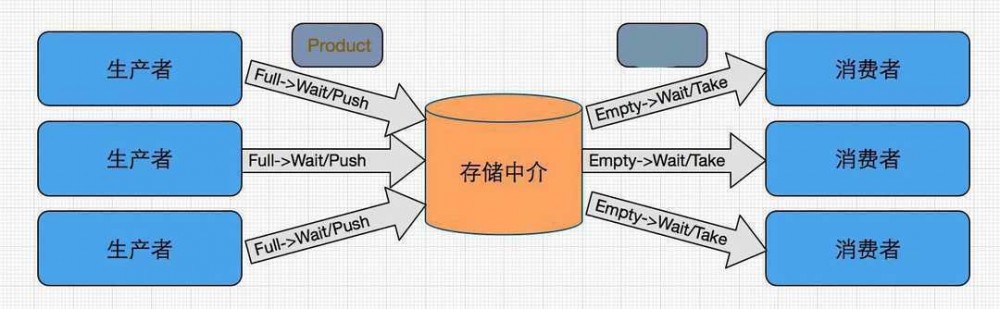
Producer.java
生产者
import java.util.concurrent.ArrayBlockingQueue;
public class Producerlocal implements Runnable {
ArrayBlockingQueue<String> queue;
public Producerlocal(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 0; i < 1000; i++) {
queue.put("s" + i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
复制代码
Consumer.java
消费者
import java.util.concurrent.ArrayBlockingQueue;
public class Consumerlocal implements Runnable {
ArrayBlockingQueue<String> queue;
public Consumerlocal(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
final String take = queue.take();
if ("poisonpill".equals(take)) {
return;
}
//do something
System.out.println(take);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
复制代码
main
主程序
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Main {
public static void main(String[] args) throws InterruptedException {
int threadNum = Runtime.getRuntime().availableProcessors() * 2;
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<String>(100);
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < threadNum; i++) {
executor.execute(new Consumerlocal(queue));
}
Thread pt = new Thread(new Producerlocal(queue));
pt.start();
pt.join();
for (int i = 0; i < threadNum; i++) {
queue.put("poisonpill");
}
executor.shutdown();
executor.awaitTermination(10L, TimeUnit.DAYS);
}
}
复制代码
程序使用了阻塞队列,队列设置一定的大小,加入队列超过数量会阻塞,队列空了取值也会阻塞,感兴趣的同学可以查看jdk源码。消费者线程数是CPU的两倍,对于这些类的使用需要查看手册和写测试代码。对于何时结束线程也有一定的小技巧,加入足够数量的毒丸。
对于代码使用了新的模式,程序明显加快了,到这里生产者消费者模式基本就结束了。如果你下次想起你的程序也需要多线程,正好适合这种模式,那么套用进来就是很好的选择。当然你现在能做的就是撸起袖子,写一些测试代码,找到这种模式的感觉。
因为程序的大多数时间还是在http请求上,程序的运行时间仍然不能够接受。于是想到了利用异步io加快速度,而不用阻塞的http。但是问题是这次的http客户端为了安全验证进行了修改,有加密验证和单点登录,新的客户端能适配起来有一定难度估计需要一定的时间,还是怕搞不定。异步的非阻塞io,对于前面数据结果选择的经验,非阻塞不一定就是好!其实是没太看懂怎么在多线程中使用,而对于所得到的效果就不得而知了。
maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpasyncclient</artifactId>
<version>4.1.3</version>
</dependency>
复制代码
异步http
/*
* ===============================================
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
* =============================================== *
* This software consists of voluntary contributions made by many
* individuals on behalf of the Apache Software Foundation. For more
* information on the Apache Software Foundation, please see
* <http://www.apache.org/>.
*
*/
package com.github.yfor.bigdata.tdg;
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.nio.client.CloseableHttpPipeliningClient;
import org.apache.http.impl.nio.client.HttpAsyncClients;
import org.apache.http.nio.IOControl;
import org.apache.http.nio.client.methods.AsyncCharConsumer;
import org.apache.http.nio.protocol.BasicAsyncRequestProducer;
import org.apache.http.protocol.HttpContext;
import java.io.IOException;
import java.nio.CharBuffer;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Future;
/**
* This example demonstrates a pipelinfed execution of multiple HTTP request / response exchanges
* with a full content streaming.
*/
public class MainPhttpasyncclient {
public static void main(final String[] args) throws Exception {
CloseableHttpPipeliningClient httpclient = HttpAsyncClients.createPipelining();
try {
httpclient.start();
HttpHost targetHost = new HttpHost("httpbin.org", 80);
HttpGet[] resquests = {
new HttpGet("/"),
new HttpGet("/ip"),
new HttpGet("/headers"),
new HttpGet("/get")
};
List<MyRequestProducer> requestProducers = new ArrayList<MyRequestProducer>();
List<MyResponseConsumer> responseConsumers = new ArrayList<MyResponseConsumer>();
for (HttpGet request : resquests) {
requestProducers.add(new MyRequestProducer(targetHost, request));
responseConsumers.add(new MyResponseConsumer(request));
}
Future<List<Boolean>> future = httpclient.execute(
targetHost, requestProducers, responseConsumers, null);
future.get();
System.out.println("Shutting down");
} finally {
httpclient.close();
}
System.out.println("Done");
}
static class MyRequestProducer extends BasicAsyncRequestProducer {
private final HttpRequest request;
MyRequestProducer(final HttpHost target, final HttpRequest request) {
super(target, request);
this.request = request;
}
@Override
public void requestCompleted(final HttpContext context) {
super.requestCompleted(context);
System.out.println();
System.out.println("Request sent: " + this.request.getRequestLine());
System.out.println("=================================================");
}
}
static class MyResponseConsumer extends AsyncCharConsumer<Boolean> {
private final HttpRequest request;
MyResponseConsumer(final HttpRequest request) {
this.request = request;
}
@Override
protected void onResponseReceived(final HttpResponse response) {
System.out.println();
System.out.println("Response received: " + response.getStatusLine() + " -> " + this.request.getRequestLine());
System.out.println("=================================================");
}
@Override
protected void onCharReceived(final CharBuffer buf, final IOControl ioctrl) throws IOException {
while (buf.hasRemaining()) {
buf.get();
}
}
@Override
protected void releaseResources() {
}
@Override
protected Boolean buildResult(final HttpContext context) {
System.out.println();
System.out.println("=================================");
System.out.println();
return Boolean.TRUE;
}
}
}
复制代码
配置
package com.github.yfor.bigdata.tdg;
public interface KafkaProperties {
final static String zkConnect = "localhost:2181";
final static String groupId = "group21";
final static String topic = "topic4";
final static String kafkaServerURL = "localhost";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String clientId = "SimpleConsumerDemoClient";
}
复制代码
kafka的配置需要一定的时间,可以阅读官方文档进行安装并运行。
生产者线程
package com.github.yfor.bigdata.tdg;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class Producer extends Thread {
private final KafkaProducer<Integer, String> producer;
private final String topic;
private final Boolean isAsync;
private final int size;
public Producer(String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093");
props.put(ConsumerConfig.CLIENT_ID_CONFIG, "DemoProducer");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<Integer, String>(props);
this.topic = topic;
this.isAsync = true;
this.size = producer.partitionsFor(topic).size();
}
@Override
public void run() {
int messageNo = 1;
while (messageNo < 100) {
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String messageStr = "Message_" + messageNo;
long startTime = System.currentTimeMillis();
if (isAsync) { // Send asynchronously 异步
producer.send(new ProducerRecord<>(topic, messageNo % size, messageNo, messageStr),
new DemoCallBack(startTime, messageNo, messageStr));
} else { // Send synchronously 同步
try {
producer.send(new ProducerRecord<>(topic, messageNo, messageStr)).get();
System.out.println("Sent message: (" + messageNo + ", " + messageStr + ")");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
++messageNo;
}
}
}
class DemoCallBack implements Callback {
private final long startTime;
private final int key;
private final String message;
public DemoCallBack(long startTime, int key, String message) {
this.startTime = startTime;
this.key = key;
this.message = message;
}
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
long elapsedTime = System.currentTimeMillis() - startTime;
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}
复制代码
消费者线程
package com.github.yfor.bigdata.tdg;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class KafkaConsumer extends Thread {
private final ConsumerConnector consumer;
private final String topic;
private final int size;
public KafkaConsumer(String topic) {
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
this.size = 5;
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
try {
sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(size));
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
ExecutorService executor = Executors.newFixedThreadPool(size);
for (final KafkaStream stream : streams) {
executor.submit(new KafkaConsumerThread(stream));
}
}
}
class KafkaConsumerThread implements Runnable {
private KafkaStream<byte[], byte[]> stream;
public KafkaConsumerThread(KafkaStream<byte[], byte[]> stream) {
this.stream = stream;
}
public void run() {
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
MessageAndMetadata<byte[], byte[]> mam = it.next();
System.out.println(Thread.currentThread().getName() + ": partition[" + mam.partition() + "],"
+ "offset[" + mam.offset() + "], " + new String(mam.message()));
}
}
}
复制代码
正文到此结束
- 本文标签: IDE producer App 垃圾回收 rmi 同步 synchronized git map http GitHub ORM list HashMap 源码 线程 build 数据 message CTO IO consumer JVM struct zookeeper ask 多线程 ioc value 线程通信 测试 example tar UI 线程池 空间 NIO final equals ip 安全 src API Service key bigdata apache Connection 加密 配置 ACE 时间 executor 锁 ArrayList mina apr dist Bootstrap queue HTML id java ThreadPoolExecutor stream https 安装 生命 代码 cache 参数 session maven cat client
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

