架构设计-异常处理
架构设计-异常处理
在开始正题之前,我想为自己最爱的影片《黑客帝国》写一段影评,黑客帝国三部曲分别是Matrix、Reload、Revolution。早期的Matrix是用亡羊补牢或对知情者灭口的消极方式加以应对,可是这样的运转模式显然无法长久,问题是会越积越多的,修补系统错误带来的可能是更多的错误,必须有一个方法定期对系统进行“大清洗“并重新启动(试想一个充满异常的服务器,这个服务器从来不停机维护)这就是大家一再提到的“Matrix升级“,但是麻烦的是连接在Matrix上的无数人类生命显然是无法重新启动的,这时对人类情感世界已经有相当了解的Matrix找到了一个“最经济“的方案,那就是反过来利用异常来消灭异常,并利用异常创造重新启动系统的机会,这个完美的计划就是电影黑客帝国三部曲的全部内容。

我们在设计自己的系统或平台时,就要考虑如何更加合理的设计异常,接下来我们就一起来看异常的设计。
No.1
异常概述
意外情况的发生阻碍事情的原计划,比如每天上班,正常情况下家到公司需要30分钟,某天由于在上班的路上发生了交通事故导致上班时间延长了1个小时,交通事故就是异常。而在程序中,异常就是程序在运行时期发生的问题,在理想的程序环境中,程序永远不会出现问题,用户的输入永远都是符合要求,逻辑没有任何问题,要打开的文件一定存在,类型转换一定是对的,内存一直是够用的.....总之没有任何问题,但是一旦出现这些描述的反面情况,如果不进行合理的处理,系统就不能正常运行,系统就无法提供正常的服务给用户。
要处理异常就要直到异常是如何发生的,就必须要知道异常的发生原因,要知道异常发生的原因就必须知道异常发生的场景。在系统中,模块和模块之间的交互都可能发生异常,以JAVA为例,在程序中都是利用Method和其他模块进行交互,那么异常的产生、抛出、声明和处理都在Method中,如下图就是java程序,模块和模块之间的交互逻辑。
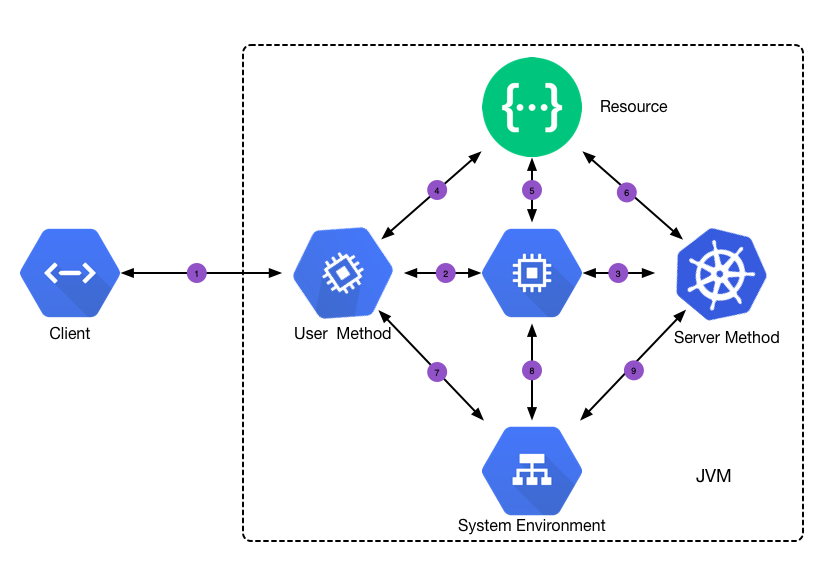
如图所示,你写的方法和外部实体交互大概可以分为五类:
-
和资源(Resource)交互,见图⑤处。这里资源的范围很广,比如进程外部的数据库,文件,SOA服务,其他各种中间件;进程内的类,方法,线程……都算是资源。
-
给进程内的其他方法(User Method)提供服务,见图②处。
-
依赖进程内的其他方法(Server Method),见图③处。包括Java平台提供的方法和其他第三方供应方提供的方法。
-
和系统环境交互,见图⑧处。系统环境可能是直接环境——JVM,也可能是间接环境——操作系统或硬件等。
-
给外部实体提供服务,见图①处。这种外部实体一般会通过容器(或其他类似的机制)和你的方法进行交互。
Java方法和每一类实体进行交互时,都可能发生异常。当和资源交互时,常常会因为资源不可用而发生异常,比如发生找不到文件、数据库连接错误、找不到类、找不到方法……等等状况。有可能是直接产生的,见图⑤处;有可能是间接产生的,比如图⑥处发生异常,Server Method把异常抛给Your Method,图③处就间接发生了异常。一般来说,你写的方法间接发生这类异常的可能性比直接发生要大得多,因为直接产生这类异常的方法在Java平台中已经提供了。
异常一般具有如下特点:
-
问题产生于外部依赖,自身逻辑和流程没有问题。
-
此类问题通常是暂时的,服务端及时处理可以消除,用户可以再次使用系统服务或采取替补方案。
-
并不影响整体流程运行。
当给Client端的方法(User Method )提供服务时,用户可能会传入一些不合法的数据(或者其他不恰当的使用方法),进而影响正常流程运行。你的方法应该检查每一个输入数据,如果发现不合法的数据,马上阻止执行流程,并通知用户方法。
当调用服务方法(Server Method )时,有可能会发生两类异常。一类是你的使用方法不正确,导致服务中止;一类是服务方法出了异常,然后传递给你的方法。如果是第一种异常,你应该检查并修改你的方法逻辑,消除BUG。对于第二类异常,你要么写一个处理器处理,要么继续传递给上层方法。
当和系统环境交互时,有可能因为JVM参数设置不当,有可能因为程序产生了大量不必要的对象,也有可能因为硬故障(操作系统或硬件出了问题),导致整个程序不可用。当这类异常发生时,最终用户没法选择其他替代方案,操作到一半的数据会全部丢失。你的方法对这类异常一般没什么办法,既不能通过修改主流程逻辑来消除,也不能通过增加异常处理器来处理。所以通常你的方法对这类异常不需要做任何处理。但是你必须检查进程内的所有程序和系统环境是否正常,然后协调各方,修改BUG或恢复环境。
Java的异常都是发生在方法内,所以研究Java异常,要以你设计的方法为中心。我们以“你的方法 ”为中心,总结一下处理办法:当服务方法告诉“你的方法 ”的主流程逻辑有问题时,就要及时修复BUG来消除异常;当用户方法非法使用“你的方法”时,应该直接中止主流程,并通知用户方法,强迫用户方法使用正确的方式,防止问题蔓延;当服务方法传递一个异常给“你的方法”时,你要判断“你的方法”是否合适处理这个异常,如果不合适,传递给上层方法,如果合适,写一个异常处理器处理这个异常。当系统环境出了问题,“你的方法”什么也做不了。
以上所述,异常有三类:
-
检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。
-
运行时异常:运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。
-
错误:错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
刚才以“你的方法”为中心,总结了在“你的方法”内部的处理办法。现在以“你”为中心,总结一下方法外部的处理方法:当资源不可用的时候,你应该协调各方,恢复资源;当发生系统故障时,你应该协调各方,恢复系统。综上,已经基本分析清楚了异常发生的原因,以及相应的应对方法。
No.2
异常的好处
上面已经很清楚的阐述了什么异常,并且知道怎么使用异常,那么在程序中使用异常具体有那些好处呢?
好处一
隔离错误处理代码和常规代码
Exception提供了一种方法,把意外发生时的细节从程序主逻辑中隔离开来。在传统的编程中,错误的检测、报告和处理通常会导致像意大利面条那么混乱的代码。
下面通过一组伪代码来讲解。

readFile{
打开文件
确定大小
分配内存
读入内存
关闭文件
}
读取文件正常流程是很简单的,但是真实的运行过程中,有很多异常情况需要考虑:
-
当文件无法打开,应该如何处理?
-
当无法获取文件的大小,应该如何处理?
-
当服务器内存不足,应该如何处理?
-
当读取失败,应该如何处理?
-
当文件无法关闭,应该如何处理?
为了处理这么多异常情况,我们的做法有两种方式,方式一通过错误码来表示每一个异常发生的状态,方式二是通过异常来表示。

方式一:
errorCodeType readFile {
initialize errorCode = 0;
打开文件
if (theFileIsOpen) {
确定文件长度
if (gotTheFileLength) {
分配指定内存
if (gotEnoughMemory) {
将文件读入内存
if (readFailed) {
errorCode = -1;
}
} else {
errorCode = -2;
}
} else {
errorCode = -3;
}
关闭文件
if (theFileDidntClose && errorCode == 0) {
errorCode = -4;
} else {
errorCode = errorCode and -4;
}
} else {
errorCode = -5;
}
return errorCode;
}
为了保证流程正常进行,读取文件需要检测错误、返回状态,原本很简单的代码,通过各种if/else判断处理,代码变得很繁琐,代码的可读性变得很糟糕,如果通过第二种方式二,异常代替错误码来处理正常流程,我们看看会发生什么情况?
示例如下
readFile {
try {
打开文件
确定大小
分配内存
读入内存
关闭文件
} catch (fileOpenFailed) {
业务处理;
} catch (sizeDeterminationFailed) {
业务处理;
} catch (memoryAllocationFailed) {
业务处理;
} catch (readFailed) {
业务处理;
} catch (fileCloseFailed) {
业务处理;
}
}
从上面的伪代码可以看出,异常并没有忽略或者代替你做readFile过程中异常情况处理,而是通过异常处理让你的关注点更多的放在核心逻辑的处理,并且提高了代码的可读性。
好处二
在调用栈中向上传播错误
Exception的第二个优势就是,传播错误报告方法调用堆栈的能力。比如在一个应用流程中,readFile方法是最终被最上层得调用间接依赖,如:method1调用了method2,method2调用了method3,method3调用了readFile方法,因为readFile有很多异常情况需要处理,但是按照调用层次来看,method1是最终需要处理readFile异常错误码的方法,实现方法也有两种,方式一:逐层放回错误码,直到method1接受到错误码;方式二:通过逐层抛出异常,method1处理异常,其他层只关心上抛。

方式一:
method1 {
errorCodeType error;
error = call method2;
if (error){
错误处理;
}
else{
正常处理;
}
}
errorCodeType method2 {
errorCodeType error;
error = call method3;
if (error){
错误处理;
}
else{
正常处理;
}
}
errorCodeType method3 {
errorCodeType error;
error = call readFile;
if (error){
错误处理;
}
else{
正常处理;
}
}
上面的伪代码可以看出,最终只有method1 关心 readFile 所产生的错误,方式一将强制要求每个方法都关心并返回。如果有一种方式只让关心作物的方法才关心错误检测,中间环节只需要抛出异常是不是会好很多呢?方式二:就是通过调用堆栈向后搜索找到任何有兴趣处理特定异常的方法

方式二:
method1 {
try {
method2;
} catch (exception e) {
doErrorProcessing;
}
}
method2 throws exception {
method3;
}
method3 throws exception {
readFile;
}
中间环节不需要关注异常的发生,只有关心异常的方法才会捕获异常进行相应的处理。
好处三
分组和区分错误类型
因为程序中抛出的所有异常都是对象,所以异常的分组或分类是类层次结构的自然结果。Java 平台中的一组相关异常类的一个例子是在 java.io- 及其 IOException 后代中定义的异常类。IOException 是最通用的,表示执行 I / O 时可能发生的任何类型的错误。其后代代表更具体的错误。例如 FileNotFoundException 意味着文件不在磁盘上未找到
一种方法可以编写可以处理非常特定异常的特定处理程序。FileNotFoundException 类有没有后代, 所以下面处理器只能处理一种类型的异常。
catch (FileNotFoundException e) {
...
}
一个方法也可以用更通用的处理器捕获处理具体的异常。例如,为了捕获所有的I/O异常,不管具体的类型是什么,只要给异常处理器指定一个IOException参数就行。

catch (IOException e) {
...
}
这个处理器可以捕获所有的I/O异常,包括FileNotFoundException,EOFException等等。你可以通过查询传给异常处理器的参数,发现错误发生的细节。例如,用下面的代码打印堆栈跟踪信息:

catch (IOException e) {
// Output goes to System.err.
e.printStackTrace();
// Send trace to stdout.
e.printStackTrace(System.out);
}
你甚至可以构建一个可以处理所有异常的异常处理器:
// A (too) general exception handler
catch (Exception e) {
...
}
在大多数情况下,你希望异常处理器越具体越好。理由是在你决定最佳的恢复策略之前,你首先要知道错误的类型。事实上,如果不捕获具体的错误,这个处理器就必须要容纳任何可能性。太通用的异常处理器可能会让代码更容易出错,因为它们会捕获和处理程序员意料之外的异常,这样就超出处理器的能力范围了。
No.3
J2EE核心语言中的异常
Java把异常当做是破坏正常流程的一个事件,当事件发生后,就会触发处理机制。
Java有一套独立的异常处理机制,在遇到异常时,方法并不返回任何值(返回值属于正常流程),而是抛出一个封装了错误信息的对象。下图是Java异常处理机制类层级结构图:

在 Java 中,所有的异常都有一个共同的祖先 Throwable(可抛出)。Throwable 指定代码中可用异常传播机制通过 Java 应用程序传输的任何问题的共性。Throwable:有两个重要的子类:*Exception(异常)和 Error(错误)*,二者都是 Java 异常处理的重要子类,各自都包含大量子类。Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。Exception 类有一个重要的子类 RuntimeException。RuntimeException 类及其子类表示“JVM 常用操作”引发的错误。例如,若试图使用空值对象引用、除数为零或数组越界,则分别引发运行时异常(NullPointerException、ArithmeticException)和 ArrayIndexOutOfBoundException。
通常,Java的异常(包括Exception和Error)分为可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)。
运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
JVM字节码分析异常处理机制
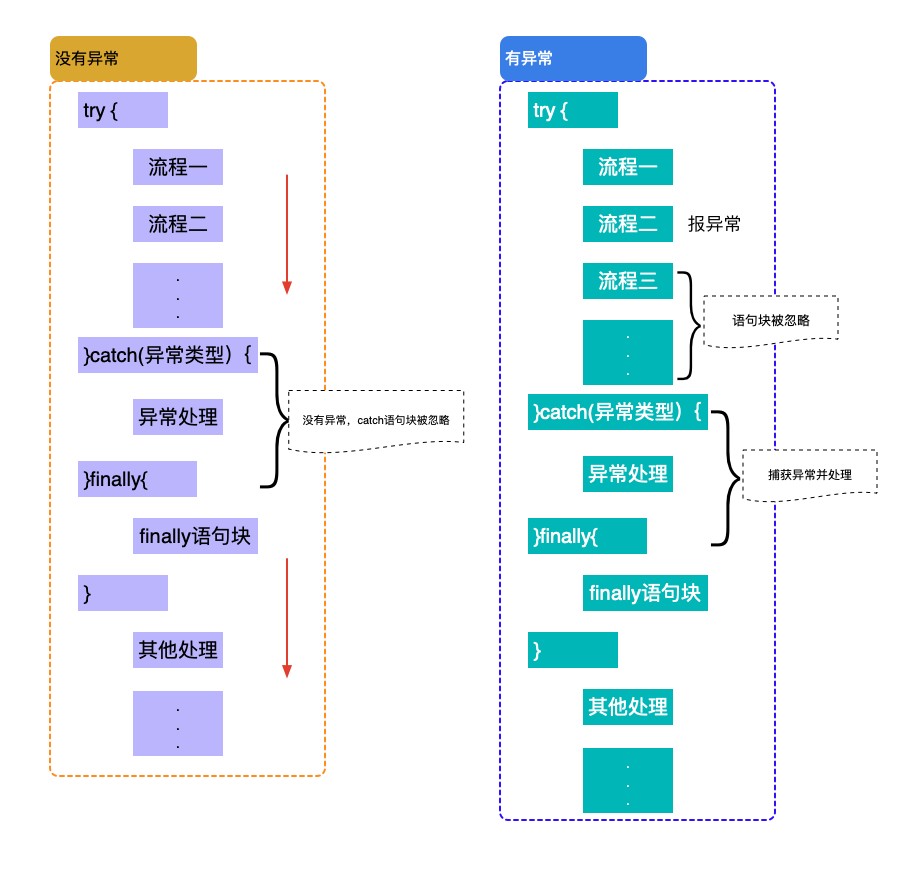
Java异常处理的一般性建议
01
try-catch-finally 规则
-
必须在 try 之后添加 catch 或 finally 块。try 块后可同时接 catch 和 finally 块,但至少有一个块。
-
必须遵循块顺序:若代码同时使用 catch 和 finally 块,则必须将 catch 块放在 try 块之后。
-
catch 块与相应的异常类的类型相关。
-
一个 try 块可能有多个 catch 块。若如此,则执行第一个匹配块。即Java虚拟机会把实际抛出的异常对象依次和各个catch代码块声明的异常类型匹配,如果异常对象为某个异常类型或其子类的实例,就执行这个catch代码块,不会再执行其他的 catch代码块
-
可嵌套 try-catch-finally 结构。
-
在 try-catch-finally 结构中,可重新抛出异常。
-
除了下列情况,总将执行 finally 做为结束:JVM 过早终止(调用 System.exit(int));在 finally 块中抛出一个未处理的异常;计算机断电、失火、或遭遇病毒攻击。
02
Throws抛出异常的规则
-
如果是不可查异常(unchecked exception),即Error、RuntimeException或它们的子类,那么可以不使用throws关键字来声明要抛出的异常,编译仍能顺利通过,但在运行时会被系统抛出。
-
必须声明方法可抛出的任何可查异常(checked exception)。即如果一个方法可能出现受可查异常,要么用try-catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误
-
仅当抛出了异常,该方法的调用者才必须处理或者重新抛出该异常。当方法的调用者无力处理该异常的时候,应该继续抛出,而不是囫囵吞枣。
-
调用方法必须遵循任何可查异常的处理和声明规则。若覆盖一个方法,则不能声明与覆盖方法不同的异常。声明的任何异常必须是被覆盖方法所声明异常的同类或子类。
No.4
异常处理和设计
下面介绍异常处理和设计注意的一些点:
1
使用异常,而不使用返回码
关于这一点,在上面『异常的好处』有解释。理解了这一点,程序员们才会想要使用Java异常处理机制。
2
利用运行时异常设定方法使用规则
很常见的例子就是,某个方法的参数不能为空。在实践中,很多程序员的处理方式是,当传入的这个参数为空的时候,就返回一个特殊值(最常见的就是返回一个null,让用户方法决定怎么办)。还有的处理方式是,自己给一个默认值去兼容这种不合法参数,自己决定怎么办。这两种实践都是不好的。
对于第一种处理方式,返回值是用来处理正常流程的,如果用来处理异常流程,就会让用户方法的正常流程变复杂。一次调用可能不明显,当有多个连续调用就会变得很复杂了。对于第二种处理方式,看起来很强大,因为“容错”能力看起来很强,有些程序员甚至可能会为此沾沾自喜。但是它也一样让正常流程变复杂了,这不是最糟糕的,最糟糕的是,你不知道下一次用户会出什么鬼点子,传个你现有处理代码处理不了的东西进来。这样你又得加代码,继续变复杂……BUG就是这样产生的。
好的实践方式就是,设定方法的使用规则,遇到不合法的使用方式时,立刻抛出一个运行时异常。这样既不会让主流程代码变复杂,也不会制造不必要的BUG。为什么是运行时异常而不是检查异常呢?这是为了强迫用户修改代码或者改正使用方式——这属于用户的使用错误。
3
消除运行时异常
当你的程序发生运行时异常,通常都是因为你使用别人的方法的方式不正确(如果设计这个异常的人设计错误,就另当别论。比如设计者捕获一个检查异常,然后在处理器抛出一个运行时异常给用户。如果遇上这样的供应商,还是弃用吧)。所以,一般都是采取修改代码的方式,而不是新增一个异常流程。
4
正确处理检查异常
处理检查异常的时候,处理器一定要做到下面的要求才算合格:
-
返回到一种安全状态,并能够让用户执行一些其他的命令;
-
允许用户保存所有操作的结果,并以适当的方式终止程序。
不好的实践案例一:因为有的异常发生的概率很小,有些程序员就会写出下面的代码:
public Image loadImage(String s) {
try {
code...
} catch (Exception e)
{}
code2...
}
catch代码块里面什么都不写!或者只在里面打一个log。这样既不会传递到上层方法,又不会报编译错误,还不用动脑筋……
不好的实践案例二:捕获一个检查异常,什么都不做(或只打一个log),然后抛出一个运行时异常:
public Image loadImage(String s) {
try {
code...
} catch (Exception e){
throw new RuntimeExcepiton();
}
}
这样也不会让上层方法感觉到这个异常的存在,也不会报编译错误了,也不用动什么脑筋……
在案例一中,一旦出现了异常,try代码块里的代码没执行完,用户要求做的事情没做完,却又没有任何反馈或者得到一个错误反馈。
在案例二中,一旦出现了异常,try代码块里的代码没执行完,虽然把运行时异常抛给用户了,用户也不会去处理这个异常,又没有办法通过改变使用方式消除异常,直接让用户代码崩溃掉。
对于检查异常,好的实践方式是:
-
让可以处理这个异常的方法去处理。衡量的标准就是在你这个方法写一个处理器,这个处理器能不能做到本节开头的那两个要求,如果不能,就往上抛。如果你不能知道所有用户的所有需求,你通常就做不到那两个要求。
-
有必要的时候可以通过链式异常包装一下,再抛出。
-
最终的处理器一定要做到本节开头的那两个要求。
5
使主流程代码保持整洁
一个try代码块后面可以跟多个catch代码块,这就让一些可能会发生不同异常的代码可以写在一块,让代码看起来很清晰。相反,在一个方法里写多个try-catch,或者写嵌套的try-catch,就会让主流程代码变得很混乱。
6
使用try-with-resources
try-with-resources语句比起普通的try语句,干净整洁的多。而且最终抛出的异常是正常流程中抛出的异常。
7
尽量处理最具体的异常
尽量使用最具体的异常类作为处理器匹配的类型。这样处理器就不用兼顾很多种情形,不易出错。从Java7开始,一个处理器可以处理多种异常类型。
注意:同一个try语句中,比较具体的异常的catch代码块应写在前面,比较通用的异常的catch代码块应写在后面。
8
设计自己的异常类型要遵循的原则
当你是一个模块开发者,你就很有必要设计一组或多组自己的异常类型。一般情况下,要遵守如下原则:
-
确定什么场景下,需要创建自己的异常类型。
-
为你的接口方法的使用规则创建一组运行时异常。
-
封装别人的检查异常的时候,一定也要用检查异常。这样异常才能传递给上层方法处理。
-
设计一组有层次结构的异常,而不是设计一堆零零散散的异常。
-
区分清楚异常发生的原因,然后决定你的异常是检查异常还是运行时异常。
-
模块内部不需要处理自己定义的异常。

总结

Java异常处理机制的目的至少有三个:一是归类处理不同的异常,二是提供足够的信息方便调试,三是让主流程代码保持整洁。
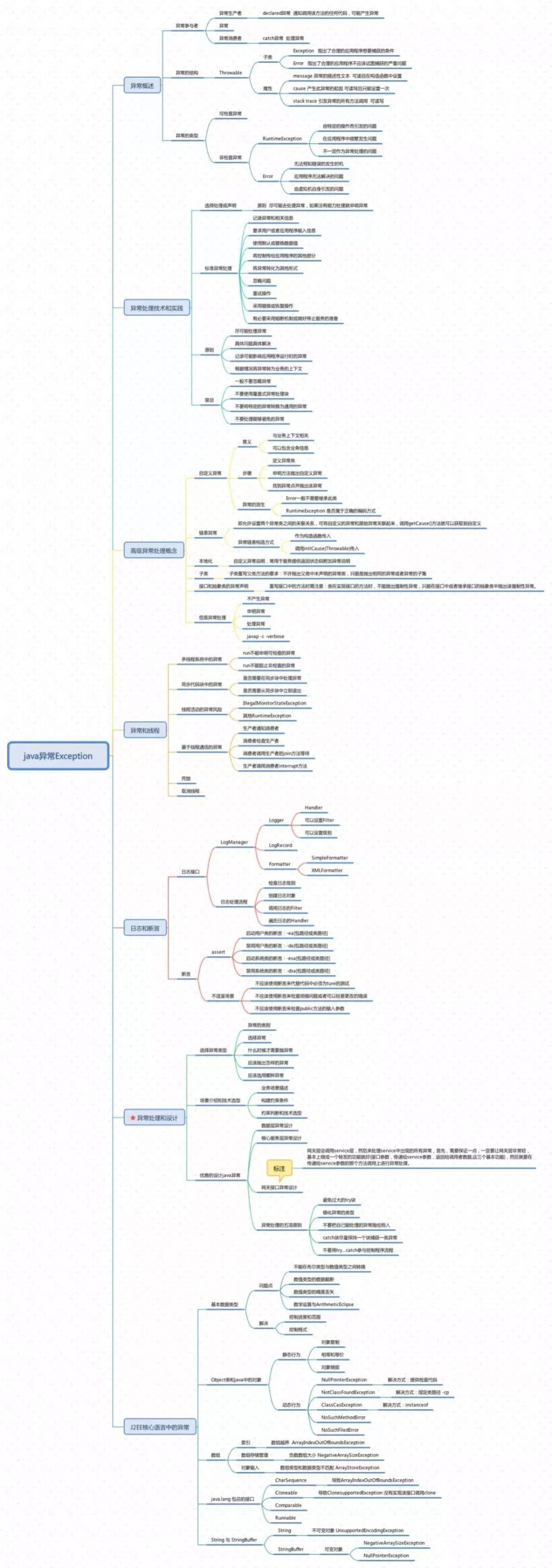
最后贴一张异常梳理的脑图
广告环节
《程序员的三门课》是我参与编辑,希望能给大家带来一点指引。



评论点赞前三名会获得我的签名
有需要的同学也可以通过京东购买
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

