UMA架构与NUMA架构下的自旋锁(CLH锁与MCS锁)
我们知道自旋锁是实现同步的一种方案,它是一种非阻塞锁。它与常规锁的主要区别就在于获取锁失败后的处理方式不同,常规锁会将线程阻塞并在适当时唤醒它。而自旋锁的核心机制就在自旋两个字,即用自旋操作来替代阻塞操作。某一线程尝试获取某个锁时,如果该锁已经被另一个线程占用的话,则此线程将不断循环检查该锁是否被释放,而不是让此线程挂起或睡眠。一旦另外一个线程释放该锁后,此线程便能获得该锁。自旋是一种忙等待状态,过程中会一直消耗CPU的时间片。
UMA架构
因为在分析CLH锁与MCS锁的缺点时会涉及处理器架构问题,所以在介绍每种自旋锁之前我们需要先了解两种处理器架构:UMA架构和NUMA架构。在多处理器系统中,根据内存的共享方式可以分为UMA(Uniform Memory Access)和NUMA(Non-uniform Memory Access),即统一内存访问和非统一内存访问。
UMA架构的性质就是每个CPU核访问主存储的时间都是一样的。下面看基于总线的UMA架构,一共有4个CPU处理器,它们都直接与总线连接,通过总线进行通信。从这个结构中可以看到,每个CPU都没有区别,它们平等地访问主存储。访问主存储所需的时间都是一样的,即为统一内存访问。
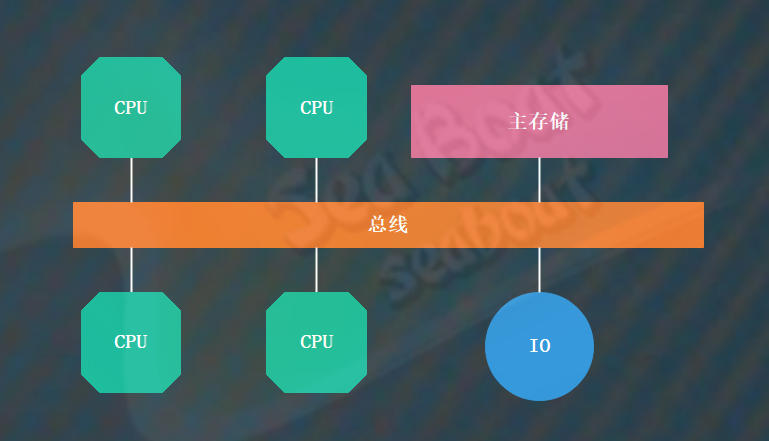
当某个CPU想要进行读写操作时,它首先会检查总线是否空闲,只有在空闲状态下才能允许其与主存储进行通信,否则它将等待直到总线空闲。为了优化这个问题,在每个CPU的内部引入缓存。这样一来,CPU的读操作就能够在本地的缓存中进行。但这时我们需要考虑CPU中缓存与主存的数据一致性问题,否则可能会引起脏数据问题。
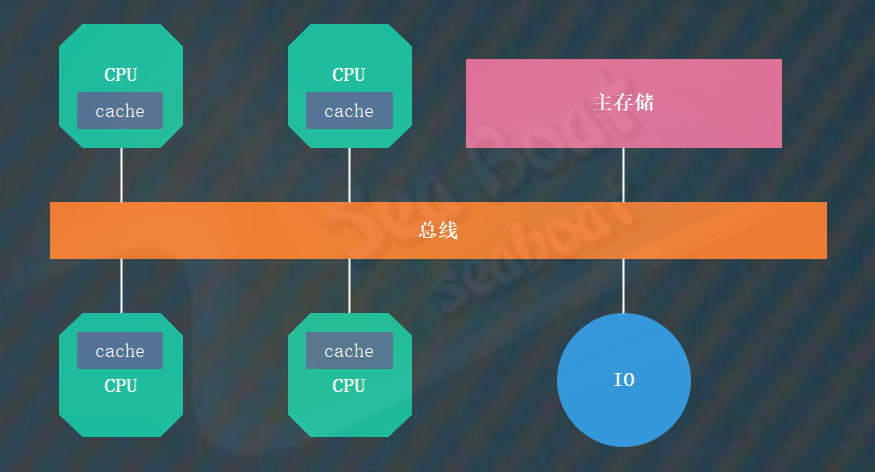
NUMA架构
与UMA架构相反,NUMA架构中并非每个CPU对主存储的访问时间都相同的,NUMA架构中CPU能访问所有主存储。通过下图可以看到CPU如果通过本地总线来访问相应的本地主存储的话,则访问时间较短,但如果访问的是非本地主存储(远程主存)则时间将很长,也就是CPU访问本地主存和访问远程主存的速度不相同。NUMA架构的优点就在于,它具有优秀的可扩展性,能够实现超过百个CPU的组合。

CLH锁
Craig、Landin、Hagersten三个人发明了CLH锁。其核心思想是:通过一定手段将所有线程对某一共享变量的轮询竞争转化为一个线程队列,且队列中的线程各自轮询自己的本地变量。
这个转化过程有两个要点:一是应该构建怎样的队列以及如何构建队列?为了保证公平性,我们构建的将是一个FIFO队列。构建的时候主要通过移动尾部节点tail来实现队列的排队,每个想获取锁的线程创建一个新节点并通过CAS原子操作将新节点赋给tail,然后让当前线程轮询前一节点的某个状态位。如图可以清晰看到队列结构及自旋操作,这样就成功构建了线程排队队列。二是如何释放队列?执行完线程后只需将当前线程对应的节点状态位置为解锁状态即可,由于下一节点一直在轮询,所以可获取到锁。
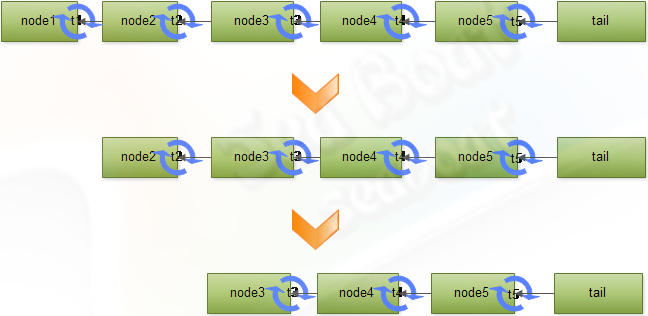
所以,CLH锁的核心思想是将众多线程长时间对某资源的竞争,通过有序化这些线程将其转化为只需对本地变量检测。而唯一存在竞争的地方就是在入队列之前对尾节点tail的竞争,但此时竞争的线程数量已经少了很多了。比起所有线程直接对某资源竞争的轮询次数也减少了很多,这也大大节省了CPU缓存同步的消耗,从而大大提升系统性能。
CLH锁已经解决了大量线程同时操作同一个变量而带来的同步问题,但它的自旋的对象是前驱节点。在NUMA架构下可能会存在性能问题,因为如果前驱节点和当前节点不再同一个本地主存储的话则访问时间会很长,这就会导致性能受影响。
MCS锁
MCS锁由John Mellor-Crummey和Michael Scott两人发明,它的出现旨在解决CLH锁存在的问题。它也是基于FIFO队列,与CLH锁相似,不同的地方在于轮询的对象不同。MCS锁中线程只对本地变量自旋,而前驱节点则负责通知其结束自旋操作。这样的话就减少了CPU缓存与主存储之间的不必要的同步操作,减少了同步带来的性能损耗。
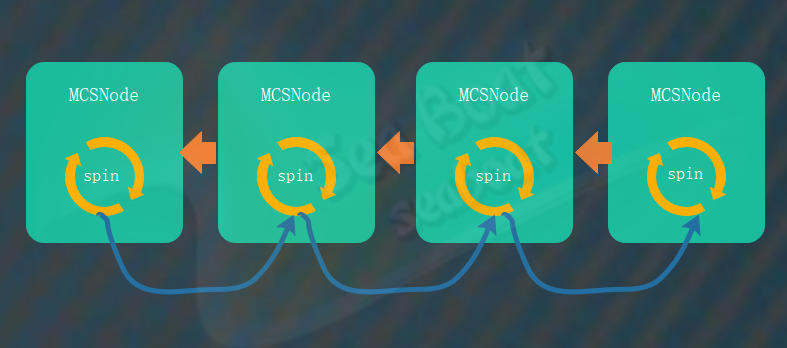
如下图,每个线程对应着队列中的一个节点。节点内有一个spin变量,表示是否需要旋转。一旦前驱节点使用完锁后,便修改后继节点的spin变量,通知其不必继续做自旋操作,已成功获取锁。
专注于人工智能、读书与感想、聊聊数学、计算机科学、分布式、机器学习、深度学习、自然语言处理、算法与数据结构、Java深度、Tomcat内核等。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

