VSCode Java输出中文乱码问题解决
本文适用于Windows,Linux中应该不会出现这种问题。
前几天由于要写OJ题我又打开了尘封已久的VSCode Java工作区,使用过程中遇到了中文乱码的问题,照理说应该是不会出现这种问题的,因为我当初在配置Java环境的时候就已经解决了中文乱码的问题。然后一直懒得修,直到今天有空。
博主我原先是将JDK的编码和Java文件的编码都设置为GBK,这样在运行的时候就不会出现中文乱码的问题,不知从那个版本开始这种方式就不可行了,于是只能重新的测试。
测试用的代码如下:
// encoding: GBK
package Test;
import java.io.ByteArrayOutputStream;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.nio.charset.Charset;
class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println("Default Charset=" + Charset.defaultCharset());
System.out.println("file.encoding=" + System.getProperty("file.encoding"));
System.out.println("Default Charset=" + Charset.defaultCharset());
System.out.println("Default Charset in Use=" + getDefaultCharSet());
System.out.println("你好世界");
}
private static String getDefaultCharSet() {
OutputStreamWriter writer = new OutputStreamWriter(new ByteArrayOutputStream());
String enc = writer.getEncoding();
return enc;
}
}
launch.json的配置如下:
{
"type": "java",
"name": "CodeLens (Launch) - Algorithm",
"request": "launch",
"cwd": "${workspaceFolder}",
"console": "integratedTerminal",
"encoding": "GBK", // 设置为JDK为GBK
"stopOnEntry": false,
"mainClass": "${fileBasenameNoExtensio.${fileBasenameNoExtension}",
"args": ""
}
这是原本的解决方案,运行后可以看到中文(你好世界)并没有输出:
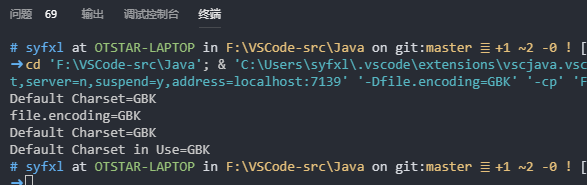
通过chcp命令查询字符集,发现终端的字符集使用的是UTF-8:
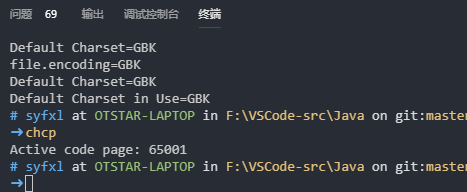
将字符集全部java文件的编码和launch.json的encoding更改为UTF-8后出现乱码:
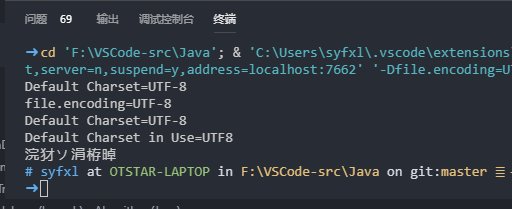
这个编码是UTF-8转为GBK造成的,如果我们将文件更改为GBK编码呢?
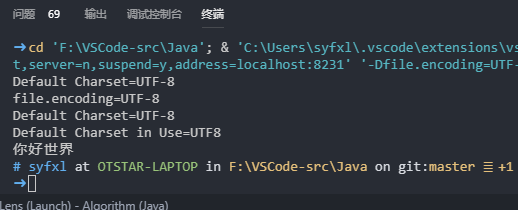
从上面可以看到终端正确输出了中文,但是这个方案并不是很好,如果你需要将代码转移到Linux等基于UTF-8编码的系统中就会发现代码需要重新转编码才能继续使用,那如果我们将文件设置为UTF-8编码,而encoding设置为GBK呢?
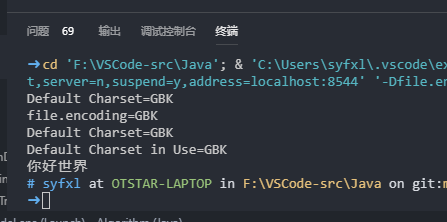
可以看到终端也成功出现了中文,而文件也不用更改为GBK编码,上传到Git上或者Linux系统中就不会出现乱码的问题了。
注意:如果console设置为internalConsole则需要使用第一种方式,即文件使用GBK,encoding设置为UTF-8。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

