你应该了解的一些Tomcat基本概念
Tomcat是开源的 Java Web 应用服务器,实现了 Java EE(Java Platform Enterprise Edition)的部 分技术规范,比如 Java Servlet、Java Server Page、JSTL、Java WebSocket。Java EE 是 Sun 公 司为企业级应用推出的标准平台,定义了一系列用于企业级开发的技术规范,除了上述的之外,还有 EJB、Java Mail、JPA、JTA、JMS 等,而这些都依赖具体容器的实现。
其他的一些Web服务器

目录结构
这些是一些关键的tomcat目录:
- / bin -Startup, shutdown和其他脚本。windows为
*.bat文件,linux为*.sh文件。 - / conf -配置文件和相关的DTDs。这里最重要的文件是server.xml。它是容器的主要配置文件。
- / logs -日志文件默认位于此处。
- / webapps -这是您的webapp所在的位置。

工作流程
当客户请求某个资源时,Servlet 容器使用 ServletRequest 对象把客户的请求信息封装起 来,然后调用 Java Servlet API 中定义的 Servlet 的一些生命周期方法,完成 Servlet 的执行, 接着把 Servlet 执行的要返回给客户的结果封装到 ServletResponse 对象中,最后 Servlet 容 器把客户的请求发送给客户,完成为客户的一次服务过程。
组织架构
Tomcat是一个基于组件的服务器,它的构成组件都是可配置的,其中最外层的是Catalina servlet容器,其他组件按照一定的格式要求配置在这个顶层容器中。
Tomcat的各种组件都是在Tomcat安装目录下的/conf/server.xml文件中配置的。
<Server> //顶层类元素,可以包括多个Service
<Service> //顶层类元素,可包含一个Engine,多个Connecter
<Connector> //连接器类元素,代表通信接口
<Engine> //容器类元素,为特定的Service组件处理客户请求,要包含多个Host
<Host> //容器类元素,为特定的虚拟主机组件处理客户请求,可包含多个Context
<Context> //容器类元素,为特定的Web应用处理所有的客户请求
</Context>
</Host>
</Engine>
</Connector>
</Service>
</Server>
复制代码
所以,tomcat的体系结构如下:
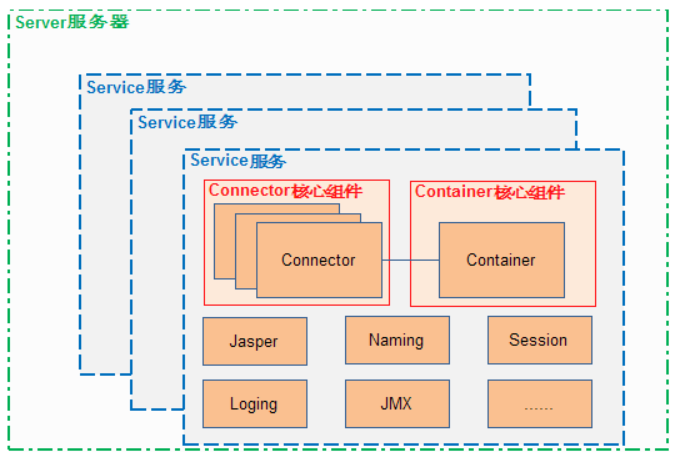
由上图可看出Tomca的心脏是两个组件:Connecter和Container。一个Container可以选择多个Connecter,多个Connector和一个Container就形成了一个Service。Service可以对外提供服务,而Server服务器控制整个Tomcat的生命周期。
容器
Servlet容器处理客户端的请求并填充response对象。Servlet容器实现了Container接口。在Tomcat中有4种级别的容器:Engine,Host,Context和Wrapper。
Engine:表示整个Catalina Servlet引擎;
Host:包含一个或多个Context容器的虚拟主机;
Context:表示一个Web应用程序,可以包含多个Wrapper;
Wrapper:表示一个独立的Servlet;
4个层级接口的标准实现分别是:StandardEngine类,StandardHost类,StandardContext类和StandardWrapper类。它们在org.apache.catalina.core包下。
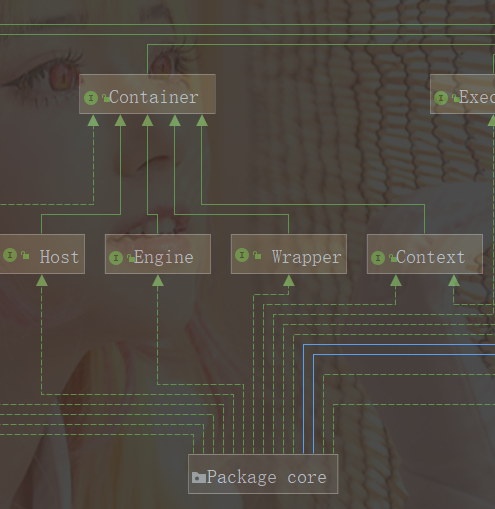
Engine
Engine
Engine是表示整个Catalina Servlet引擎的容器。它在以下类型的场景中很有用:
1)希望使用拦截器来查看整个引擎的每个处理请求。
2)希望使用独立的http连接器运行catalina,但仍希望支持多个虚拟主机。
通常,在部署连接到web服务器(如apache)的catalina时,您不会使用引擎,因为连接器将利用web服务器的功能来确定应该使用哪个上下文(甚至可能是哪个Wrapper)来处理此请求。
附加到Engine的子容器通常是Host(表示虚拟Host)或上下文(表示单个servlet上下文)的实现,具体取决于Engine实现。
如果使用,Engine始终是catalina层次结构中的顶级容器。因此,实现的setParent()方法应该抛出IllegalArgumentException。
Host
Host是一个容器,表示Catalina Servlet引擎中的虚拟Host。它在以下类型的场景中很有用:
1)希望使用Interceptors来查看此特定虚拟Host处理的每个请求。
2)希望使用独立的http连接器运行catalina,但仍希望支持多个虚拟主机。
通常,在部署连接到web服务器(如apache)的catalina时,您不会使用Host,因为连接器将利用web服务器的功能来确定应该使用哪个上下文(甚至可能是哪个Wrapper)来处理此请求。
Host的父容器通常是一个Engine,但可能是其他一些实现,或者在不需要时可以省略。
主机的子容器通常是Context(表示单个servlet上下文)。
Context
Context是一个容器,表示catalina servlet引擎中的一个servlet上下文,因此是一个单独的web应用程序。
因此,它在catalina的几乎所有部署中都很有用(即使连接到web服务器(如apache)的连接器使用web服务器的工具来标识处理此请求的适当Wrapper也是如此。
它还提供了一种使用拦截器的方便机制,拦截器可以查看这个特定web应用程序处理的每个请求。
上下文的父容器通常是Host,但可能是其他一些实现,或者在不需要时可以省略。
上下文的子容器通常是Wrapper的实现(表示单个servlet定义)。
Wrapper
Wrapper是一个容器,它表示来自web应用程序的部署描述符的一个单独的servlet定义。它提供了一种方便的机制来使用拦截器,拦截器可以看到这个定义所表示的对servlet的每个请求。
wrapper的实现负责管理其底层servlet类的servlet生命周期,包括在适当的时候调用init()和destroy(),以及考虑servlet类本身是否存在单线程模型声明。
Wrapper的父容器通常是context的实现,表示这个servlet在其中执行的servlet上下文(因此是web应用程序)。
Wrapper实现上不允许使用子容器,因此 addChild() 方法应该抛出 illegalargumentexception 。
Pipeline
每个管道上面都有阀门, Pipeline 和 Valve 关系也是一样的。 Valve 代表管道上的阀门,可以控制管道的流向,当然每个管道上可以有多个阀门。如果把 Pipeline 比作公路的话,那么 Valve 可以理解为公路上的收费站,车代表 Pipeline 中的内容,那么每个收费站都会对其中的内容做一些处理(收费,查证件等)。
Pipeline描述在调用 invoke() 方法时应按顺序执行的阀集合的接口。要求管道中的某个阀门(通常是最后一个)必须处理请求并创建相应的响应,而不是试图传递请求。
通常有一个单独的管道实例与每个容器相关联。容器的正常请求处理功能通常封装在容器特定的阀门中,该阀门应始终在管道的末端执行。为了实现这一点,官方提供了 setbasic() 方法来设置总是最后执行的valve实例。在执行基础阀之前,将按照添加顺序执行其他阀门。
基础阀的作用是连接当前容器的下一个容器(通常是自己的自容器),可以说基础阀是两个容器之间的桥梁。运行图如下:
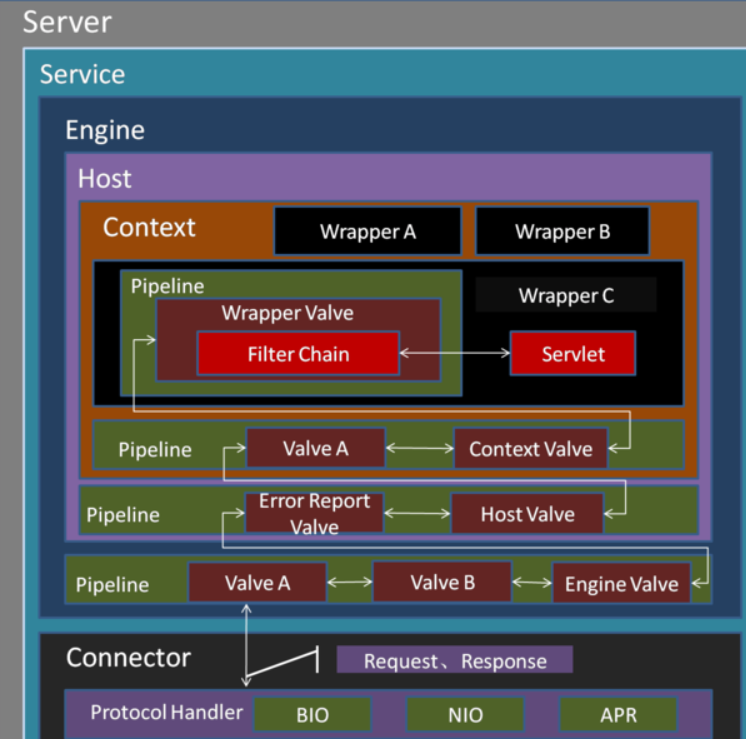
Pipeline 上可以有多个
Valve ,每个
Valve 都可以做一些操作,无论是
Pipeline 还是
Valve 操作的都是
Request 和
Response 。而在容器之间
Pipeline 和
Valve
则起到了桥梁的作用。
源码剖析
1)Valve
package org.apache.catalina;
import java.io.IOException;
import javax.servlet.ServletException;
import org.apache.catalina.connector.Request;
import org.apache.catalina.connector.Response;
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void backgroundProcess();
public void invoke(Request request, Response response)
throws IOException, ServletException;
public boolean isAsyncSupported();
}
复制代码
方法并不是很多,首先,Pipeline上有许多valve,这些valve存放的方式更像是链表,当获取到一个valve实例时,可以通过getNext()获取下一个。setNext则是设置当前valve的下一个valve实例。
2)Pipeline
package org.apache.catalina;
import java.util.Set;
public interface Pipeline extends Contained {
public Valve getBasic();
public void setBasic(Valve valve);
public void addValve(Valve valve);
public Valve[] getValves();
public void removeValve(Valve valve);
public Valve getFirst();
public boolean isAsyncSupported();
public void findNonAsyncValves(Set<String> result);
}
复制代码
可以看出 Pipeline 中很多的方法都是操作 Valve 的,包括获取,设置,移除 Valve , getFirst() 返回的是 Pipeline 上的第一个 Valve ,而 getBasic() , setBasic() 则是获取/设置基础阀,我们都知道在 Pipeline 中,每个 pipeline 至少都有一个阀门,叫做基础阀,而 getBasic() , setBasic() 则是操作基础阀的。
接下来 ,我们看实现类 StandardPipeline 的几个重要方法。
1:startInternal
protected synchronized void startInternal() throws LifecycleException {
// Start the Valves in our pipeline (including the basic), if any
Valve current = first;
if (current == null) {
current = basic;
}
while (current != null) {
if (current instanceof Lifecycle)
((Lifecycle) current).start();
current = current.getNext();
}
setState(LifecycleState.STARTING);
}
复制代码
组件的 start() 方法,将 first (第一个阀门)赋值给 current 变量,如果 current 为空,就将 basic (也就是基础阀)赋值给 current ,接下来遍历单向链表,调用每个对象的 start() 方法,最后将组件( pipeline )状态设置为 STARTING (启动中)。
2:setBasic
public void setBasic(Valve valve) { // 只有必要时才会改变 Valve oldBasic = this.basic; if (oldBasic == valve) return; // 条件符合的话,停止旧的基础阀 if (oldBasic != null) { if (getState().isAvailable() && (oldBasic instanceof Lifecycle)) { try { ((Lifecycle) oldBasic).stop(); } catch (LifecycleException e) { log.error(sm.getString("standardPipeline.basic.stop"), e); } } if (oldBasic instanceof Contained) { try { ((Contained) oldBasic).setContainer(null); } catch (Throwable t) { ExceptionUtils.handleThrowable(t); } } } // 条件符合的话,开启valve if (valve == null) return; if (valve instanceof Contained) { ((Contained) valve).setContainer(this.container); } if (getState().isAvailable() && valve instanceof Lifecycle) { try { ((Lifecycle) valve).start(); } catch (LifecycleException e) { log.error(sm.getString("standardPipeline.basic.start"), e); return; } } // 更新pipeline的阀 Valve current = first; while (current != null) { if (current.getNext() == oldBasic) { current.setNext(valve); break; } current = current.getNext(); } this.basic = valve; } 复制代码
这是用来设置基础阀的方法,这个方法在每个容器的构造函数中调用,代码逻辑也比较简单,稍微注意的地方就是阀门链表的遍历。
3:addValve
public void addValve(Valve valve) {
// 验证Valve 关联Container
if (valve instanceof Contained)
((Contained) valve).setContainer(this.container);
// 如果符合条件,就启动valve
if (getState().isAvailable()) {
if (valve instanceof Lifecycle) {
try {
((Lifecycle) valve).start();
} catch (LifecycleException e) {
log.error(sm.getString("standardPipeline.valve.start"), e);
}
}
// 如果first为空,就将valve赋值给first,并将下个valve设置为基础阀(因为为空说明只有一个基础阀)
if (first == null) {
first = valve;
valve.setNext(basic);
} else {
// 遍历阀门链表,将valve设置在基础阀之前
Valve current = first;
while (current != null) {
if (current.getNext() == basic) {
current.setNext(valve);
valve.setNext(basic);
break;
}
current = current.getNext();
}
//触发添加事件
container.fireContainerEvent(Container.ADD_VALVE_EVENT, valve);
}
复制代码
这方法是像容器中添加 Valve ,在 server.xml 解析的时候也会调用该方法。
4:getValves
public Valve[] getValves() { List<Valve> valveList = new ArrayList<>(); Valve current = first; if (current == null) { current = basic; } while (current != null) { valveList.add(current); current = current.getNext(); } return valveList.toArray(new Valve[0]); } 复制代码
获取所有的阀门,其实就是将阀门链表添加到一个集合内,最后转成数组返回。
5:removeValve
public void removeValve(Valve valve) {
Valve current;
// 如果first是要被删除的结点,那么将first指向下一位,current置空
if(first == valve) {
first = first.getNext();
current = null;
} else {
// 将current指向first
current = first;
}
while (current != null) {
// 类似链表删除,将要被删除的valve前一位指向它的后一位(valve不会是first)
if (current.getNext() == valve) {
current.setNext(valve.getNext());
break;
}
current = current.getNext();
}
// 如果first==basic,first置空。first严格定义是 除了基础阀的第一个阀门。
if (first == basic) first = null;
if (valve instanceof Contained)
((Contained) valve).setContainer(null);
// 停用并销毁valve
if (valve instanceof Lifecycle) {
// Stop this valve if necessary
if (getState().isAvailable()) {
try {
((Lifecycle) valve).stop();
} catch (LifecycleException e) {
log.error(sm.getString("standardPipeline.valve.stop"), e);
}
}
try {
((Lifecycle) valve).destroy();
} catch (LifecycleException e) {
log.error(sm.getString("standardPipeline.valve.destroy"), e);
}
}
// 触发container的移除valve事件
container.fireContainerEvent(Container.REMOVE_VALVE_EVENT, valve);
}
复制代码
它用来删除指定的valve,在destroyInternal方法中被调用。
6:getFirst
public Valve getFirst() { if (first != null) { return first; } return basic; } 复制代码
在方法5中我们也看到了, first 指向的是容器第一个非基础阀门的阀门,从方法6中也可以看出来, first 在只有一个基础阀的时候并不会指向基础阀,因为如果指向基础阀的话就不需要判断非空然后返回基础阀了,这是个需要注意的点!
AccessLog
用于valve以指示valve提供访问日志记录。tomcat内部使用它来标识记录访问请求的阀门,以便在处理链的早期被拒绝的请求仍然可以添加到访问日志中。
此接口的实现应该是健壮的,以防提供的request和response对象为空、具有空属性或任何其他“异常”,这些“异常”可能是由于试图记录一个几乎肯定被拒绝的请求,因为该请求的格式不正确。
其中,AccessLog的配置可以在server.xml的Host中找到:
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> <!-- SingleSignOn valve, share authentication between web applications Documentation at: /docs/config/valve.html --> <!-- <Valve className="org.apache.catalina.authenticator.SingleSignOn" /> --> <!-- Access log processes all example. Documentation at: /docs/config/valve.html Note: The pattern used is equivalent to using pattern="common" --> <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access_log" suffix=".txt" pattern="%h %l %u %t "%r" %s %b" /> </Host> 复制代码
Access Log Valve用来创建日志文件,它可以与任何Catalina容器关联,记录该容器处理的所有请求。输出文件将放在由directory属性指定的目录中。文件名由配置的前缀、时间戳和后缀的串联组成。文件名中时间戳的格式可以使用filedateformat属性设置。如果通过将rotatable设置为false来关闭文件旋转,则将省略此时间戳。pattern项的修改,可以改变日志输出的内容。
参数/选项说明:
| 参数 | 含义 |
|---|---|
| className | 实现的java类名,必须设置成org.apache.catalina.valves.AccessLogValve |
| directory | 存放日志文件的目录,如果指定了相对路径,则会将其解释为相对于 catalina_base)。 |
| pattern | 需要记录的日志信息的格式布局,如果是”common”或者”combined”,说明是使用的标准记录格式,也有自定义的格式,下面会详细说明 |
| prefix | 日志文件名的前缀,如果没有指定,缺省值是”access_log.;(要注意后面有个小点) |
| resolveHosts | 将远端主机的IP通过DNS查询转换成主机名,设为true。如果为false,忽略DNS查询,报告远端主机的IP地址 |
| sufix | 日志文件的后缀名。(sufix=”.log”);也需要注意有个小点 |
| rotatable | 缺省值为true,决定日志是否要翻转,如果为false则永不翻转,并且忽略fileDateFormat,谨慎使用。 |
| condition | 打开条件日志 |
| fileDateFormat | 允许在日志文件名称中使用定制的日期格式。日志的格式也决定了日志文件翻转的频率。 |
Pattern:
%a 远端IP %A 本地IP %b 发送的字节数,不包含HTTP头,如果为0,使用”-” %B 发送的字节数,不包含HTTP头 %h 远端主机名(如果resolveHosts=false),远端的IP %H 请求协议 %l 从identd返回的远端逻辑用户名,总是返回’-’ %m 请求的方法 %p 收到请求的本地端口号 %q 查询字符串 %r 请求的第一行 %s 响应的状态码 %S 用户的sessionID %t 日志和时间,使用通常的log格式 %u 认证以后的远端用户(如果存在的话,否则为’-’) %U 请求的URI路径 %v 本地服务器的名称 %D 处理请求的时间,以毫秒为单位 %T 处理请求的时间,以秒为单位
Realm
首先说一下什么是Realm,可以把它理解成“域”,也可以理解成“组”,因为它类似 类Unix系统 中组的概念。
Realm域提供了一种用户密码与web应用的映射关系。
因为tomcat中可以同时部署多个应用,因此并不是每个管理者都有权限去访问或者使用这些应用,因此出现了用户的概念。但是想想,如果每个应用都去配置具有权限的用户,那是一件很麻烦的事情,因此出现了role这样一个概念。具有某一角色,就可以访问该角色对应的应用,从而达到一种域的效果。
每个用户我们可以设置不同的角色(在tomcat-users.xml中配置)。
每个应用中会设定可以访问的角色(在web.xml中配置)。
当tomcat启动后,就会通过Realm进行验证(在server.xml中配置),通过验证才可以访问该应用,从而达到角色安全管理的作用。
server.xml
<Realm className="org.apache.catalina.realm.LockOutRealm"> <!-- This Realm uses the UserDatabase configured in the global JNDI resources under the key "UserDatabase". Any edits that are performed against this UserDatabase are immediately available for use by the Realm. --> <Realm className="org.apache.catalina.realm.UserDatabaseRealm" resourceName="UserDatabase"/> </Realm> 复制代码
默认情况下,Realm的配置位置是在Engine标签内部,并且使用的是UserDatabase的方式。其他的方式会在下面部分说明。
其中Realm的不同位置也会影响到它作用的范围。
1 、在元素内部 —— Realm将会被所有的虚拟主机上的web应用共享,除非它被或者元素内部的Realm元素重写。 2 、在元素内部 —— 这个Realm将会被本地的虚拟主机中的所有的web应用共享,除非被元素内部的Realm元素重写。 3 、在元素内部 —— 这个Realm元素仅仅被该Context指定的应用使用。
配置
1)配置server.xml

上图中的代码配置了UserDatabase的目录文件,为conf/tomcat-users.xml。
2)在tomcat-users.xml中配置用户密码以及分配角色
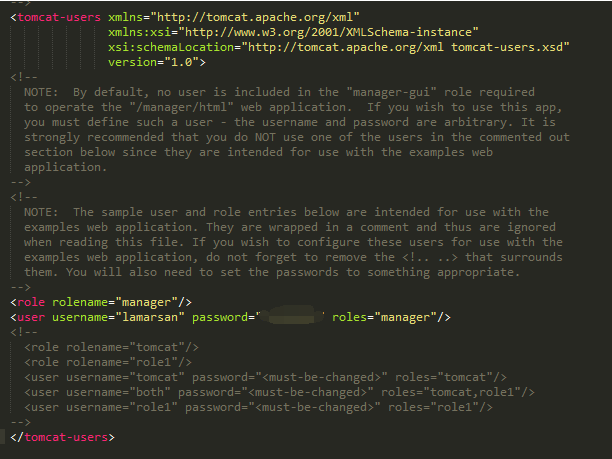
3)在应用的web.xml中配置访问角色以及安全限制的内容
<security-constraint>
<web-resource-collection>
<web-resource-name>HTML Manager interface (for humans)</web-resource-name>
<url-pattern>/html/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>manager-gui</role-name>
</auth-constraint>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Text Manager interface (for scripts)</web-resource-name>
<url-pattern>/text/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>manager-script</role-name>
</auth-constraint>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>JMX Proxy interface</web-resource-name>
<url-pattern>/jmxproxy/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>manager-jmx</role-name>
</auth-constraint>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Status interface</web-resource-name>
<url-pattern>/status/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>manager-gui</role-name>
<role-name>manager-script</role-name>
<role-name>manager-jmx</role-name>
<role-name>manager-status</role-name>
</auth-constraint>
</security-constraint>
<!-- Define the Login Configuration for this Application -->
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>Tomcat Manager Application</realm-name>
</login-config>
<!-- Security roles referenced by this web application -->
<security-role>
<description>
The role that is required to access the HTML Manager pages
</description>
<role-name>manager-gui</role-name>
</security-role>
<security-role>
<description>
The role that is required to access the text Manager pages
</description>
<role-name>manager-script</role-name>
</security-role>
<security-role>
<description>
The role that is required to access the HTML JMX Proxy
</description>
<role-name>manager-jmx</role-name>
</security-role>
<security-role>
<description>
The role that is required to access to the Manager Status pages
</description>
<role-name>manager-status</role-name>
</security-role>
复制代码
这是manager项目中的web.xml中的内容,其中,role-name定义了可以访问的角色。其他内容中上面定义了限制访问的资源,下面的Login-config比较重要。
它定义了验证的方式,BASIC就是基本的弹出对话框输入用户名密码。还是DIGEST方式,这种方式会对网络中的传输信息进行加密,更安全。
正文到此结束
- 本文标签: ip 开发 cat http ORM 服务器 时间 synchronized 端口 XML 企业 linux UI Enterprise 希望 源码 HTML tomcat 参数 线程 主机 Service web 代码 ArrayList windows 实例 DNS Webapps 配置 ACE MQ 定制 App 部署 servlet 组织 description core Security apache API session tab Document js Java类 安装 生命 Collection 协议 CTO 加密 mail list find src java 管理 JMS 模型 unix 遍历 https 开源 安全 删除 IO ssl CEO Proxy db key tar example 目录 IDE JPA id 认证 解析
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

