HashMap在多线程下不安全问题(JDK1.7)
- 多线程put操作后,get操作导致死循环。
- 多线程put操作,导致元素丢失。
死循环场景重现
public class HashMapTest extends Thread { private static HashMap<Integer, Integer> map = new HashMap<>(2); private static AtomicInteger at = new AtomicInteger(); @Override public void run() { while (at.get() < 1000000) { map.put(at.get(), at.get()); at.incrementAndGet(); } } public static void main(String[] args) { HashMapTest t0 = new HashMapTest(); HashMapTest t1 = new HashMapTest(); HashMapTest t2 = new HashMapTest(); HashMapTest t3 = new HashMapTest(); HashMapTest t4 = new HashMapTest(); HashMapTest t5 = new HashMapTest(); t0.start(); t1.start(); t2.start(); t3.start(); t4.start(); t5.start(); for (int i = 0; i < 1000000; i++) { Integer integer = map.get(i); System.out.println(integer); } } } 复制代码
反复执行几次,出现这种情况则表示死循环了:

由上可知,Thread-7由于HashMap的扩容导致了死循环。
HashMap分析
扩关键容源码
1 void transfer(Entry[] newTable, boolean rehash) { 2 int newCapacity = newTable.length; 3 for (Entry<K,V> e : table) { 4 while(null != e) { 5 Entry<K,V> next = e.next; 6 if (rehash) { 7 e.hash = null == e.key ? 0 : hash(e.key); 8 } 9 int i = indexFor(e.hash, newCapacity); 10 e.next = newTable[i]; 11 newTable[i] = e; 12 e = next; 13 } 14 } 15 } 复制代码
正常的扩容过程
我们先来看下单线程情况下,正常的rehash过程:
- 假设我们的hash算法是简单的key mod一下表的大小(即数组的长度)。
- 最上面是old hash表,其中HASH表的size=2,所以key=3,5,7在mod 2 以后都冲突在table[1]这个位置上了。
- 接下来HASH表扩容,resize=4,然后所有的<key,value>重新进行散列分布,过程如下:
在单线程情况下,一切看起来都很美妙,扩容过程也相当顺利。接下来看下并发情况下的扩容。
并发情况下的扩容
-
有两个线程,分别用红色和蓝色标注了。
-
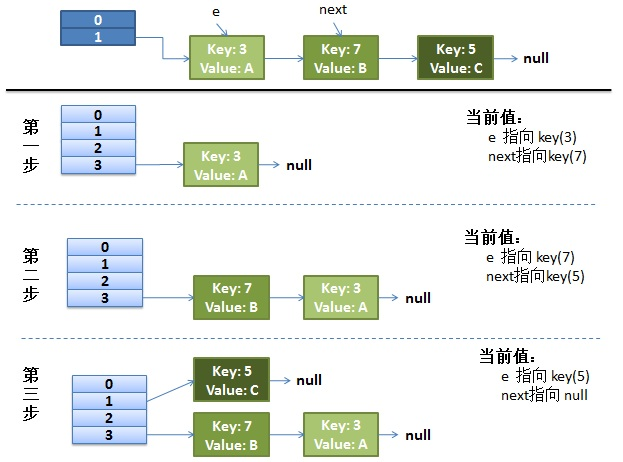
在线程1执行到第5行代码就被CPU调度挂起(执行完了,获取到next是7),去执行线程2,且线程2把上面代码都执行完毕。我们来看看这个时候的状态
- 接着CPU切换到线程1上来,执行4-12行代码(已经执行完了第五行),首先安置健值为3这个Entry:
注意::线程二已经完成执行完成,现在table里面所有的Entry都是最新的,就是说7的next是3,3的next是null;现在第一次循环已经结束,3已经安置妥当。
-
看看接下来会发生什么事情:
- e=next=7;
- e!=null,循环继续
- next=e.next=3
- e.next 7的next指向3
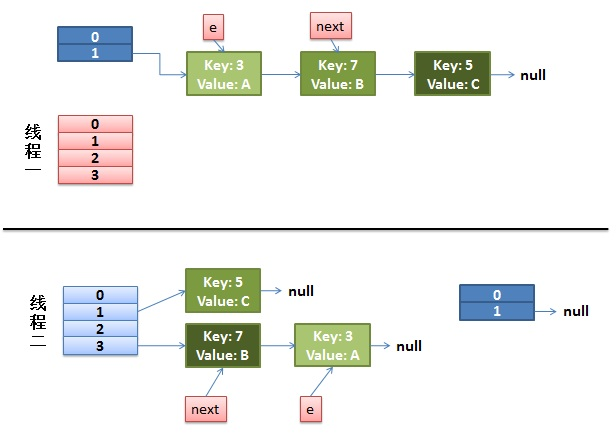
- 放置7这个Entry,现在如图所示:
-
放置7之后,接着运行代码:
- e=next=3;
- 判断不为空,继续循环
- next= e.next 这里也就是3的next 为null
- e.next=7,就3的next指向7.
- 放置3这个Entry,此时的状态如图
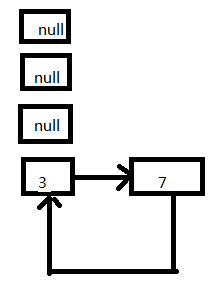
这个时候其实就出现了死循环了,3移动节点头的位置,指向7这个Entry;在这之前7的next同时也指向了3这个Entry。
- 代码接着往下执行,e=next=null,此时条件判断会终止循环。这次扩容结束了。但是后续如果有查询(无论是查询的迭代还是扩容),都会hang死在table[3]这个位置上。现在回过来看文章开头的那个Demo,就是挂死在扩容阶段的transfer这个方法上面。
出现问题的关键原因: 如果扩容前相邻的两个Entry在扩容后还是分配到相同的table位置上,就会出现死循环的BUG 。在复杂的生产环境中,这种情况尽管不常见,但是可能会碰到。
多线程put操作,导致元素丢失
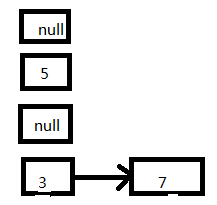
下面来介绍下元素丢失的问题。这次我们选取3、5、7的顺序来演示:
- 如果在线程一执行到第5行代码就被CPU调度挂起:
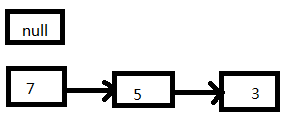
- 线程二执行完成:
- 这个时候接着执行线程一,首先放置7这个Entry:

- 再放置5这个Entry:

- 由于5的next为null,此时扩容动作结束,导致3这个Entry丢失。
JDK 8 的改进
JDK 8 中采用的是位桶 + 链表/红黑树的方式,当某个位桶的链表的长度超过 8 的时候,这个链表就将转换成红黑树
HashMap 不会因为多线程 put 导致死循环(JDK 8 用 head 和 tail 来保证链表的顺序和之前一样;JDK 7 rehash 会倒置链表元素),但是还会有数据丢失等弊端(并发本身的问题)。因此多线程情况下还是建议使用 ConcurrentHashMap
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

