什么样的代码是好代码?

关于什么是好代码,软件行业烂大街的名词一大堆,什么高内聚、低耦合、可复用、可扩展、健壮性等等。也有所谓设计6原则—SOLID:
即Single Responsibility (单一职责),Open Close(开闭), Liskov Substitution(里氏替换),Interface Segregation(接口隔离),Dependency Inversion(依赖反转)
详情可参考: https://www.cnblogs.com/huangenai/p/6219475.html
不喜欢这些抽象名词,我们搞点简单明了的。一匹跑得快(运行速度快),少生病(健壮),可以驮载各类货物(可扩展),容易辨识(容易看懂),病好治(bug好发现),高大英俊的千里汗血马是也

什么是好代码,不好定义,但是关于什么是代码里的 "坏味道" ,比较容易搞清楚,避免代码里的“坏味道",离好的代码就不远了,坏味道一二三及推荐做法:
- 代码重复
- 函数太长
如果太长(一般不宜超过200行,但不绝对),你自己都不太容易读懂,请不要犹豫,拆成小函数吧。笔者刚毕业,参与一个大型复杂的金融软件,核心业务类,函数1000行算小case,5000多行的不在少数,我的内心是哇凉哇凉的,还好大致逻辑比较清晰
- 类太大
一般不宜操过1000行,同样不绝对,jdk源码过千行的不少嘛。还是那个大型复杂的金融软件,核心的几个Algo C++文件,2万到3万行,我的心在滴血
- 数据泥团
即很多地方有相同的三四项,两个类中有相同的字段、许多函数签名中有相同的参数。把这些应该捆绑在一起的数据项,弄到一个新的类里吧。这样,函数参数列表会变短不少
- 函数参数列表太长
工作中有7个参数的函数调用,搞清楚每个参数的业务含意,和顺序有点头晕。尽管可能有默认函数参数,不小心的时候确实范过错误,后面直接引入一个线上bug,紧张
- 变量名、函数名称、类名、接口等命名含义不清晰
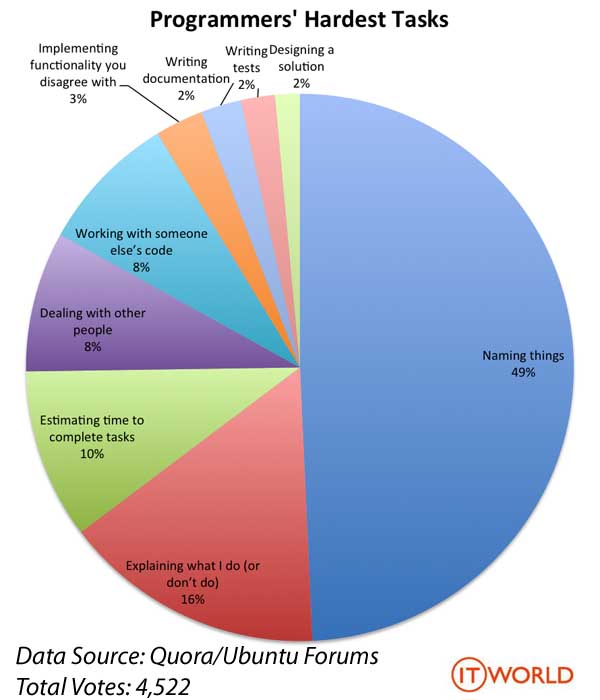
图02程序员最头疼的事
苦命的天朝程序员,还要把中文翻译为英文,我也很头大鸭。函数名能让人 望名知义 ,看名字就知道函数的功能是啥,以至于几乎不需要多少comments最好
通常DAO层函数的命令规范是:操作+对象+通过+啥,如: updateUserById, insertQuarter,delteteUserByName
- 太多的if else
- 在循环里定义大量耗资源的变量
大对象,如果可以放在循环外,被共享,推荐这么搞
- try 块代码太长
try块只包住真的可能发生异常的语句,最小原则,同样因为try包起来的代码要有额外开销
- 不用的资源未及时清理掉,流及时关闭
如IO句柄,数据库连接,网络连接等。不清理掉,后果很严重,你若不信,软件就死给你看

- try-finally丑陋,明显更爱try-with-resources
1)丑陋的
static String firstLineOfFile(String path) throws IOException{
BufferedReader br = new BufferedReader(new FileReader(path));
try {
return br.readLine();
} finally {
br.close();
}
}
2) 漂亮的小姐姐
static String firstLineOfFile(String path) throws IOException{
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
return br.readLine();
}
}
- 循环里字符串的拼接不要用”+“
有改过一个OutOfMemery的bug,字符串拼接用”+“,产生了一百多万的字符串变量。用Visual VM看程序占用内存空间比较多,数量最大的,通常都是String,所以用StringBuilder的append吧。
用Java VisualVM截取的一个dump,如下图:
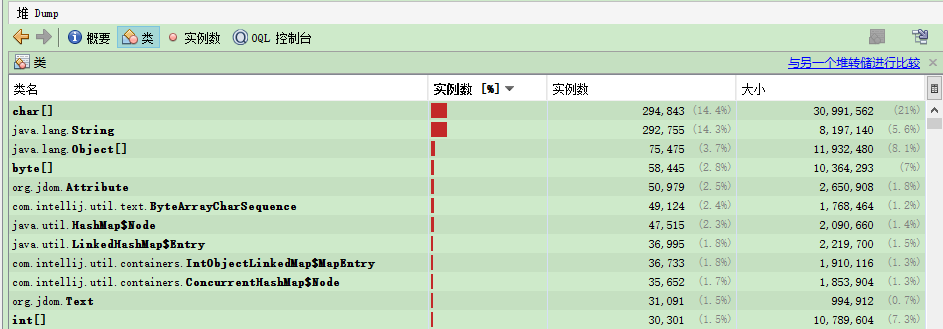
从中可以看出,字符char和字符串String 实例数 和 内存大小 占比都比较高。
- 太巨量的循环,看情况用乘除法和移位运算
移位运算吧,速度略微快于乘除法。测试代码如下:
int temp;
long before = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
temp = 2 * 8;
temp = 16 / 8;
}
long after = System.currentTimeMillis();
System.out.println(after - before);
before = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
temp = 2 << 3;
temp = 16 >> 3;
}
after = System.currentTimeMillis();
System.out.println(after - before);
运行结果,分别为{269,279 }、 {258, 317}millionSeconds,惊不惊喜,意不意外,乘除法比移位运算更快。看了下stackoverflow,具体得看处理器,现代处理器好多对于乘除已作优化
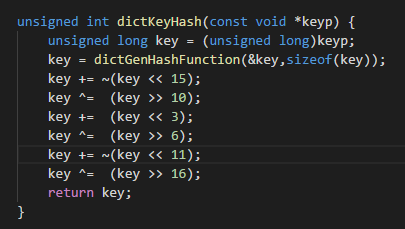
参看redis rehashing.c hash key计算的代码片段,因为hash key的计算会高频度用到
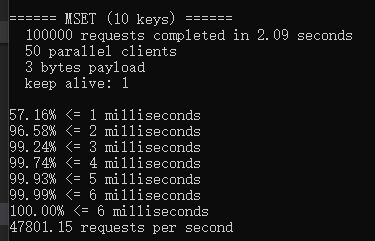
看下redis-benchmark基准测试的数据,写Set = 47801/Sencond,12年的老电脑(Intel i5-2450M, 2.50GHz),速度很可观,应该是代码写的牛逼加C本身执行效率较高
参考: https://stackoverflow.com/questions/6357038/is-multiplication-and-division-using-shift-operators-in-c-actually-faster
- 避免运行时大量的反射
不知道Java社区为什么不太关注反射耗时的问题,以前写C#都会谨慎使用,C#社区有专门的讨论
- 基本类型优于装箱基本类型
基本类型更快,更省空间。避免不经意引起自动装箱和拆箱。是否相等的比较,"装箱基本类型"可能回出错
- 未作参数有效性检查
不搞这个, NullPointerException 等妥妥地
- 延迟初始化和懒加载
这个的确是一种优化,即需要用到它的值时,才初始化。如果永不用到,就永远不会被初始化。但要
- LinkedHashMap 、HashMap、ArrayList、HashSet、HashTable等集合类,没有初始化容量
如果大致知道业务场景下这些集合类的数量,初始化吧。如ArrayList默认 DEFAULT_CAPACITY = 10, resize代码如下:
newCapacity = oldCapacity + (oldCapacity >> 1);
如最终存放100个数据,则最后的容量 = ((10 + 10 * 2) * 2 + 30)) * 2 + 90 = 270, 会有4次重新分配内存和拷贝,费时间啊,我也懒,想耍啊
- 方法和类如果确实有业务场景需求不会被覆盖、不会被继承,用final修饰吧
final method在某些处理器下得到优化,跑得更快
参考: https://stackoverflow.com/questions/5547663/java-final-method-what-does-it-promise
- 合理数据库连接池和线程池
一个减少数据库连接的建立和断开(耗时),一个减少线程的创建和销毁,动态根据请求分配资源,提高资源利用率
- 多用buffer等缓冲提高输入输出IO效率及FileChannel.transferTo、FileChannel.transferFrom和FileChannnel.map
1) 诸如 BufferedReader 、BufferedWriter、BufferedInputStream 和 BufferedOutputStream 等
在杭电ACM online judge平台上,对于大数据量的输入和输出, BufferedReader 和 PrintWriter 的性能远高于 Scanner 和 printlin
参考: http://acm.hdu.edu.cn/faq.php?topic=java
2) FileChannel.transferXXX减少数据从内核到用户空间的复制,数据直接在内核空间中移动
FileChannel.map按照文件的一定大小块映射为内存区域,也不用从内核空间向用户空间拷贝数据 ,只适用于大文件的读操作
- synchronized修饰符最小作用域
synchronized要耗费性能,因此synchronized代码块优于synchronized方法,最小原则
- enum代替int枚举模式
int枚举模式不具有类型安全性,也没有啥子描述性,比较也会出问题
1)丑陋的
public static final int APPLE_FRUIT = 0;
public static final int APPLE_PIPPIN = 1;
public static final int APPLE_GRANNY_SMITH = 2;
public static final int ORANGE_NAVEL = 0;
public static final int ORANGE_TEMPLE = 1;
public static final int ORANGE_BLOOD = 2;
2)漂亮的小姐姐
public enum Apple { FRUIT, PIPPIN, GRANNY_SMITH }
public enum Orange { NAVEL, TEMPLE, BLOOD }
- 合理使用静态工厂方法代替构造器
如Boolean基本类
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
静态工厂方法,不必在每次调用时都创建一个新的对象;而且相较于构造器,它有名称,便于阅读和理解;同时可以返回原类型的任意子类型;也可以根据参数不同,返回不同的类对象,如EnumSet
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
}
- 组合优于继承
因为继承打破了封装性,overriding可能导致安全漏洞
- 异常只能用于处理错误,不能用来控制业务流程
未完待续,困了
注:
参考《Effective java》《重构 —— 改善既有代码的设计》《深入分析JAVA web技术内幕
*****************************************************************************************************
精力有限,想法太多,专注做好一件事就行
- 我只是一个程序猿。 5年内把代码写好,技术博客字字推敲,坚持零拷贝和原创
- 写博客的意义在于锻炼逻辑条理性,加深对知识的系统性理解,锻炼文笔,如果恰好又对别人有点帮助,那真是一件令人开心的事
*****************************************************************************************************

正文到此结束
- 本文标签: 金融 专注 HashSet Apple PHP 软件 数据库 线程池 HashTable 漏洞 HTML 源码 build map id stream 时间 web list ACE redis HashMap 程序员 测试 final 安全 IO 连接池 需求 update value https 博客 数据 集合类 App 中文翻译 参数 cat 处理器 synchronized 代码 java key ip http UI bug 空间 翻译 程序猿 线程 FAQ ArrayList 大数据 实例 tab src
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

