不知道如何实现服务的动态发现?快来看看 Dubbo 是如何做到的

上篇文章 如果有人问你 Dubbo 中注册中心工作原理,就把这篇文章给他 大致了解了注册中心作用以及 Dubbo Registry 模块源码,这篇文章将深入 Dubbo ZooKeeper 模块,去了解如何实现服务动态的发现。
ps: 以下将 ZooKeeper 缩写为 zk。
一、dubbo zk 数据结构
在 ZooKeeper 基本概念分享 一文讲道,ZK 内部是一种树形层次结构,节点存在多种类型。而 Dubbo 只会创建持久节点和临时节点。
若服务提供者服务接口为 com.service.FooService
,将会在 ZK 中创建创建如下路径 /dubbo/com.service.FooService/providers/providerURL
。
服务路径分为四层,根节点默认为 dubbo,可以在 dubbo-registry 设置 group 属性改变该值。
ps: 若无注册中心隔离需求,不要随便修改。
第二层节点为服务节点全名称,如 com.service.FooService
。
第三层节点为服务目录,如 providers。另外还存在其他目录节点,分别为 consumers(消费者目录),configurators(配置目录),routers(路由目录)。下面服务订阅主要针对这一层节点。
第四个节点为具体服务节点,节点名为具体的 URL 字符串,如 dubbo://2.0.1.13:12345/com.dubbo.example.DemoService?xx=xx
,该节点默认为临时节点。
dubbo ZK 树形内部结构示例为:
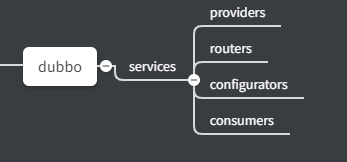
ZK 内部服务具体示例如下:

二、RegistryFactory 实现
Dubbo 可以在配置文件中指定使用注册中心,可以使用 dubbo.registry.protocol
指定具体注册中心类型,也可以设置 dubbo.registry.address
指定。注册中心相关实现将会使用 RegistryFactory
工厂类创建。
RegistryFactory
接口源码如下:
@SPI("dubbo") public interface RegistryFactory { @Adaptive({"protocol"}) Registry getRegistry(URL url); } 复制代码
RegistryFactory
接口方法使用 @Adaptive
注解,这里将会使用 Dubbo SPI 机制,自动生成代码的一些实现逻辑。这里将会根据 URL 中 protocol
属性,去调用最终实现子类。
RegistryFactory
实现子类如图所示:

AbstractRegistryFactory
将会实现接口的 getRegistry
方法,主要完成加锁,并调用抽象模板方法 createRegistry
创建具体注册中心实现类,并将其缓存在内存中。
AbstractRegistryFactory#getRegistry
源码如下所示:
public Registry getRegistry(URL url) { url = URLBuilder.from(url) .setPath(RegistryService.class.getName()) .addParameter(Constants.INTERFACE_KEY, RegistryService.class.getName()) .removeParameters(Constants.EXPORT_KEY, Constants.REFER_KEY) .build(); String key = url.toServiceStringWithoutResolving(); // 加锁,防止并发 LOCK.lock(); try { // 先从缓存中取 Registry registry = REGISTRIES.get(key); if (registry != null) { return registry; } //使用 Dubbo SPI 进制创建 registry = createRegistry(url); if (registry == null) { throw new IllegalStateException("Can not create registry " + url); } // 放入缓存 REGISTRIES.put(key, registry); return registry; } finally { // Release the lock LOCK.unlock(); } } 复制代码
注册中心实例将会通过具体工厂类创建,这里我们看下 ZookeeperRegistryFactory
源码:
public class ZookeeperRegistryFactory extends AbstractRegistryFactory { private ZookeeperTransporter zookeeperTransporter; /** * 通过 Dubbo SPI 进制注入 * @param zookeeperTransporter */ public void setZookeeperTransporter(ZookeeperTransporter zookeeperTransporter) { this.zookeeperTransporter = zookeeperTransporter; } @Override public Registry createRegistry(URL url) { return new ZookeeperRegistry(url, zookeeperTransporter); } } 复制代码
ps:Dubbo SPI 机制还具有 IOC 特性,这里的 ZookeeperTransporter
注入可以参考:Dubbo 扩展点加载
三、zk 模块源码解析
讲完注册中心实例创建过程,下面深入 ZookeeperRegistry
实现源码。
ZookeeperRegistry
继承 FailbackRegistry
抽象类,所以其需要实现其父类抽象模板方法,下面主要了解 doRegister
与 doSubscribe
源码 。
3.1 doRegister
服务提供者需要将服务注册到注册中心,注册的目的是为了让消费者感知到服务的存在,从而发起远程调用,另一方面也让服务治理中心感知新的服务提供者上线。zk 模块服务注册代码比较简单,直接使用 zk 客户端在注册中心创建节点。
ZookeeperRegistry#doRegister
实现源码如下:
public void doRegister(URL url) { try { zkClient.create(toUrlPath(url), url.getParameter(Constants.DYNAMIC_KEY, true)); } catch (Throwable e) { throw new RpcException("Failed to register " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e); } } 复制代码
zkClient.create
方法需要传入两个参数。
void create(String path, boolean ephemeral); 复制代码
第一个参数为节点路径,将会通过 toUrlPath
将 URL 实例转化成 ZK 中路径格式,转化结果如下:
## 转化前 URL 如下: dubbo://10.20.82.31:12345/com.dubbo.example.DemoService ## 调用 `toUrlPath` 转换之后 /dubbo/com.dubbo.example.DemoService/providers/dubbo%3A%2F%2F10.20.82.31%3A12345%2Fcom.dubbo.example.DemoService 复制代码
第二个参数主要决定 ZK 节点类型主要取自 URL 实例对象中 dynamic
参数值,若不存在,默认为 true
,也就是默认将会创建临时节点。
zkClient.create
方法里将会递归调用,首先父节点是否存在,不存在就会创建,直到最后一个节点跳出递归方法。
public void create(String path, boolean ephemeral) { // 创建永久节点之前需要判断是否已存在 if (!ephemeral) { if (checkExists(path)) { return; } } // 判断是否存在父节点 int i = path.lastIndexOf('/'); if (i > 0) { // 递归创建父节点 create(path.substring(0, i), false); } if (ephemeral) { // 创建临时节点 createEphemeral(path); } else { // 创建永久节点 createPersistent(path); } } 复制代码
最后 createEphemeral
与 createPersistent
实际创建节点操作将会交给 ZK 客户端类,这里实现比较简单,可以自行参考源码。
ps: dubbo 在 2.6.1 起将 zk 客户端默认使用 Curator,之前版本使用 zkclient。dubbo 2.7.1 开始去除 zkclient 实现,也就是说只能使用 Curator 。
3.2 为何 dubbo 服务提供者节点使用 zk 临时节点
zk 临时节点将会在 zk 客户端断开后,自动删除。dubbo 服务提供者正常下线,其会主动删除 zk 服务节点。
如果服务异常宕机,zk 服务节点就不能正常删除,这就导致失效的服务一直存在 ZK 上,消费者还会调用该失效节点,导致消费者报错。通过 zk 临时节点特性,让 zk 服务端主动删除失效节点,从而下线失效服务。
四、doSubscribe: 服务动态发现的原理
4.1 订阅基本原理
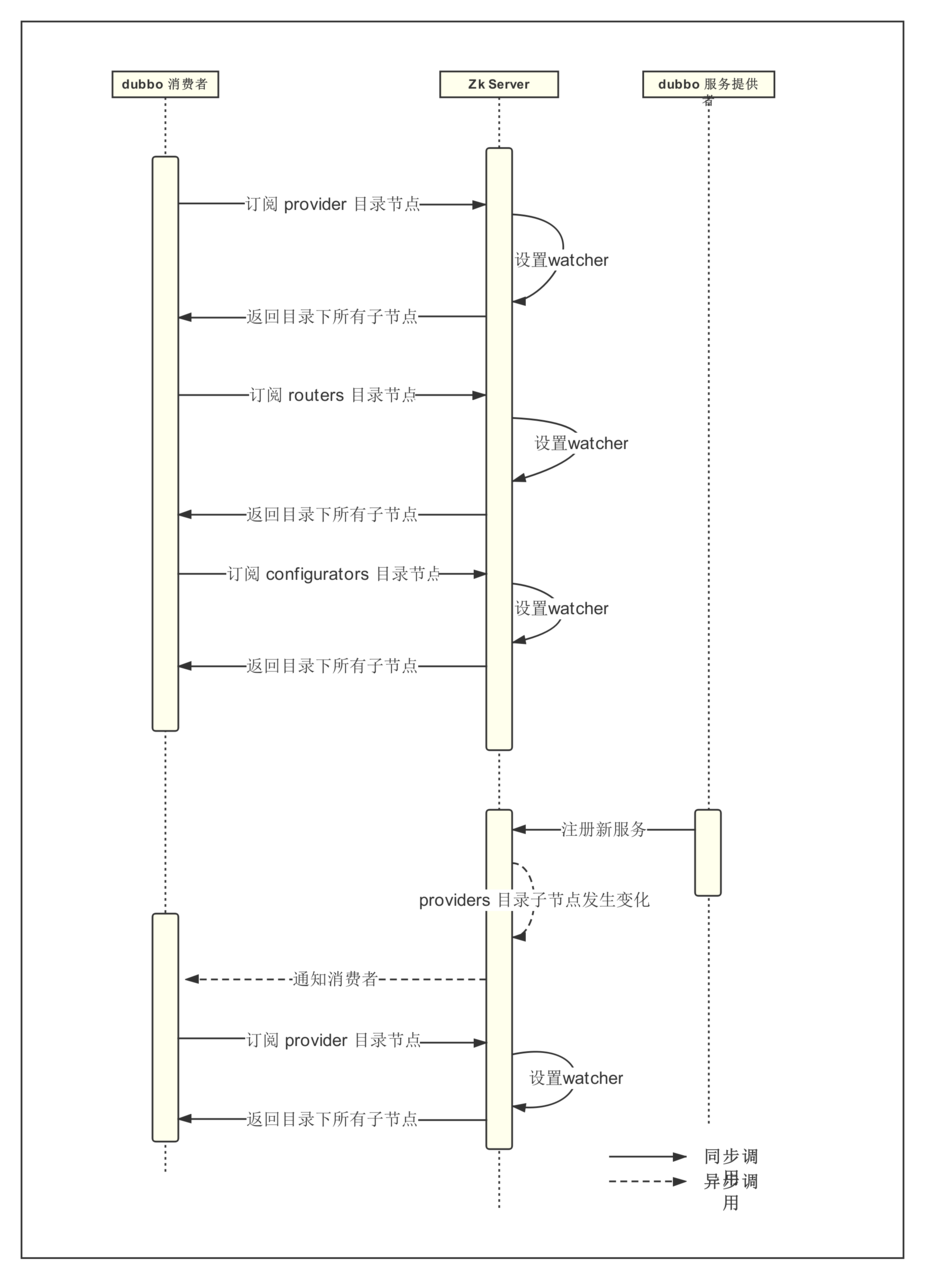
服务订阅通常有 pull 和 push 两种方式。pull 模式需要客户端定时向注册中心拉取配置,而 push 模式采用注册中心主动推送数据给客户端。
dubbo zk 注册中心采用是事件通知与客户端拉取方式。服务第一次订阅的时候将会拉取对应目录下全量数据,然后在订阅的节点注册一个 watcher。一旦目录节点下发生任何数据变化,zk 将会通过 watcher 通知客户端。客户端接到通知,将会重新拉取该目录下全量数据,并重新注册 watcher。利用这个模式,dubbo 服务就可以就做到服务的动态发现。
4.2 源码解析
讲完订阅的基本原理,接着深入源码。
doSubscribe
方法需要传入两个参数,一个为 URL 实例,另一个为 NotifyListener
,变更事件的监听器。 方法内部会根据 URL 接口类型分成两部分逻辑,全量订阅服务与部分类别订阅服务。
doSubscribe
方法整体源码逻辑:
public void doSubscribe(final URL url, final NotifyListener listener) { if (Constants.ANY_VALUE.equals(url.getServiceInterface())) { // 全量订阅逻辑 } else { // 部分类别订阅逻辑 } } 复制代码
服务治理中心(dubbo-admin),需要订阅 service 全量接口,用以感知每个服务的状态,所以订阅之前将会把 service 设置成 *,处理所有service。
服务消费者或服务提供者将会走部分类别订阅服务,下面我们以消费者视角,深入后续源码。
文章刚开头讲道了 zk 目录节点存在四种类型,这里将会根据 根据 URL 中 category
值,决定订阅节点路径。
服务提供者 URL 中 category
值默认为 configurators
,而消费者 URL 中 category
值默认为 providers,configurators,routers
。如果 category
类别值为 *
,将会订阅四种类别路径,否则将会只订阅 providers
类型的路径。
toCategoriesPath
源码如下:
private String[] toCategoriesPath(URL url) { String[] categories; // 如果类别为 *,订阅四种类型的全量数据 if (Constants.ANY_VALUE.equals(url.getParameter(Constants.CATEGORY_KEY))) { categories = new String[]{Constants.PROVIDERS_CATEGORY, Constants.CONSUMERS_CATEGORY, Constants.ROUTERS_CATEGORY, Constants.CONFIGURATORS_CATEGORY}; } else { categories = url.getParameter(Constants.CATEGORY_KEY, new String[]{Constants.DEFAULT_CATEGORY}); } // 返回路径数组 String[] paths = new String[categories.length]; for (int i = 0; i < categories.length; i++) { paths[i] = toServicePath(url) + Constants.PATH_SEPARATOR + categories[i]; } return paths; } 复制代码
接着循环路径数组,循环内将会缓存节点监听器,用以提高性能。
// 循环路径数组 for (String path : toCategoriesPath(url)) { ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.get(url); // listeners 缓存为空,创建缓存 if (listeners == null) { zkListeners.putIfAbsent(url, new ConcurrentHashMap<>()); listeners = zkListeners.get(url); } ChildListener zkListener = listeners.get(listener); // zkListener 缓存为空则创建缓存 if (zkListener == null) { listeners.putIfAbsent(listener, (parentPath, currentChilds) -> ZookeeperRegistry.this.notify(url, listener, toUrlsWithEmpty(url, parentPath, currentChilds))); zkListener = listeners.get(listener); } // 创建订阅节点 zkClient.create(path, false); // 使用 ZK 客户端订阅节点 List<String> children = zkClient.addChildListener(path, zkListener); if (children != null) { // 存储全量需要通知的 URL urls.addAll(toUrlsWithEmpty(url, path, children)); } } // 回调 NotifyListener notify(url, listener, urls); 复制代码
最终将会使用 CuratorClient.getChildren().usingWatcher(listener).forPath(path)
在 ZK 节点注册 watcher,并获取目录节点下所有子节点数据。
这里 watcher 使用 Curator 接口 CuratorWatcher
,一旦 ZK 节点发生会变化,将会回调 CuratorWatcher#process
方法。
CuratorWatcher#process
方法源码如下:
public void process(WatchedEvent event) throws Exception { if (childListener != null) { String path = event.getPath() == null ? "" : event.getPath(); childListener.childChanged(path, // 重新设置 watcher,并获取节点下所有子节点 StringUtils.isNotEmpty(path) ? client.getChildren().usingWatcher(this).forPath(path) : Collections.<String>emptyList()); } } 复制代码
消费者订阅时序图如下:
4.3 listener 关系图
订阅方法中我们碰到了多个 listener
类,刚开始理解时候可能有点乱。可以参考下面关系图理清楚这其中的关系。
listener
关系图如下:
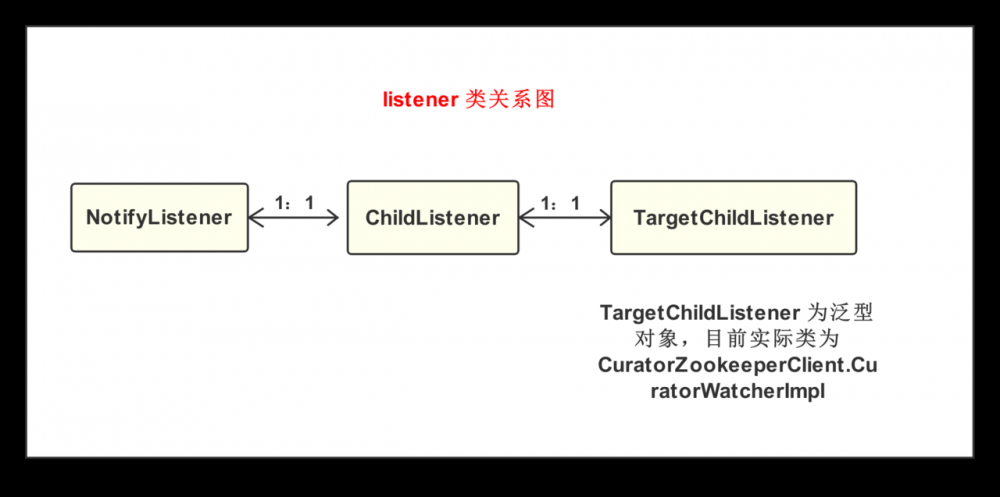
回调关系如图所示:

4.4 ZK 模块订阅存在问题
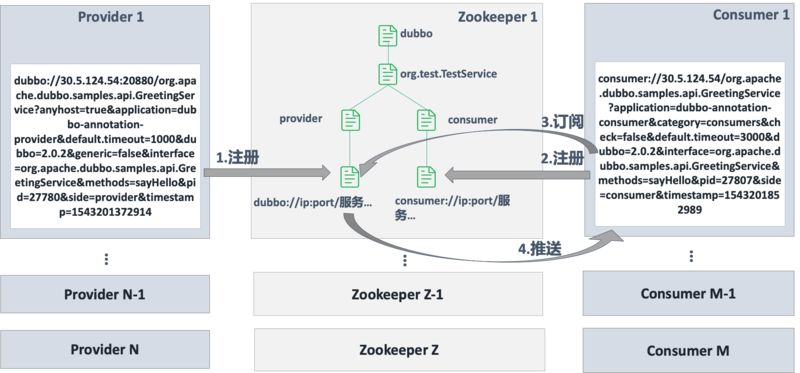
ZK 第一次订阅将会获得目录节点下所有子节点,后续任意子节点变更,将会通过 watcher 进制回调通知。回调通知将会再次全量拉取节点目录下所有子节点。这样全量拉取将会有个局限,当服务节点较多时将会对网络造成很大的压力。
Dubbo 2.7 之后版本引入元数据中心解决该问题,详情可参考, 阿里技术专家详解 Dubbo 实践,演进及未来规划 。
引用文中一种解决方案如下图:

正文到此结束
- 本文标签: https 数据 实例 dubbo 删除 constant 注册中心 category 源码 UI URLs final http Service id 并发 目录 配置 解析 锁 src Transport 服务端 Watcher map HTML 参数 client message 工作原理 缓存 zookeeper CTO list build 监听器 Collection equals cat 需求 value example Listeners IO ConcurrentHashMap 压力 代码 key consumer 文章 自动生成 HashMap IDE Collections provider ACE ioc 服务注册 递归
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

