微服务架构中缓存模式
在微服务世界中,每个人都使用缓存,缓存无处不在。缓存可以提高性能,减少后端负载,或者减少down机时间。有许多方法可以配置系统中的缓存,缓冲应该被放在系统的哪个层上?根据以往成功经验,系统中您应该只在一个地方使用缓存。不应该同时在多个层中组合模式和缓存,例如同样的内容在HTTP层和应用程序级别同时做缓存。这种方法可能导致更多的缓存失效问题,并使您的系统更容易出错,且难于调试。

如果您在一个特定的层上使用缓存,那么您可以选择使用哪种模式。最保守的方法是老式的客户机-服务器(或云)模式,这个问题的正确答案不止一个。您可以将缓存放在每个服务中,或者作为一个完全独立的缓存服务器。您还可以将它放在每个服务的前面,甚至作为属于服务的sidecar容器等等。本文下面,让我们总结一下您在微服务世界多种方式的缓存体系结构。
嵌入式缓存
最简单的缓存模式是嵌入式缓存。
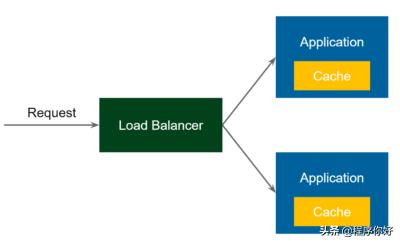
嵌入式缓存
在上图中,流程如下:
1.请求进入负载平衡器。
2.负载均衡器将请求转发给应用程序服务之一。
3.应用程序服务接收请求,并检查是否相同的请求已经执行(并存储在缓存)◦
如果是,然后返回缓存数据。反之,则执行业务操作,并把结果数据存储在缓存中,并返回结果数据。
业务操作可以是任何值得缓存的内容。例如,执行计算、查询数据库或调用外部web服务等。
这种缓存逻辑非常简单,我们可以使用内置的数据结构或一些缓存库(如Guava cache)为其快速编写代码。我们还可以将缓存放在应用程序层中,并使用大多数web框架提供的缓存功能。例如,对于Spring,添加缓存层只需要向方法添加@Cacheable注释。
嵌入式缓存方法有一个严重的问题。假设有一个向我们的系统发出的请求,它第一次被转发到顶部的应用程序服务A。然后,同样的请求出现,但这一次负载平衡器将其转发给底部的应用程序服务B。这种情况下,我们收到了两次相同的请求,但是必须执行两次业务逻辑,因为图中的两个缓存是分别完成的。为了处理这样的问题,可以使用嵌入分布式缓存。
嵌入分布式缓存
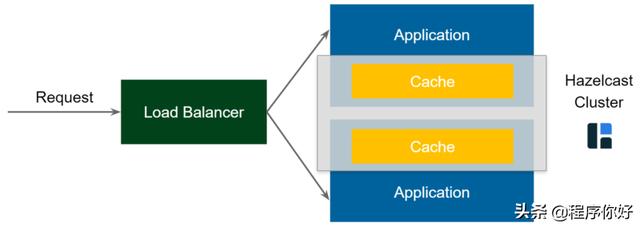
嵌入式分布式缓存仍然是嵌入式缓存的模式;但是,这一次我们将使用Hazelcast(Hazelcast 是由Hazelcast公司开发和维护的开源产品,可以为基于jvm环境运行的各种应用提供分布式集群和分布式缓存服务)而不是默认的非分布式缓存库。从现在开始,所有缓存(嵌入到所有应用程序中)形成一个分布式缓存集群。因为Hazelcast是用Java编写的,所以您可以将它与Spring一起使用;
您需要做的就是添加以下CacheManager配置。
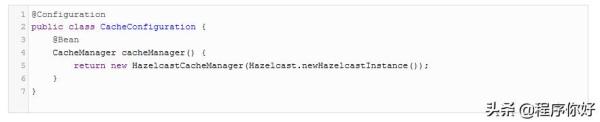
通过这几行代码,我们让Spring为它提供的所有缓存功能使用Hazelcast。
使用嵌入式缓存(分布式和非分布式)很简单,因为它不需要任何额外的配置或部署。而且,您总是可以获得低延迟的数据传输,因为缓存在物理上运行在相同的JVM中。稍后我们将更仔细地研究这个解决方案的优缺点。
下面让我们介绍另一个完全不同的缓存模式,客户机-服务器。
客户端/服务器式缓存
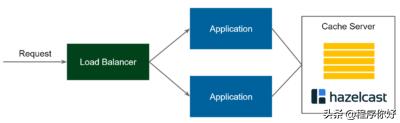
此时,图中所示流程如下:
1.请求进入负载均衡组件并被转发到应用程序服务
2.应用程序使用缓存客户机连接到缓存服务器
3.如果没有找到值,则执行通常的业务逻辑,缓存值并返回响应
该体系结构与经典的数据库体系结构相似。我们有一个中心服务器(或者更准确地说是一组服务器),应用程序连接到该服务器。如果我们将客户机-服务器模式与嵌入式缓存进行比较,主要有两个区别:
- 首先,缓存服务器在我们的体系结构中是一个单独的单元,这意味着我们可以单独管理它(向上/向下伸缩、备份、安全)。然而,这也意味着它通常需要单独的项目事务处工作(甚至单独的项目事务处团队)。
- 第二个区别是应用程序使用缓存客户端库与缓存通信,这意味着我们不再局限于基于jvm的语言。有一个定义良好的协议,服务器部分的编程语言可以与客户端部分不同。这实际上是许多缓存解决方案(如Redis或Memcached)仅为其部署提供这种模式的原因之一。
我之前提到过,嵌入式缓存和客户机-服务器缓存的第一个区别是前者是单独管理的。一个单独的Ops团队甚至可以管理它,或者您可以更进一步,将管理部分转移到云计算中。
云端缓存
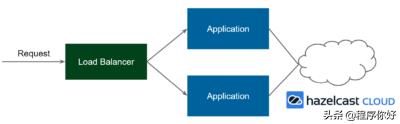
就架构而言,云类似于客户机-服务器,不同之处在于服务器部分被移到组织之外,由云提供商管理,因此您不必担心所有的组织问题。
如果您对某个示例感兴趣,可以在Hazelcast云平台上创建一个Hazelcast集群,然后,您可以在这里找到一个完整的客户机应用程序。
最有趣的部分是Spring配置:
@Bean
CacheManager cacheManager() {
ClientConfig clientConfig = new ClientConfig();
clientConfig.getNetworkConfig().getCloudConfig()
.setEnabled(true)
.setDiscoveryToken("KSXFDTi5HXPJGR0wRAjLgKe45tvEEhd");
clientConfig.setGroupConfig(new GroupConfig("test-cluster", "b2f9845"));
return new HazelcastCacheManager(
HazelcastClient.newHazelcastClient(clientConfig));
}
使用客户机-服务器模式很简单,使用云模式更简单。它们都带来了类似的好处,比如将缓存数据与应用程序分离、独立管理(向上/向下扩展、备份)以及使用任何编程语言的可能性。然而,有一件事变得更加困难——延迟。对于嵌入式模式,缓存始终与应用程序位于同一台机器上(甚至在同一JVM中)。然而,当服务器部分被分离时,我们现在需要考虑它的物理位置。最好的选择是使用相同的本地网络(或者在云解决方案中使用相同的VPC)。
现在,让我们转移到一个新的稍微不寻常的模式,缓存作为一个边车。
边车式缓存(Sidecar)
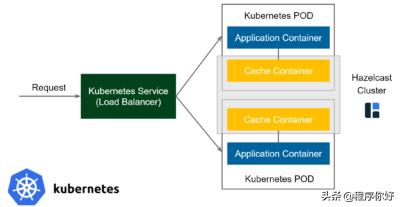
上面的图表是特定于Kubernetes的,因为Sidecar模式主要出现在Kubernetes环境中(但不限于)。在Kubernetes中,部署单元称为POD。这个POD包含一个或多个容器,这些容器总是部署在相同的物理机器上。
通常,一个POD只包含一个容器和应用程序本身。然而,在某些情况下,您不仅可以包含应用程序容器,还可以包含一些提供附加功能的附加容器。这些容器称为边车容器。
流程如下:
1.请求到达Kubernetes服务(负载平衡器)并被转发到其中一个吊舱。
2.请求到达应用程序容器,应用程序使用缓存客户机连接到缓存容器(从技术上讲,缓存服务器总是在localhost上可用)。
这个解决方案混合了嵌入式模式和客户机-服务器模式。
它类似于嵌入式缓存,因为:
- 缓存始终与应用程序位于同一台机器上(低延迟)。
- 资源池和管理活动在缓存和应用程序之间共享。
- 缓存集群发现不是问题(它总是在本地主机上可用)。
它也类似于客户机-服务器模式,因为:
- 应用程序可以用任何编程语言编写(它使用缓存客户端库进行通信)。
- 缓存和应用程序有一些隔离。
现在让我们讨论一个完全不同的模式,反向代理。
反向代理缓存
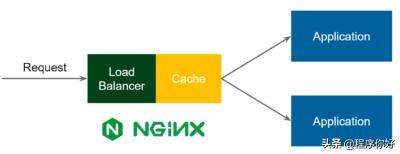
到目前为止,在前面每个场景中,应用程序都清楚自己使用了缓存。然而,这一次,我们将缓存部分放在应用程序前面,所以流程如下:
1.请求进入负载平衡器。
2.负载均衡器检查这样的请求是否已经缓存。
3.如果是,则返回响应,而不将请求转发给应用程序。
这样的缓存解决方案是基于协议级别的,所以在大多数情况下,它是基于HTTP的,这有一些好的和坏的含义:
- 好的方面是,您可以将缓存层指定为配置,因此不需要更改应用程序中的任何代码。
- 不好的是,您不能使用任何基于应用程序的代码来使缓存失效,因此失效必须基于超时(以及标准HTTP TTL、ETag等)。
NGINX提供了成熟的反向代理缓存解决方案;然而,缓存中保存的数据不是分布式的,不是高可用性的,数据存储在磁盘上。
我们可以对反向代理模式做的一个改进是将HTTP反向代理注入到sidecar中。你可以这样做:
反向代理边车
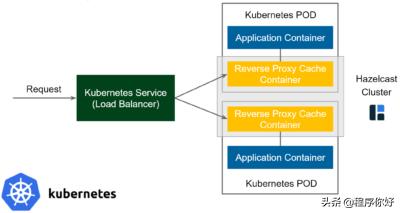
同样,当涉及到Sidecar时,该图仅限于Kubernetes环境。流程如下:
1.请求进入Kubernetes服务(负载平衡器)并被转发到其中一个pod。
2.在POD中,接收请求的是反向代理缓存容器(而不是应用程序容器)。
3.反向代理缓存容器检查这样的请求是否已经缓存。
4.如果是,则发送缓存的响应(甚至不将请求转发给应用程序容器)。
应用程序容器甚至不知道缓存的存在。考虑一下本文开头介绍的微服务系统。使用此模式,我们可以查看整个系统并指定(在Kubernetes配置文件中)应该缓存服务2v1和服务1。
前还没有成熟的HTTP反向代理缓存Sidecar解决方案,然而,我相信它会变得越来越流行,因为一些项目已经在积极地进行一些稳定的实现。
优点和缺点
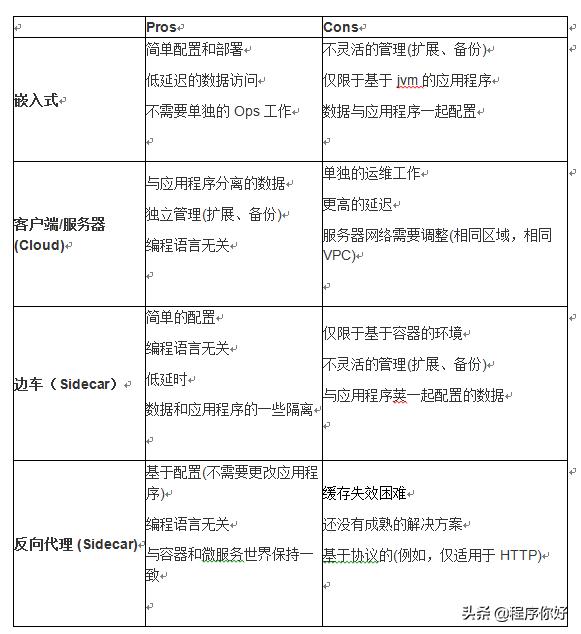
我们提到了许多可以在微服务系统中使用的缓存模式。
优缺点列表:
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

