如何定位微服务异常之链路跟踪APM工具?
微服务框架落地后,分布式部署架构带来的问题就会迅速凸显出来。尤其线上出现问题,不知道如何排查,**问题出现在哪个服务?如何快速定位问题?**如何跟踪业务调用链路?**如何分析解决业务瓶颈?**今天老顾来跟小伙伴们看看如何解决以上问题。
什么是链路追踪
微服务架构是通过业务来划分服务的,使用REST调用。对外暴露的一个接口, 可能需要很多个服务协同才能完成这个接口功能 ,如果链路上 任何一个服务出现问题或者网络超 时,都会形成 导致接口调用失败 。随着业务的不断扩张,服务之间互相调用会越来越复杂。

就看不清楚了,如下图

上图是不是看到后,有密集恐惧症,像个线团,一团乱麻;如果这个时候 出现了调用异常, 那我们依据 调用接口入口,一步步、一个服务一个服务的去跟踪调试 ;这个流程会把人搞疯的,也许1个小时后,也不知道什么问题;就像我们以前找线头,然后一步步的去重新卷圈。
面对以上情况,我们就需要一些可以帮助 理解系统行为、用于分析性能问题的工具 ,以便发生故障的时候,能够 快速定位和解决问题,这就是所谓的 APM (应用性能管理)。
什么是 SkyWalking
Skywalking是 一款国内开源的应用性能监控工具 ,支持对 分布式系统的监控、跟踪和诊断 。目前主要的一些 APM 工具有: Cat、Zipkin、Pinpoint、SkyWalking。 SkyWalking也是Apache的孵化项目之一,拥有顶级二级域名 。 它提供了如下的 主要功能特性 :
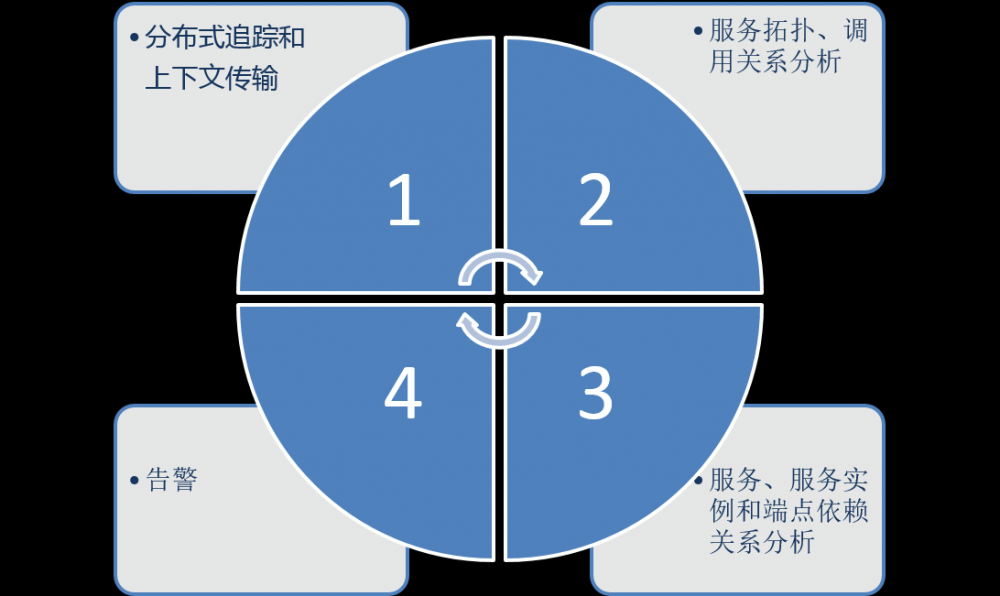
技术架构
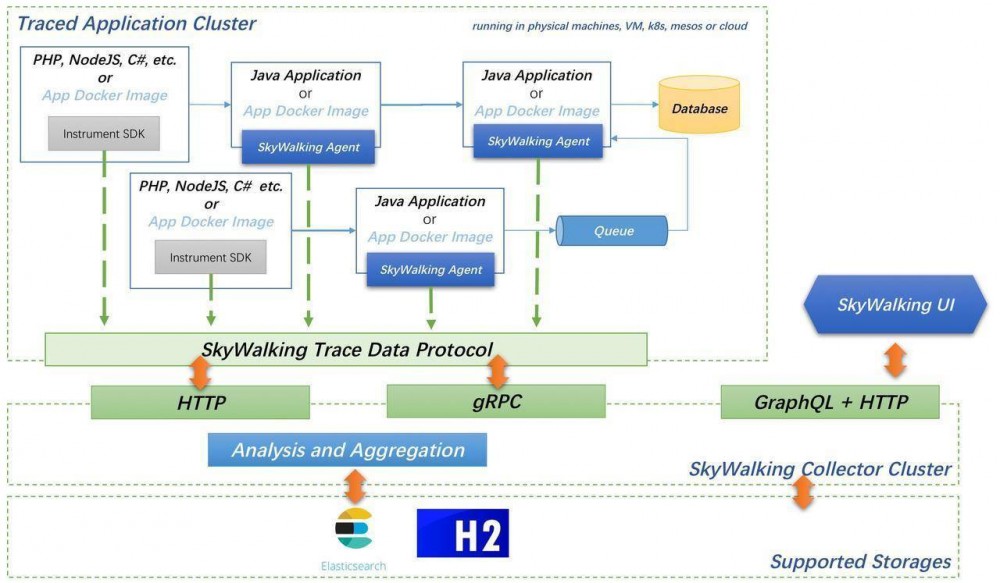
,用来展示落地的数据。
下载并启动 SkyWalking
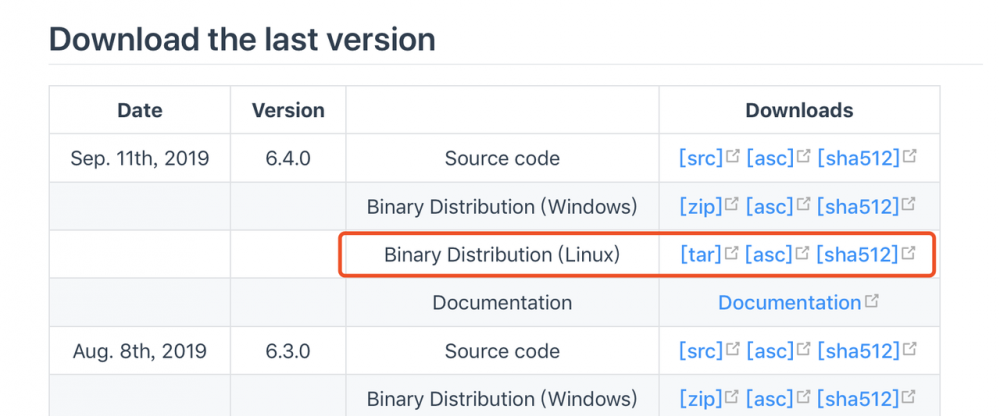
官方已经为我们准备好了编译过的服务端版本,现在最新版本为6.4.0
下载地址为 skywalking.apache.org/downloads/
配置 SkyWalking
下载完成后 解压缩
# tar -xvf apache-skywalking-apm-6.4.0.tar # mv apache-skywalking-apm-bin /usr/local/skywalking # cd /usr/local/skywalking 复制代码
修改配置
# cd config 复制代码
vim application.yml@
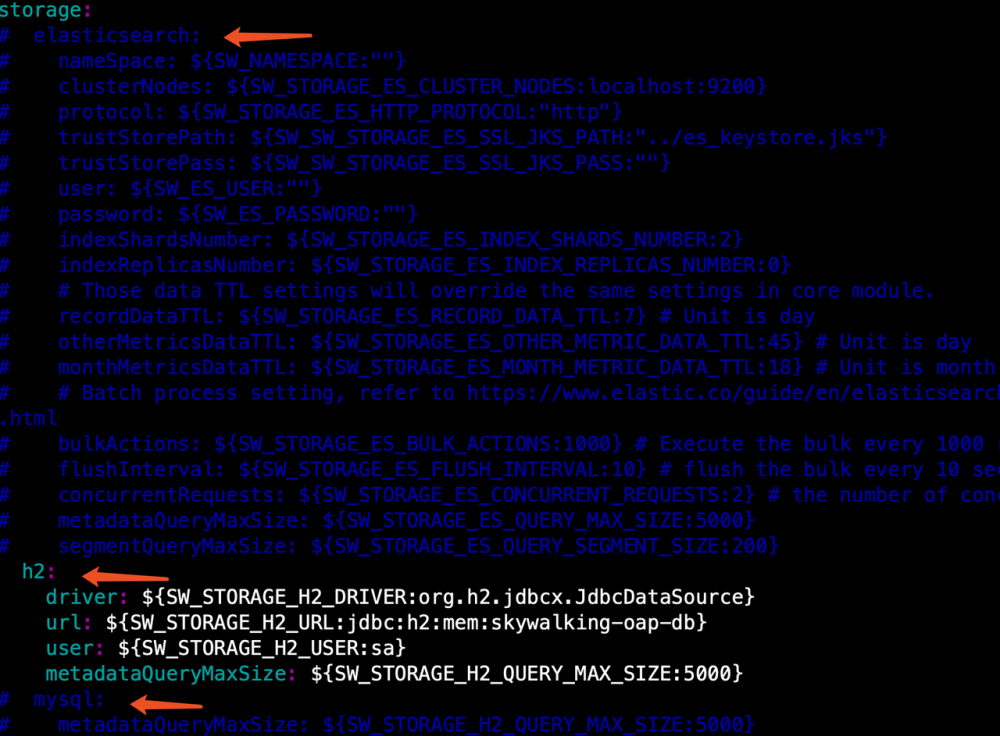
配置存储方式,默认H2, 官方推荐elasticsearch 这里需要做 三件事 :
- 注释 H2 存储方案
- 启用 ElasticSearch 存储方案
- 修改 ElasticSearch 服务器地址
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES: localhost:9200 }
启动 SkyWalking
修改完配置后,进入 skywalking/bin 目录, 运行startup.bat启动服务端
通过浏览器访问 http://localhost:8080 出现如下界面即表示启动成功
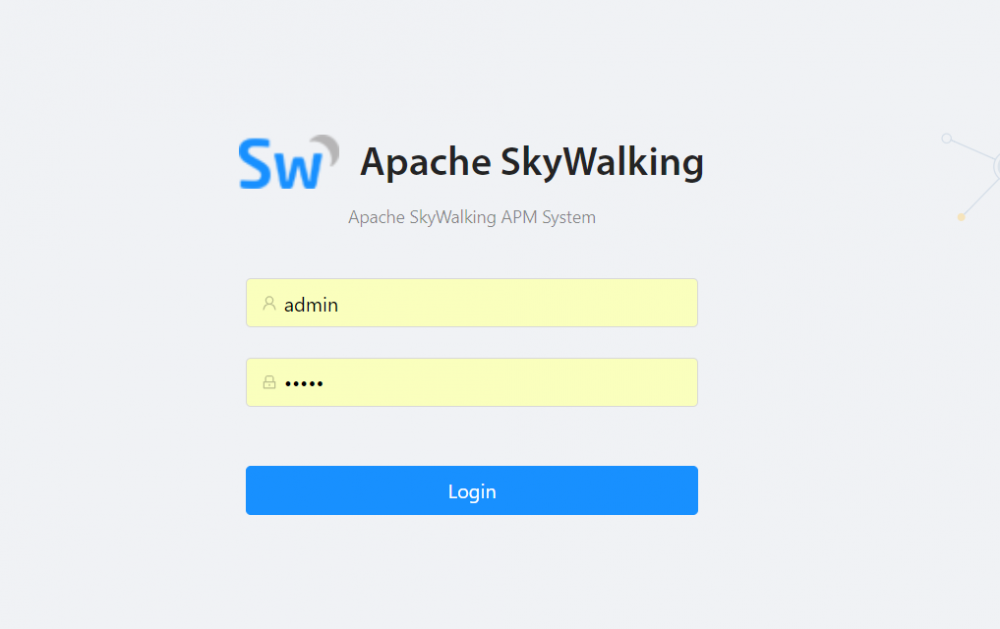
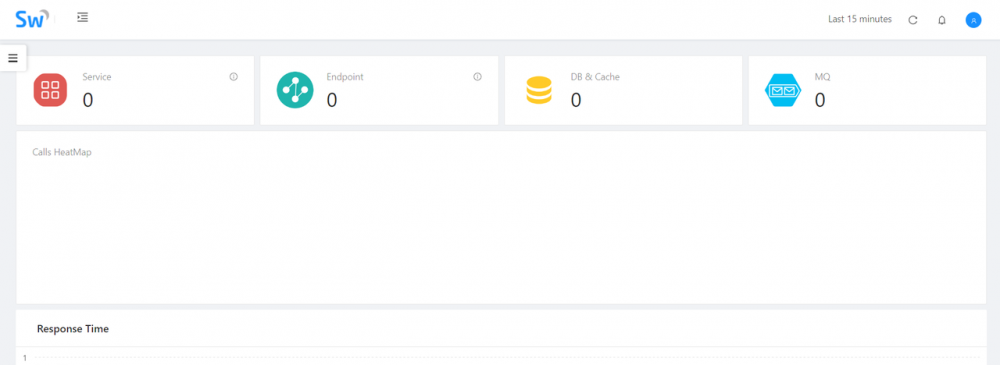
默认的用户名密码为:admin/admin,登录成功后,效果如下图
Java Agent 服务器探针
agent简单的理解就是放一个插件, 随着应用程序启动 ,监控数据、收集数据、发送数据的作用。 探针文件在skywalking/agent目录下
启动方式
在以前启动应用程序时,加上一些参数
java -javaagent:/path/to/skywalking-agent/skywalking-agent.jar
-Dskywalking.agent.service_name=shop-goods-provider
-Dskywalking.collector.backend_service=localhost:11800
-jar yourApp.jar
复制代码
参数含义:
- **-javaagent:**用于指定探针路径
- **-Dskywalking.agent.service_name:**用于重写 agent/config/agent.config 配置文件中的服务名
- **-Dskywalking.collector.backend_service:**用于重写 agent/config/agent.config 配置文件中的服务地址
启动后,访问链接,就会发现 Service 与 Endpoint 已经成功检测到了
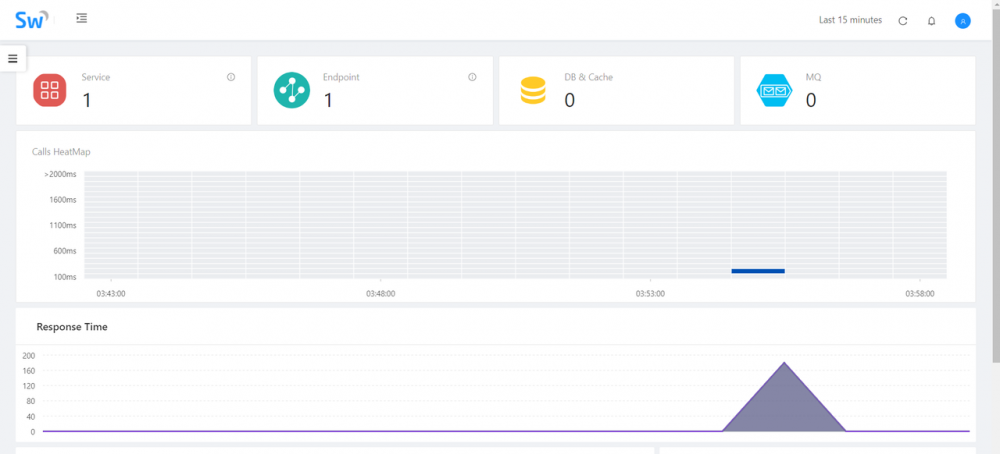
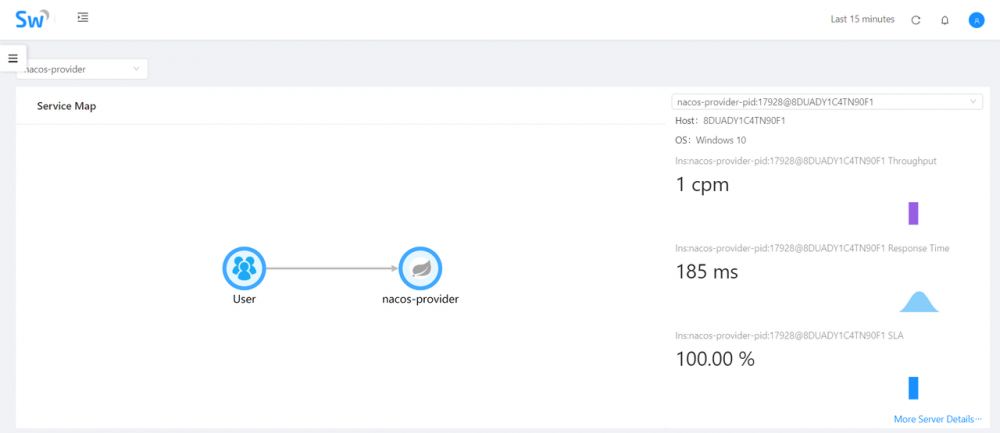
表示 SkyWalking 链路追踪配置成功。
Service Topology监控
调用链路监控可以从两个角度去看待。我们先从整体上来认识一下我们所监控的系统。
通过给服务添加探针并产生实际的调用之后,我们可以通过Skywalking的前端UI查看服务之间的调用关系。
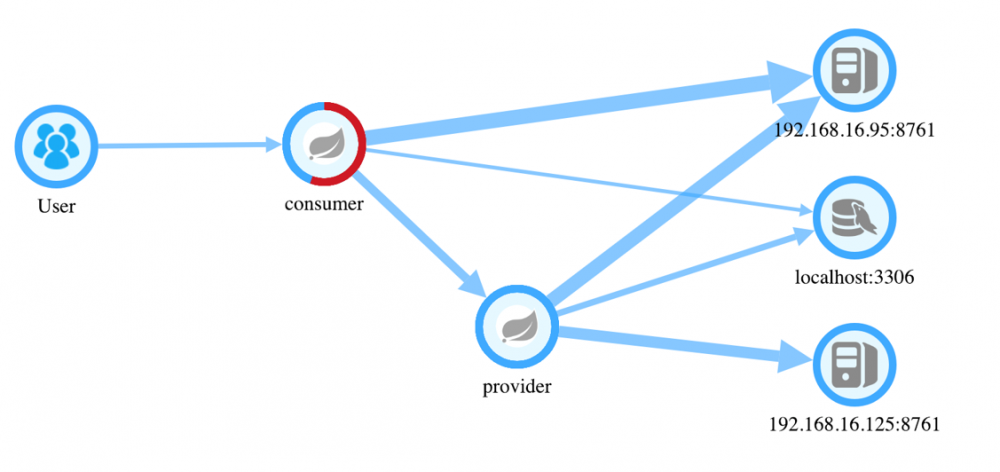
从图中可以看到:
有两个服务节点:provider & consumer 有一个数据库节点:localhost【mysql】 consumer消费了provider提供出来的接口。
一个系统的拓扑图让我们清晰的认识到 系统之间的应用的依赖关系 以及当前状态下的业务流转流程。
细心的小伙伴们可能发现图示节点consumer上有一部分是红色的,红色是什么意思呢?
红色代表当前流经consumer节点的请求有一断时间内是响应异常的。当节点 全部变红 的时候证明服务现阶段内就 彻底不可用了 。运维人员可以通过 Topology迅速发现某一个服务潜在的问题 ,并进行下一步的排查并做到预防。
Skywalking Trace监控
Skywalking通过业务调用 监控进行依赖分析 ,提供给我们了 服务之间的服务调用拓扑关 系、以及针对每个endpoint的trace记录。 我们在之前看到consumer节点服务中发生了错误,让我们一起来定位下错误是 发生在了什么地方又是什么原因呢?

在每一条trace的信息中都可以看到当前请求的时间、GloableId、以及请求被调用的时间。我们分别看一看正确的调用和异常的调用。
Trace调用链路监控
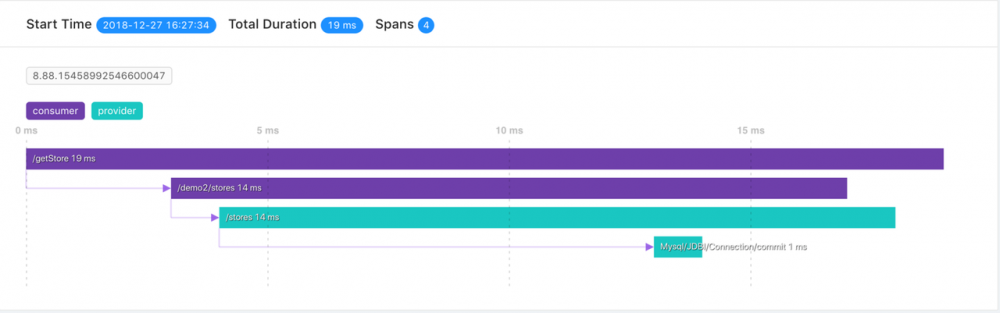
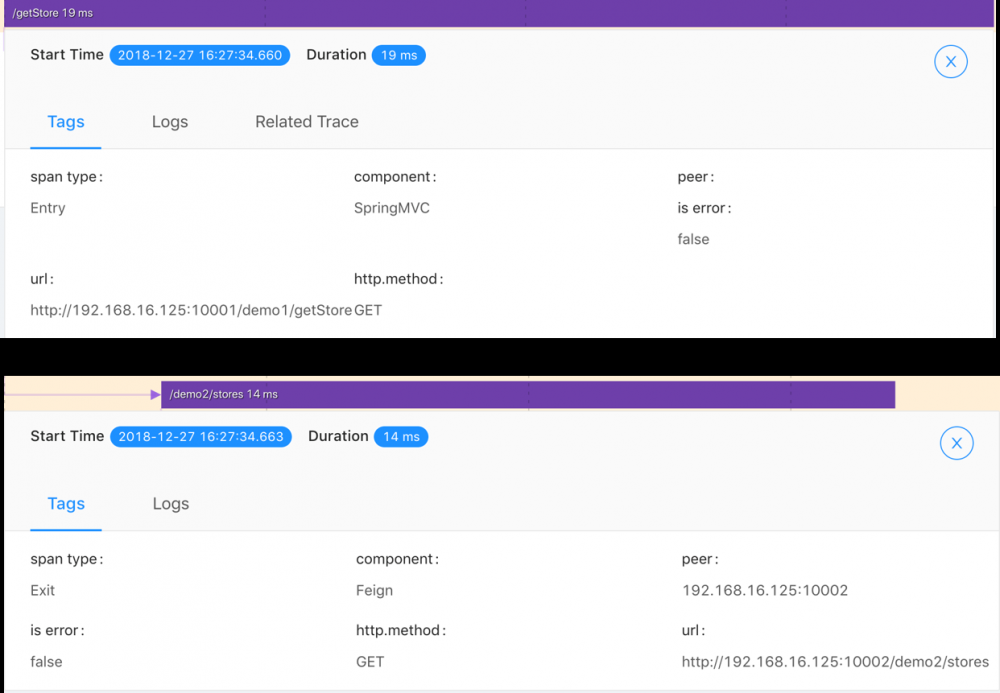
上图展示的是一次正常的响应,这条响应总耗时19ms;可以详细点击每个span查看详细信息
Service JVM信息监控
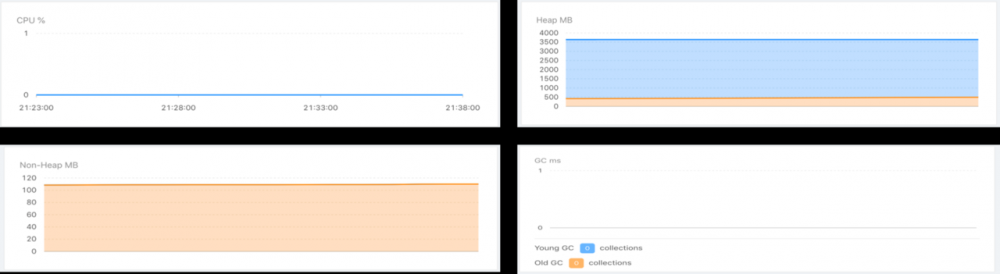
。
Skywalking 服务告警
上面我们提到了通过查看拓扑图以及调用链路可以 定位问题 ,可是运维人员又 不可能一直盯着这些数据 ,那么我们就需要告警能力,在 异常达到一定阈值的时候主动的提示我们去查看系统状态。
在Sywalking 6.x版本中新增了对服务状态的告警能力。它通过webhook的方式让我们可以自定义我们告警信息的通知方式。诸如: 邮件通知、微信通知、短信通知 等。
告警的规则配置。在alarm-settings.xml中可以配置告警规则,告警规则支持自定义。
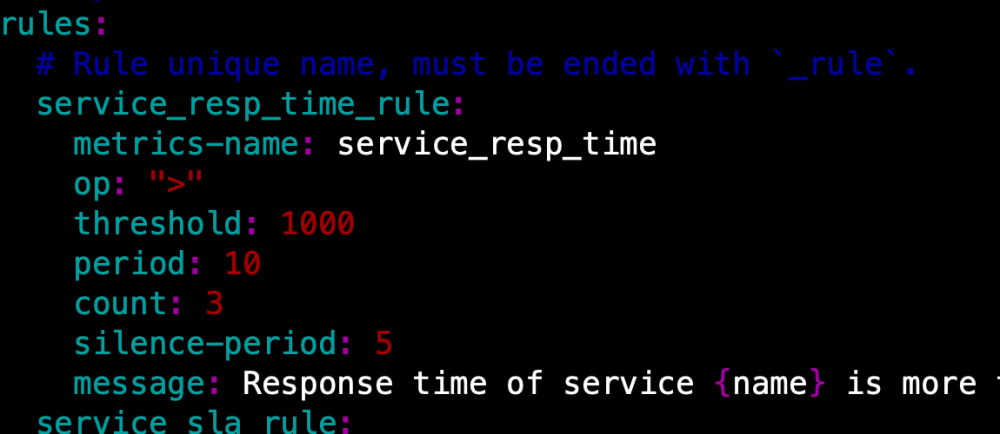
1、service_resp_time_rule:告警规则名称 ***_rule (规则名称可以自定义但是必须以’_rule’结尾
2、indicator-name:指标数据名称: 定义参见t.cn/EGhfbmd
3、op: 操作符: > , < , = 【当然你可以自己扩展开发其他的操作符】
4、threshold:目标值:指标数据的目标数据 如sample中的1000就是服务响应时间,配合上操作符就是大于1000ms的服务响应
5、period: 告警检查周期:多久检查一次当前的指标数据是否符合告警规则
6、counts: 达到告警阈值的次数
7、silence-period:忽略相同告警信息的周期
8、message:告警信息
文件结尾有最后一个webhooks属性: 服务告警通知服务地址
webhooks: # - http://127.0.0.1/notify/ # - http://127.0.0.1/go-wechat/ 复制代码
正文到此结束
- 本文标签: 管理 HTML message 分布式系统 java db 集群 大数据 App 开源 下载 Elasticsearch 部署 目录 node cat CTO 性能问题 ACE zipkin 微服务 mysql 编译 数据库 IDE 域名 开发 http 分布式 Agent 服务器 tar 数据 注释 参数 core id pinpoint 探针 调试 时间 REST src 服务端 字节码 web js UI 代码 插件 consumer IO JVM apache https 配置 Node.js XML provider Service javaagent zip ip sql
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

