异地多活高可用架构设计
随着业务的快速发展,对于很多公司来说,构建于单地域的技术体系架构,会面临诸如下面的多种问题:基础设施的有限性限制了业务的可扩展性;机房、城市级别的故障灾害,影响服务的可持续性。
为解决遇到的这些问题,公司可以选择构建异地多活架构,在同城/异地构建多个单元(业务中心)。各个业务单元可以分布在不同的地域,从而有效解决了单地域部署带来的基础设施的扩展限制、服务可持续性。
异地多活是近几年比较热门的一个话题,那么在实际业务中什么时候需要去做这件事?如何去做?做的时候需要考虑什么?
何时去做?
个人感觉取决于以下几个方面:
- 业务发展
- 基础设施状况
- 技术积淀
如何做?
目前在网上搜索到的异地多活方案来看,基本都是阿里、饿了么、京东、微博这些互联网大厂的实践,这些大厂的方案有一个共同点就是:大量的自研组件,来做相关的数据同步,业务切分等等,那么,对于很多传统企业或者相对小一些的企业,应该如何来做这件事?
- 根据业务特性借助合适的公有云服务
做的时候,需要注意什么?
- 真正需要做异地多活的业务有哪些?
- 基础设施如何?
- 对于不可用时间的容忍程度是多少?
业务背景
- 在所有的系统中用户中心都是核心业务,因为它是进入其它很多业务前提。
- 我们这边IDC不是很稳定,之前发生过几次机房大规模故障,比如机房网络挂了,整个机房对外不可用了。
以上两点是我们这次要做用户中心异地容灾的出发点,以便在面对机房级别故障时,保证服务可用性。
业务梳理
用户中心从整体来看,对外主要提供:注册、登陆、查询用户信息等服务。这些服务又有以下几个特点:
- 登陆的优先级最高
- 事务性要求低
涉及的公共组件主要有:
- MySQL:用户数据存储
- Redis:Authorization Code、短信验证码、账号锁定、access token等的存储
- Zookeeper:Dubbo依赖
方案
用户中心是通过外包的形式进行开发的,目前已上线并交付给另一个外包商运维,所以在考虑容灾一期方案的时候,需要考虑尽量不动代码。
目标
一期目标
当北京机房出现故障的时候,可以一定时间内把流量切到青岛机房这边,保证用户中心核心服务的基本可用。
二期目标
用户中心通过异地多活,实现高可用(需要集团智能DNS支持)。
架构设计
一期架构
当北京机房发生故障的时候,可以把流量快速切换到青岛这边,以保障用户中心核心服务可用。
具体方案如下:
- 通过otter近实时的将北京机房核心业务数据同步到青岛机房。
- 青岛机房部署Redis、ZooKeeper等中间件。
- 青岛机房部署用户中心的核心应用(实例正常部署、运行,只是平时不会有访问)。
具体架构如下:
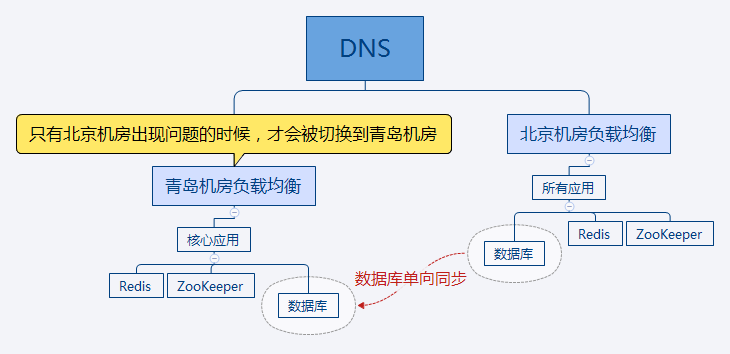
可以达到的效果:
- 当北京机房出现故障的时候,可以在一定时间内把流量切到青岛机房这边,保证用户中心核心服务的基本可用,但此时已登录用户需要重新登录。
- 一定时间:取决于DNS修改ip时间+DNS TTL时间,目前来看TTL是10分钟,人工修改ip应该很快,所以一定时间是10~20分钟。
存在的缺点:
- 北京机房非故障期间,青岛机房的机器,仅做数据库同步,存在一定的资源浪费。
- 当北京机房出现故障,流量切换到青岛机房后,只能保证登陆这一核心服务的可用。对于注册等需要修改数据库的服务,均不支持,如果在此期间访问这类服务,会发生异常。
二期架构
二期的目的就是修正一期架构的缺点,通过异地多活,实现高可用。
二期青岛机房会替换为阿里云机房。
具体方案如下:
- 通过阿里云DTS服务实现两地机房数据库同步,保证北京、阿里云数据的近实时一致性。
- 北京、阿里云两地机房均提供在线服务,提高资源利用率。
- 梳理服务优先级,修改应用代码,支持服务降级。
- 当某个机房(阿里云或者北京)出现故障的时候,通过DNS服务把流量切换到另一个机房。
- 如果两地部署的时候,没有冗余一定硬件资源,则需要实施服务降级。
- 目前集团DNS解析,无法提供自动检测服务是否可用的功能,也就无法自动进行切换。
- 服务可用性,可以通过我们这边的多点拨测进行监控,当多点拨测不可用的时候,发送告警通知给相关人员,以便人工介入。
- 多点拨测告警,应该会提供两类:1、某个拨测点不通的时候 2、所有拨测点均不可用的时候。
- 目前集团DNS解析,TTL生效最短时间是10分钟,无法自定义TTL时间。
具体架构如下:
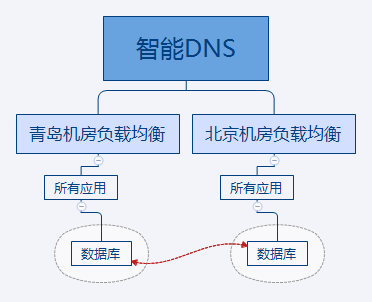
可以达到的效果:
- 如果集团DNS可以提供,类似阿里云云解析的网站监控功能并能灵活设置TTL时间,这时当北京机房或者阿里云机房出现故障后,就可以在很短的时间(部分服务最大异常时间)内自动进行流量切换。
此处只是以阿里云云解析示例,只要能提供类似的服务均可。
- 如果集团DNS无法提供类似阿里云云解析的网站监控及灵活设置TTL时间的功能,则部分服务最大异常时间还是取决于DNS修改ip时间+DNS TTL时间。
名词解释
什么是网站监控?
HTTP/HTTPS实时探测域名解析记录,支持自定义端口,实时发现宕机立即告警; 全网分布式监控,在中国各个地区模拟用户端真实请求,监控结果真实可靠; 支持宕机暂停、容灾切换,最大限度的解决服务中断对您的业务带来的损失; 容灾切换支持A记录、CNAME域名,满足各种场景的容灾切换需求;
什么情况会被网站监控判断为宕机并发送告警通知?
监控结果中,HTTP/HTTPS的返回码大于500的服务器错误情况,才会报警通知。 举例说明:如果设置了四个探测点 北京联通、深圳阿里巴巴、上海电信、重庆联通。 场景一:四个探测点中50%的监控点无法收到您服务器的响应,或50%的监控点收到返回码大于等于500时,才会判断您的网站为宕机情况。 场景二:四个探测点中有50%以上的探测点探测您的网站返回码是小于500的情况,则不会判断您的网站为宕机。
云解析DNS“流量管理”
云解析“流量管理”可以在您设置的每条解析线路下,根据权重比例轮询返回解析结果。当线路下的IP宕机时可以通过监控自动发现,并将宕机IP从当前线路下摘除,直到监控IP正常时会恢复解析。同时,当一条解析线路下的所有IP都宕机时,可以切换至其他正常线路。最大程度保证您的网站服务高可用,减小损失。
部分服务最大异常时间
比如北京机房出现异常,这时转发到阿里云机房的流量是可以正常访问,只有转发到北京机房的流量是异常的。
这时如果使用网站监控或者类似服务,进行监控,并设置拨测间隔为1分钟,TTL生效时间为1秒,那么最多有60+1秒部分服务异常时间,之后DNS会自动把北京机房的ip自动踢掉,流量全部切到阿里云。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

