使用Stream实现对代码的简化
Java8同样引入了另一个特别有用的操作,那就是Stream,也就是常说的流。首先我们看JDK中对Stream的定义:

意思大概就是一个有序和并行操作的元素的序列,听起来还是很拗口,简单来说就是可将一组数据想象成为一条水流,从上游流向下游,而Collection接口中正好有Stream这个方法,所以实现了Collection接口的集合都可以通过转换为Stream后,去做一些过滤、排序、查找等操作。
1.举个例子
有一个User对象,它的参数包括name,age。
public class User {
String name;
int age;
public String getName() {
return name;
}
public int getAge() {
return age;
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
复制代码
需求是找出其中姓为张的用户的名字,结果按照年龄从小到大排序。
这里我先不使用流,用更加直接的方法实现这个功能,代码如下:
public static List<User> filterUser(List<User> list) {
List<User> result = new ArrayList<>();
for (User user : list
) {
if (user.getName().startsWith("张")) {
result.add(user);
}
}
return result;
}
public static List<String> sortByAge(List<User> list) {
List<String> stringList = new ArrayList<>();
Collections.sort(list, new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
if (o1.getAge() < o2.getAge()) {
return -1;
} else if (o1.getAge() > o2.getAge()) {
return 1;
} else {
return 0;
}
}
});
for (User user : list
) {
stringList.add(user.getName());
}
return stringList;
}
复制代码
调用之后运行:
public static void main(String[] args) {
List<User> list = Arrays.asList(
new User("张三", 20),
new User("张麻子", 23),
new User("李四", 21),
new User("赵武", 19));
System.out.println(sortByAge(filterUser(list)));
}
复制代码
可以看到整个过程不是很难,但是却洋洋洒洒的写了30多行,而且写的不是很直观。那么如果用流来实现呢? 代码如下:
public static List<String> filterAndSortUser(List<User> list) {
return list.stream().filter(user -> user.getName().startsWith("张"))
.sorted(comparing(User::getAge))
.map(User::getName)
.collect(Collectors.toList());
}
复制代码
没错,只要5行,看起来就比前面那一大段代码舒服,并且每一步都能通过方法名知道在干什么,filter-过滤/sorted-排序/map-将参数类型映射成另一种类型/collect-将流中的元素收集成一个List。
那么这个过程是怎么实现的呢,首先将实现了Collection接口的List转换成Stream,对这个流我们可以实现若干多个中间操作,即返回流的操作,但是最后需要用一个返回非Stream的终结操作来终结这个操作,这条流到这就结束了。
这个过程我们可以使用Java Stream Debugger插件来查看: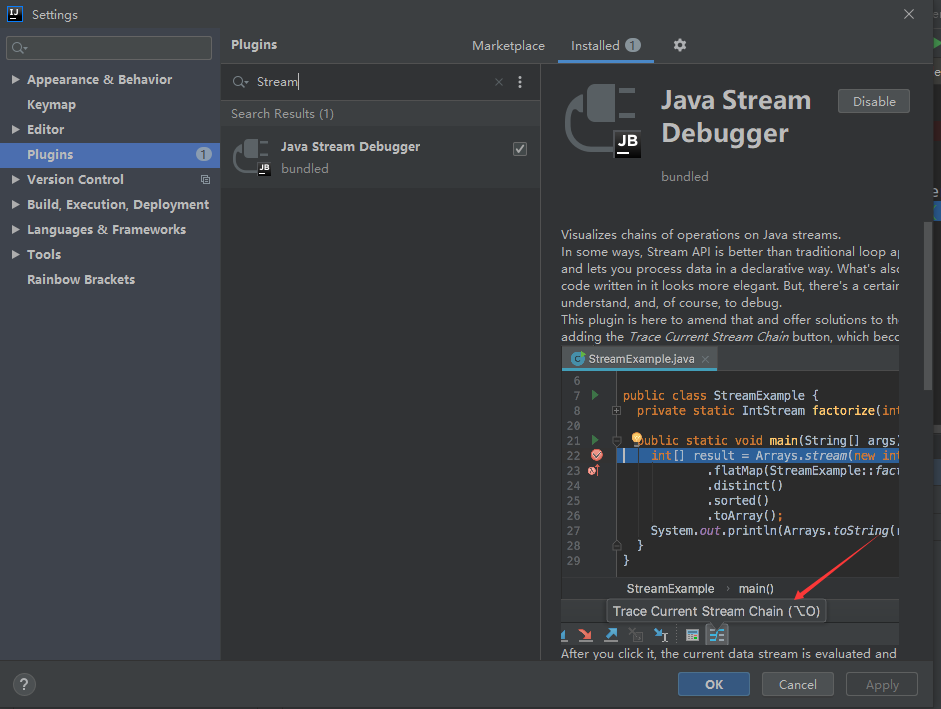
根据图中的提示,在打好断点,进入流方法后,点击调试界面的流调试器按钮:
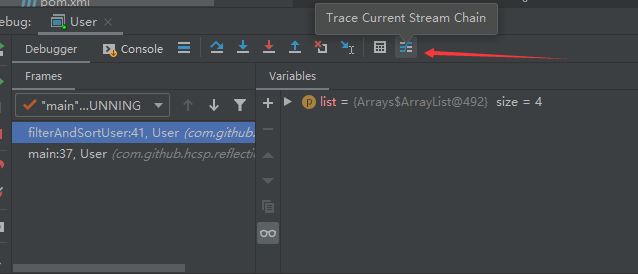
选择上面的这排操作,即可看到整个执行过程:

为了加深印象,可以自己试着写更多的例子:
1.'编写一个方法,统计"年龄大于等于60的用户中,名字是两个字的用户数量'
public static int countUsers(List<User> users) {
return (int) users.stream().filter(user -> user.age >= 60)
.filter(user -> user.name.length() == 2)
.count();
}
2. '编写一个方法,筛选出年龄大于等于60的用户,然后将他们按照年龄从大到小排序,将他们的名字放在一个LinkedList中返回'
public static LinkedList<String> collectNames(List<User> users) {
return users.stream().filter(user -> user.age >= 60)
.sorted(Comparator.comparing(User::getAge))
.map(User::getName)
.collect(Collectors.toCollection(LinkedList::new));
}
3.'判断一段文本中是否包含关键词列表中的文本,如果包含任意一个关键词,返回true,否则返回false'
// 例如,text="catcatcat,boyboyboy", keywords=["boy", "girl"],返回true
// 例如,text="I am a boy", keywords=["cat", "dog"],返回false
public static boolean containsKeyword(String text, List<String> keywords) {
return keywords.stream().anyMatch(text::contains);
}
4.'返回一个从部门名到这个部门的所有用户的映射。同一个部门的用户按照年龄进行从小到大排序'
// 例如,传入的employees是[{name=张三, department=技术部, age=40 }, {name=李四, department=技术部, age=30 },
// {name=王五, department=市场部, age=40 }]
// 返回如下映射:
// 技术部 -> [{name=李四, department=技术部, age=30 }, {name=张三, department=技术部, age=40 }]
// 市场部 -> [{name=王五, department=市场部, age=40 }]
public static Map<String, List<Employee>> collect(List<Employee> employees) {
return employees.stream().sorted(Comparator.comparing(Employee::getAge))
.collect(Collectors.groupingBy(Employee::getDepartment));
}
5.'使用流的方法,把订单处理成ID->订单的映射'
// 例如,传入参数[{id=1,name='肥皂'},{id=2,name='牙刷'}]
// 返回一个映射{1->Order(1,'肥皂'),2->Order(2,'牙刷')}
public static Map<Integer, Order> toMap(List<Order> orders) {
return orders.stream().collect(Collectors.toMap(Order::getId, order -> order));
}
6.' 使用流的方法,把所有长度等于1的单词挑出来,然后用逗号连接起来'
// 例如,传入参数words=['a','bb','ccc','d','e']
// 返回字符串a,d,e
public static String filterThenConcat(Set<String> words) {
return words.stream().filter(s -> s.length() ==1)
.collect(Collectors.joining(","));
}
复制代码
Javadoc中的Collectors类中也举出了几个使用流的实例,有兴趣可以看一下。
2.须知概念
我学到这的时候,也就只是知道流这么个东西可以简化代码而已,但是光知道怎么用未免太浮躁了,基本概念还是必须掌握滴。
2.1流跟数组的差异体现在哪里?
1.流不会存储元素。这些元素可能会存储在底层的集合中,或者说是按需生成的。
2.流的操作不会对数据源作出修改,对流的操作只是可能产生新的流。
3.流的操作是尽可能的惰性的。意思就是直至需要流的结果时,才会执行对流的操作。以前面的例子来说,也就是直到执行collect、count、findfirst等终止流的操作时,前面的操作才会去执行。
2.2创建流的方法有哪些?
1.实现了Collection接口的类,可以直接使用.stream()方法创建流。
2.对于数组,可以使用Stream.of方法创建流。
举例:
Stream<String> stringStream = Stream.of(s.split("XXX"));
Stream<String> stringStream = Stream.of("up","down","left","right");
//从数组中的指定区间创建流
Stream<String> stringStream = Arrays.stream(array,from,to)
复制代码
3.对于创建无限流的话,可以使用generate方法(接受一个Supplier 对象,返回一个流)或者iterate方法(接受一个UnaryOperator对象,返回一个流)。
举例:
Stream<String> stringStream = Stream.generate(() -> "s"); Stream<BigInteger> integerStream = Stream.iterate(BigInteger.ZERO,n->n.add(BigInteger.ONE)); 复制代码
4.对于空的流直接Stream.enpty方法即可。
5.Pattern类中的splitAsStream方法。
举例:
Stream<String> stringStream = Pattern.compile("XX").splitAsStream(XXXX);
复制代码
2.3流是线程安全的么?
public static void threadTest() {
Stream<BigInteger> integerStream = Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE));
integerStream.parallel().limit(100).map(bigInteger -> bigInteger+" ").forEach(System.out::print);
}
复制代码
很简单从0到99打印出来这些数字,为了方便查看,数字之间加空格。结果如下:

可以看出这不是我们所预期的那样,从0到99顺序打印数字。由于传递给forEach的函数会在多个并发线程中运行,所以打印的顺序是不会被保证的,所以显而易见parallel不是线程安全的。下面是Javadoc中的原话:
* <p>The behavior of this operation is explicitly nondeterministic.
* For parallel stream pipelines, this operation does <em>not</em>
* guarantee to respect the encounter order of the stream, as doing so
* would sacrifice the benefit of parallelism. For any given element, the
* action may be performed at whatever time and in whatever thread the
* library chooses. If the action accesses shared state, it is
* responsible for providing the required synchronization.
复制代码
对于这种情况调用collect方法即可:
System.out.println(integerStream.parallel().limit(100).collect(Collectors.toList())); 复制代码
3.总结
流确实方便了很多操作,像过滤、排序、映射、分组、收集成列表等,并且里面有很多非常好用的API可以供我们使用。但是金无足赤,滥用流的话代码的可读性就会大大下降,有兴趣的可以看下Effective Java 的第45条 "明智慎用的选择Stream",想必会有启发的。
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

