Java 容器 - 一文详解HashMap
Map 类集合
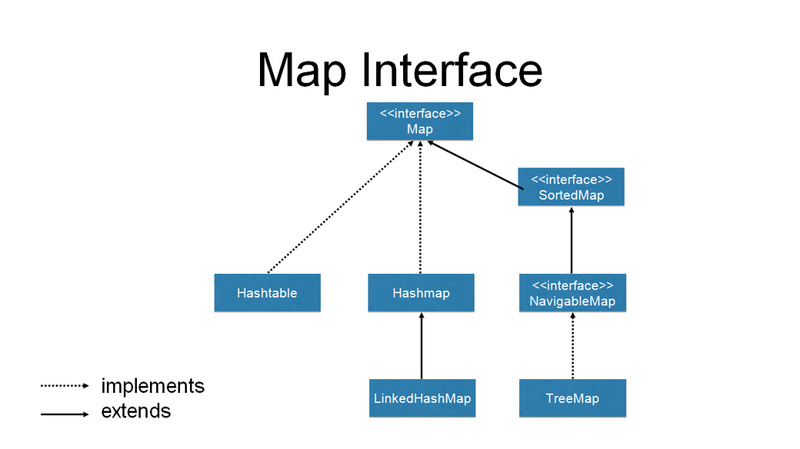
Java Map类集合,与Collections类集合存在很大不同。它是与Collection 类平级的一个接口。
在集合框架中,通过部分视图方法这一根 微弱的线联系起来。
(在之后的分享中,我们会讨论到Collections 框架的内容)
Map类集合中的存储单位是K-V键值对,就是 使用一定的哈希算法形成一组比较均匀的哈希值作为Key,Value值挂在Key上。
Map类 的特点:
- 没有重复的Key,可以具有多个重复的Value
- Value可以是List/Map/Set对象
- KV是否允许为null,以实现类的约束为准
| Map集合类 | Key | Value | Super | JDK | 说明 |
|---|---|---|---|---|---|
| Hashtable | 不允许为 null | 不允许为 null | Dictionary | 1.0 | (过时)线程安全类 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | AbstractMap | 1.5 | 锁分段技术或CAS(JDK8 及以上) |
| TreeMap | 不允许为 null | 允许为 null | AbstractMap | 1.2 | 线程不安全(有序) |
| HashMap | 允许为 null | 允许为 null | AbstractMap | 1.2 | 线程不安全(resize 死链问题) |
从jdk1.0-1.5,这几个重点KV集合类,见证了Java语言成为工业级语言的成长历程。
知识点:
- Map 类 特有的三个方法是
keySet()、values()、entrySet(),其中values()方法返回的视图的集合实现类是Values extends AbstractCollection<V>,没有实现add操作,实现了remove/clear等相关操作,调用add方法时会抛出异常。 - 在大多数情况下,直接使用ConcurrentHashMap替代HashMap没有任何问题,性能上面差别不大,且线程安全。
- 任何Map类集合中,都要尽量避免KV设置为null值。
- Hashtable - HashMap - ConcurrentHashMap 之间的关系 大致相当于 Vector - ArrayList - CopyOnWriteArrayList 之间的关系,当然HashMap 和 ConcurrentHashMap之间性能差距更小。
一、hashCode()
哈希算法 哈希值
在Object 类中,hashCode()方法是一个被native修饰的类,JavaDoc中描述的是返回该对象的哈希值。
那么哈希值这个返回值是有什么作用呢?
主要是保证基于散列的集合,如HashSet、HashMap以及HashTable等,在插入元素时保证元素不可重复,同时为了提高元素的插入删除便利效率而设计;主要是为了查找的便捷性而存在。
拿Set进行举例,
众所周知,Set集合是不能重复,如果每次添加数据都拿新元素去和集合内部元素进行逐一地equal()比较,那么插入十万条数据的效率可以说是非常低的。
所以在添加数据的时候就出现了哈希表的应用,哈希算法也称之为散列算法,当添加一个值的时候,先去计算出它的哈希值,根据算出的哈希值将数据插入指定位置。这样的话就避免了一直去使用equal()比较的效率问题。
具体表现在:
- 如果指定位置为空,则直接添加
- 如果指定位置不为空,调用equal() 判断两个元素是否相同,如果相同则不存储
上述第二种情况中,如果两个元素不相同,但是hashCode()相同,那就是发生了我们所谓的哈希碰撞。
哈希碰撞的概率取决于hashCode()计算方式和空间容量的大小。
这种情况下,会在相同的位置,创建一个链表,把key值相同的元素存放到链表中。
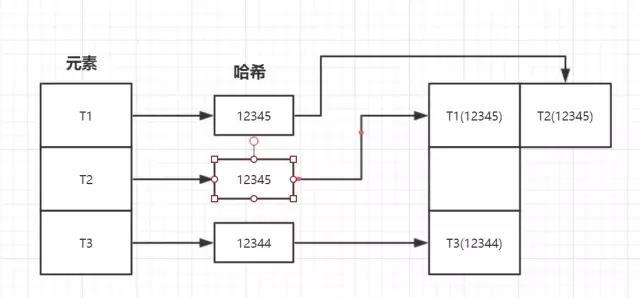
在HashMap中就是使用拉链法来解决hashCode冲突。
总结
hashCode是一个对象的标识,Java中对象的hashCode是一个int类型值。通过hashCode来指定数组的索引可以快速定位到要找的对象在数组中的位置,之后再遍历链表找到对应值,理想情况下时间复杂度为O(1),并且不同对象可以拥有相同的hashCode。
HashMap 底层实现
带着问题
- HashMap 的长度为什么默认初始长度是16,并且每次resize()的时候,长度必须是2的幂次方?
- 你熟悉HashMap的扩容机制吗?
- 你熟悉HashMap的死链问题吗?
- Java 7 和 Java 8 HashMap有哪些差别?
- 为什么Java 8之后,HashMap、ConcurrentHashMap要引入红黑树?
0. 简介
- HashMap 基于哈希表的Map接口实现的,是以Key-Value存储形式存在;
- 非线程安全;
- key value都可以为null;
- HashMap中的映射不是有序的;
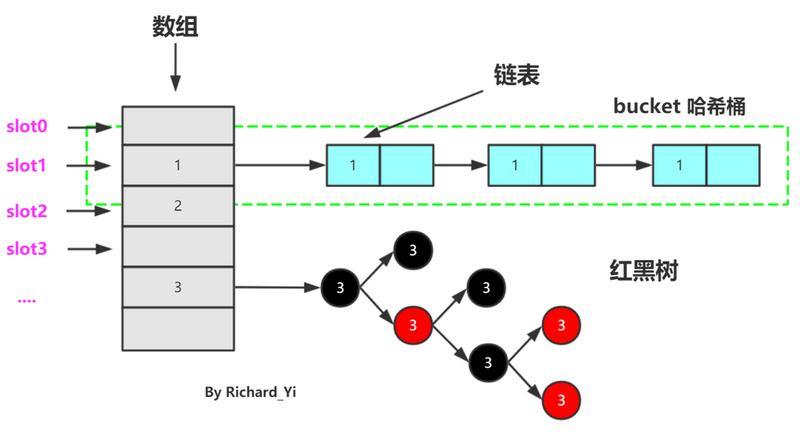
- 在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构;
- 当一个哈希桶存储的链表长度大于8 会将链表转换成红黑树,小于6时则从红黑树转换成链表;
- 1.8之前和1.8及以后的源码,差别较大
1. 存储结构
在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构。
通过哈希来确认到数组的位置,如果发生哈希碰撞就以链表的形式存储 ,但是这样如果链表过长来的话,HashMap会把这个链表转换成红黑树来存储,阈值为8。
下面是HashMap的结构图:
2. 重要属性
2.1 table
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组。
2.2 size
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
HashMap中 键值对存储数量。
2.3 loadFactor
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
负载因子。 负载因子是权衡资源利用率与分配空间的系数 。当 元素总量 > 数组长度 * 负载因子 时会进行扩容操作。
2.4 threshold
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
扩容阈值。 threshold = 数组长度 * 负载因子 。超过后执行扩容操作。
2.5 TREEIFY_THRESHOLD/UNTREEIFY_THRESHOLD
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
树形化阈值。当一个哈希桶存储的链表长度大于8 会将链表转换成红黑树,小于6时则从红黑树转换成链表。
3. 增加元素
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
3.1 hash()
可以看到实际执行添加元素的是putVal()操作,在执行putVal()之前,先是对key执行了hash()方法,让我们看下里面做了什么
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
key==null 说明,HashMap中是支持key为null的情况的。
同样的方法在Hashstable中是直接用key来获取hashCode,没有 key==null 的判断,所以Hashstable是不支持key为null的。
再回来说这个hash()方法。 这个方法用专业术语来称呼就叫做 扰动函数 。
使用hash()也就是扰动函数,是 为了防止一些实现比较差的hashCode()方法 。换句话来说, 就是为了减少哈希碰撞 。
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。我们再看下JDK1.7中是怎么做的。
// code in JDK1.7
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
知识延伸外链: JDK 源码中 HashMap 的 hash 方法原理是什么? - 胖君的回答 - 知乎
https://www.zhihu.com/questio...3.2 putVal()
再来看真正执行增加元素操作的putVal()方法,
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 当数组为空或长度为0,初始化数组容量(resize() 方法是初始化或者扩容用的)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算数组下标 i = (n-1) & hash
// 如果这个位置没有元素,则直接创建Node并存值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 这个位置已有元素
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// hash值、key值相等,用e变量获取到当前位置这个元素的引用,后面用于替换已有的值
e = p;
else if (p instanceof TreeNode)
// 当前是以红黑树方式存储,执行其特有的putVal方法 -- putTreeVal
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 当前是以链表方式存储,开始遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 这里是插入到链表尾部!
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 超过阈值,存储方式转化成红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
// onlyIfAbsent 如果为true - 不覆盖已存在的值
// 把新值赋值进去
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 记录修改次数
++modCount;
// 判断元素数量是否超过阈值 超过则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
3.3 HashMap 的长度为什么默认初始长度是16,并且每次resize()的时候,长度必须是2的幂次方?
这是一个常见的面试题。这个问题描述的设计,实际上为了服务于从Key映射到数组下标index的Hash算法。
前面提到了,我们为了让HashMap存储高效,应该尽量减少哈希碰撞,也就是说,应该让元素分配得尽可能均匀。
Hash 值的范围值 -2147483648 到 2147483647 ,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。
所以才需要一个映射的算法。这个计算方式就是3.2中有出现的 (n - 1) & hash 。
我们来进一步演示一下这个算法:
- 假设有一个
key="book" - 计算
book的hashCode值,结果为十进制的3029737,二进制的101110001110101110 1001。 - 假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
- 把以上两个结果做 与运算 ,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
通过这种 与运算 的方式,能够和取模运算一样的效果 hashCode % length ,在上述例子中就是 3029737 % 16=9 。
并且通过位运算的方式大大提高了性能。
可能到这里,你还是不知道为什么长度必须是2的幂次方,也是因为这种位运算的方法。
长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。如果HashMap的长度不是2的幂次方,会出现某些index永远不会出现的情况,这个显然不符合均匀分布的原则和期望。所以在源码里面一直都在强调 power-of-two expansion 和 size must be power of two 。
另外,HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
4. HashMap 扩容
接下来我们来讲讲HashMap扩容相关的知识。
4.1 扩容
HashMap的初始长度是16,假设HashMap中的键值对一直在增加,但是table数组容量一直不变,那么就会发生哈希碰撞,查找的效率肯定会越来越低。所以当键值对数量超过某个阈值的时候,HashMap就会执行扩容操作。
那么扩容的阈值是怎么计算的呢?
阈值 = 数组长度 * 负载因子
threshold = capacity * loadFactor
每次扩容后,threshold 加倍
上述计算就出现在resize()方法中。下面会详细解析这个方法。我们先继续往下讲。
loadFactor这个参数,我们之前提到过, 负载因子是权衡资源利用率与分配空间的系数 。至于为什么是0.75呢?这个实际上就是一个作者认为比较好的权衡,当然你也可以通过构造方法手动设置负载因子 。 public HashMap(int initialCapacity, float loadFactor) {...) 。
接下去再来到这里的主角resize()方法
final Node<K,V>[] resize() {
// 旧数组引用
Node<K,V>[] oldTab = table;
// 旧数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧阈值
int oldThr = threshold;
// 新数组长度、新阈值
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
// 旧数组已经超过了数组的最大容量
// 阈值改成最大,直接返回旧数组,不操作了
threshold = Integer.MAX_VALUE;
return oldTab;
}
// newCap 变成原来的 两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 执行扩容操作,新阈值 = 旧阈值 * 2
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
// 初始阈值被手动设置过
// 数组容量 = 初始阈值
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 初始化操作
// 数组容量 = 默认初始容量
newCap = DEFAULT_INITIAL_CAPACITY;
// 初始阈值 = 容量 * 默认负载因子
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// 如果在前面阈值都没有被设置过
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 更新table引用的数组
table = newTab;
if (oldTab != null) {
// 扩容
for (int j = 0; j < oldCap; ++j) {
// 遍历旧数组
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 取出这个位置的头节点
// 把旧引用取消,方便垃圾回收
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 红黑树的处理
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
....
}
}
}
}
return newTab;
}
// 链表的处理 这个链表处理实际上非常的巧妙
// 定义了两条链
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
上述代码红黑树和链表的处理不知道大家看懂了没有,我反正在第一次看的时候有点晕乎。但是理解了之后有感觉非常的巧妙。
拿链表处理打比方,它干的就是把在遍历旧的table数组的时候,把该位置的链表分成high链表和low链表。具体是什么意思呢?看下下面的举例。
- 有一个size为16的HashMap。有A/B/C/D/E/F六个元素,其中A/B/C的Hash值为5,D/E/F的Hash值为21,我们知道计算数组下标的方法是 与运算(效果相当于取模运算) ,这样计算出来, A/B/C/D/E/F的index = 5 ,都会被存在index=5的位置上中。
- 假设它们是依次插入,那么在index为5的位置上,就会有
A->B->C->D->E->F这样一个链表。 - 当这个HashMap要进行扩容的时候,此时我们有旧数组oldTable[],容量为16,新数组newTable[],容量为32(扩容数组容量加倍)。
- 当遍历到旧数组index=5的位置的时候,进入到上面提到的链表处理的代码段中,对链表上的元素进行
Hash & oldCapacity的操作,Hash值为5的A/B/C计算之后为0,被分到了low链表,Hash为21的D/E/F被分到了high链表。 - 然后把low链表放入新数组的index=5的位置,把high链表放入到新数组的index=5+16=21的位置。
红黑树相关的操作虽然代码不同,但是实际上要干的事情是一样的。就是把 相同位置的不同Hash大小的链表元素在新table数组中进行分离 。希望讲到这里你能听懂。
4.2 HashMap 死链问题
Java7的HashMap会存在死循环的问题,主要原因就在于,Java7中,HashMap扩容转移后 ,前后链表顺序倒置,在转移过程中其他线程修改了原来链表中节点的引用关系,导致在某Hash桶位置形成了环形链表,此时get(key),如果key不存在于这个HashMap且key的Hash结果等于那个形成了循环链表的Hash位置,那么程序就会进入死循环 ;
Java8在同样的前提下并不会引起死循环,原因是 Java8扩容转移后前后链表顺序不变,保持之前节点的引用关系 。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
// JDK8 移出了hashSeed计算,因为计算时会调用Random.nextInt(),存在性能问题
// 很重要的transfer()
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 在此步骤完成之前,旧表上依然可以进行元素的增加操作,这就是对象丢失原因之一
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
// 寥寥几行,却极为重要
void transfer(Entry[] newTable, boolean rehash) {
// newCapacity 是旧表的两倍,这个扩容大小
int newCapacity = newTable.length;
// 使用foreach 方式遍历整个数组下标
for (Entry<K,V> e : table) {
// 如果在这个slot上面存在元素,则开始遍历上面的链表,知道e==null,退出循环
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 当前元素总是直接放在数组下标的slot上,而不是放在链表的最后
// 倒序插入新表
// 这里是形成死链的关键步骤
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
延伸阅读。
https://www.yuque.com/docs/sh...
5. Java 8 与 Java 7对比
- 发生hash冲突时, Java7会在链表头部插入,Java8会在链表尾部插入
- 扩容后转移数据, Java7转移前后链表顺序会倒置,Java8还是保持原来的顺序
- 引入红黑树的Java8极大程度地优化了HashMap的性能‘
- put 操作达到阈值时,Java7中是先扩容再新增元素,Java8是先新增元素再扩容;
- Java 8 改进了 hash() 扰动函数,提高了性能
6. 为什么要使用红黑树?
很多人可能都会答上一句,为了提高查找性能,但更确切地来说的话,采用红黑树的方法是为了提高 在极端哈希冲突的情况 下提高HashMap的性能。
极端哈希冲突的情况下,去测量Java7和Java8版本的HashMap的查询性能差距。
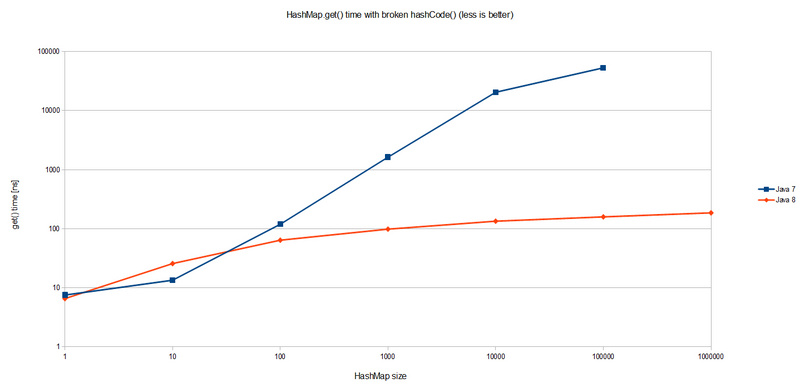 Java 7的结果是可以预期的。 HashMap.get()的性能损耗与HashMap本身的大小成比例增长。 由于所有键值对都在一个巨大的链表中的同一个桶中,查找一个条目需要平均遍历一半这样的列表(大小为n)。 因此O(n)复杂性在图上可视化。
Java 7的结果是可以预期的。 HashMap.get()的性能损耗与HashMap本身的大小成比例增长。 由于所有键值对都在一个巨大的链表中的同一个桶中,查找一个条目需要平均遍历一半这样的列表(大小为n)。 因此O(n)复杂性在图上可视化。
与此相对的是Java8,性能提高了很多,发生灾难性哈希冲突的情况下,在JDK 8上执行的相同基准测试会产生O(logn)最差情况下的性能。
关于此处的算法优化实际上在 JEP-180 中有描述到,
另外如果Key对象如果不是Comparable的话,那么发生重大哈希冲突时,插入和删除元素的效率会变很差。(因为底层实现时红黑树,需要通过compare方法去确定顺序)
当HashMap想要为一个键找到对应的位置时,它会首先检查新键和当前检索到的键之间是否可以比较(也就是实现了Comparable接口)。如果不能比较,它就会通过调用tieBreakOrder(Objecta,Object b) 方法来对它们进行比较。这个方法首先会比较两个键对象的类名,如果相等再调用System.identityHashCode 方法进行比较。这整个过程对于我们要插入的500000个元素来说是很耗时的。另一种情况是,如果键对象是可比较的,整个流程就会简化很多。因为键对象自身定义了如何与其它键对象进行比较,就没有必要再调用其他的方法,所以整个插入或查找的过程就会快很多。值得一提的是,在两个可比的键相等时(compareTo 方法返回 0)的情况下,仍然会调用tieBreakOrder 方法。
又可能会有人说了,哪有这么极端的哈希冲突?
这个实际上是一个安全性的考虑,虽然在正常情况下很少有可能发生很多冲突。但是想象一下,如果Key来自不受信任的来源(例如从客户端收到的HTTP头名称),那么就有可能收到伪造key值,并且这种做法不难,因为哈希算法是大家都知道的,假设有人有心去伪造相同的哈希值的key值,那么你的HashMap中就会出现上述这种极端哈希冲突的情况。 现在,如果你去对这个HashMap执行多次的查询请求,就会发现程序执行查询的效率会变得很慢,cpu占用率很高,程序甚至会拒绝对外提供服务。
延伸外链: https://www.yuque.com/docs/sh...
正文到此结束
- 本文标签: 删除 id equals 数据 App 参数 http 希望 ArrayList https UI CTO list 垃圾回收 索引 ip map CEO value entity Collection ConcurrentHashMap node 安全 空间 key src IO HashTable rand tab cat 时间 Collections 性能问题 constant HashMap HashSet 源码 线程 代码 DOM 总结 1111 集合类 哈希算法 测试 description Bootstrap 遍历 final ACE 回答 构造方法 java tar IDE 解析 锁
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

