夯实Java基础系列21:Java8新特性终极指南
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
https://github.com/h2pl/Java-...
喜欢的话麻烦点下Star哈
文章首发于我的个人博客:
www.how2playlife.com
<!-- more -->
这是一个Java8新增特性的总结图。接下来让我们一次实践一下这些新特性吧
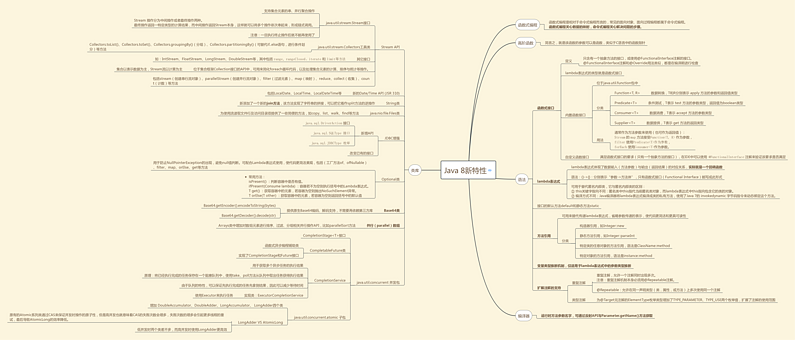
Java语言新特性
Lambda表达式
Lambda表达式(也称为闭包)是整个Java 8发行版中最受期待的在Java语言层面上的改变,Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中),或者把代码看成数据:函数式程序员对这一概念非常熟悉。在JVM平台上的很多语言(Groovy,Scala,……)从一开始就有Lambda,但是Java程序员不得不使用毫无新意的匿名类来代替lambda。
关于Lambda设计的讨论占用了大量的时间与社区的努力。可喜的是,最终找到了一个平衡点,使得可以使用一种即简洁又紧凑的新方式来构造Lambdas。在最简单的形式中,一个lambda可以由用逗号分隔的参数列表、–>符号与函数体三部分表示。例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> System.out.println( e ) );
请注意参数e的类型是由编译器推测出来的。同时,你也可以通过把参数类型与参数包括在括号中的形式直接给出参数的类型:
Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.println( e ) );
在某些情况下lambda的函数体会更加复杂,这时可以把函数体放到在一对花括号中,就像在Java中定义普通函数一样。例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> {
System.out.print( e );
System.out.print( e );
} );
Lambda可以引用类的成员变量与局部变量(如果这些变量不是final的话,它们会被隐含的转为final,这样效率更高)。例如,下面两个代码片段是等价的:
String separator = ",";
Arrays.asList( "a", "b", "d" ).forEach(
( String e ) -> System.out.print( e + separator ) );
和:
final String separator = ",";
Arrays.asList( "a", "b", "d" ).forEach(
( String e ) -> System.out.print( e + separator ) );
Lambda可能会返回一个值。返回值的类型也是由编译器推测出来的。如果lambda的函数体只有一行的话,那么没有必要显式使用return语句。下面两个代码片段是等价的:
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> e1.compareTo( e2 ) );
和:
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> {
int result = e1.compareTo( e2 );
return result;
} );
语言设计者投入了大量精力来思考如何使现有的函数友好地支持lambda。
最终采取的方法是:增加函数式接口的概念。函数式接口就是一个具有一个方法的普通接口。像这样的接口,可以被隐式转换为lambda表达式。
java.lang.Runnable与java.util.concurrent.Callable是函数式接口最典型的两个例子。
在实际使用过程中,函数式接口是容易出错的:如有某个人在接口定义中增加了另一个方法,这时,这个接口就不再是函数式的了,并且编译过程也会失败。
为了克服函数式接口的这种脆弱性并且能够明确声明接口作为函数式接口的意图,Java8增加了一种特殊的注解@FunctionalInterface(Java8中所有类库的已有接口都添加了@FunctionalInterface注解)。让我们看一下这种函数式接口的定义:
@FunctionalInterface
public interface Functional {
void method();
}
需要记住的一件事是:默认方法与静态方法并不影响函数式接口的契约,可以任意使用:
@FunctionalInterface
public interface FunctionalDefaultMethods {
void method();
default void defaultMethod() {
}
}
Lambda是Java 8最大的卖点。它具有吸引越来越多程序员到Java平台上的潜力,并且能够在纯Java语言环境中提供一种优雅的方式来支持函数式编程。更多详情可以参考官方文档。
下面看一个例子:
public class lambda和函数式编程 {
@Test
public void test1() {
List names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});
System.out.println(Arrays.toString(names.toArray()));
}
@Test
public void test2() {
List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
Collections.sort(names, (String a, String b) -> b.compareTo(a));
Collections.sort(names, (a, b) -> b.compareTo(a));
System.out.println(Arrays.toString(names.toArray()));
}
}
static void add(double a,String b) {
System.out.println(a + b);
}
@Test
public void test5() {
D d = (a,b) -> add(a,b);
// interface D {
// void get(int i,String j);
// }
//这里要求,add的两个参数和get的两个参数吻合并且返回类型也要相等,否则报错
// static void add(double a,String b) {
// System.out.println(a + b);
// }
}
@FunctionalInterface
interface D {
void get(int i,String j);
}
函数式接口
所谓的函数式接口就是只有一个抽象方法的接口,注意这里说的是抽象方法,因为Java8中加入了默认方法的特性,但是函数式接口是不关心接口中有没有默认方法的。 一般函数式接口可以使用@FunctionalInterface注解的形式来标注表示这是一个函数式接口,该注解标注与否对函数式接口没有实际的影响, 不过一般还是推荐使用该注解,就像使用@Override注解一样。
lambda表达式是如何符合 Java 类型系统的?每个lambda对应于一个给定的类型,用一个接口来说明。而这个被称为函数式接口(functional interface)的接口必须仅仅包含一个抽象方法声明。每个那个类型的lambda表达式都将会被匹配到这个抽象方法上。因此默认的方法并不是抽象的,你可以给你的函数式接口自由地增加默认的方法。
我们可以使用任意的接口作为lambda表达式,只要这个接口只包含一个抽象方法。为了保证你的接口满足需求,你需要增加@FunctionalInterface注解。编译器知道这个注解,一旦你试图给这个接口增加第二个抽象方法声明时,它将抛出一个编译器错误。
下面举几个例子
public class 函数式接口使用 {
@FunctionalInterface
interface A {
void say();
default void talk() {
}
}
@Test
public void test1() {
A a = () -> System.out.println("hello");
a.say();
}
@FunctionalInterface
interface B {
void say(String i);
}
public void test2() {
//下面两个是等价的,都是通过B接口来引用一个方法,而方法可以直接使用::来作为方法引用
B b = System.out::println;
B b1 = a -> Integer.parseInt("s");//这里的a其实换成别的也行,只是将方法传给接口作为其方法实现
B b2 = Integer::valueOf;//i与方法传入参数的变量类型一直时,可以直接替换
B b3 = String::valueOf;
//B b4 = Integer::parseInt;类型不符,无法使用
}
@FunctionalInterface
interface C {
int say(String i);
}
public void test3() {
C c = Integer::parseInt;//方法参数和接口方法的参数一样,可以替换。
int i = c.say("1");
//当我把C接口的int替换为void时就会报错,因为返回类型不一致。
System.out.println(i);
//综上所述,lambda表达式提供了一种简便的表达方式,可以将一个方法传到接口中。
//函数式接口是只提供一个抽象方法的接口,其方法由lambda表达式注入,不需要写实现类,
//也不需要写匿名内部类,可以省去很多代码,比如实现runnable接口。
//函数式编程就是指把方法当做一个参数或引用来进行操作。除了普通方法以外,静态方法,构造方法也是可以这样操作的。
}
}
请记住如果@FunctionalInterface 这个注解被遗漏,此代码依然有效。
方法引用
Lambda表达式和方法引用
有了函数式接口之后,就可以使用Lambda表达式和方法引用了。其实函数式接口的表中的函数描述符就是Lambda表达式,在函数式接口中Lambda表达式相当于匿名内部类的效果。 举个简单的例子:
public class TestLambda {
public static void execute(Runnable runnable) {
runnable.run();
}
public static void main(String[] args) {
//Java8之前
execute(new Runnable() {
@Override
public void run() {
System.out.println("run");
}
});
//使用Lambda表达式
execute(() -> System.out.println("run"));
}
}
可以看到,相比于使用匿名内部类的方式,Lambda表达式可以使用更少的代码但是有更清晰的表述。注意,Lambda表达式也不是完全等价于匿名内部类的, 两者的不同点在于this的指向和本地变量的屏蔽上。
方法引用可以看作Lambda表达式的更简洁的一种表达形式,使用::操作符,方法引用主要有三类:
指向静态方法的方法引用(例如Integer的parseInt方法,写作Integer::parseInt); 指向任意类型实例方法的方法引用(例如String的length方法,写作String::length); 指向现有对象的实例方法的方法引用(例如假设你有一个本地变量localVariable用于存放Variable类型的对象,它支持实例方法getValue,那么可以写成localVariable::getValue)。
举个方法引用的简单的例子:
Function<String, Integer> stringToInteger = (String s) -> Integer.parseInt(s);
//使用方法引用
Function<String, Integer> stringToInteger = Integer::parseInt;
方法引用中还有一种特殊的形式,构造函数引用,假设一个类有一个默认的构造函数,那么使用方法引用的形式为:
Supplier<SomeClass> c1 = SomeClass::new; SomeClass s1 = c1.get();
//等价于
Supplier<SomeClass> c1 = () -> new SomeClass(); SomeClass s1 = c1.get();
如果是构造函数有一个参数的情况:
Function<Integer, SomeClass> c1 = SomeClass::new; SomeClass s1 = c1.apply(100);
//等价于
Function<Integer, SomeClass> c1 = i -> new SomeClass(i); SomeClass s1 = c1.apply(100);
接口的默认方法
Java 8 使我们能够使用default 关键字给接口增加非抽象的方法实现。这个特性也被叫做 扩展方法(Extension Methods)。如下例所示:
public class 接口的默认方法 {
class B implements A {
// void a(){}实现类方法不能重名
}
interface A {
//可以有多个默认方法
public default void a(){
System.out.println("a");
}
public default void b(){
System.out.println("b");
}
//报错static和default不能同时使用
// public static default void c(){
// System.out.println("c");
// }
}
public void test() {
B b = new B();
b.a();
}
}
默认方法出现的原因是为了对原有接口的扩展,有了默认方法之后就不怕因改动原有的接口而对已经使用这些接口的程序造成的代码不兼容的影响。 在Java8中也对一些接口增加了一些默认方法,比如Map接口等等。一般来说,使用默认方法的场景有两个:可选方法和行为的多继承。
默认方法的使用相对来说比较简单,唯一要注意的点是如何处理默认方法的冲突。关于如何处理默认方法的冲突可以参考以下三条规则:
类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级。
如果无法依据第一条规则进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口。即如果B继承了A,那么B就比A更具体。
最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。那么如何显式地指定呢:
public class C implements B, A {
public void hello() {
B.super().hello();
}
}
使用X.super.m(..)显式地调用希望调用的方法。
Java 8用默认方法与静态方法这两个新概念来扩展接口的声明。默认方法使接口有点像Traits(Scala中特征(trait)类似于Java中的Interface,但它可以包含实现代码,也就是目前Java8新增的功能),但与传统的接口又有些不一样,它允许在已有的接口中添加新方法,而同时又保持了与旧版本代码的兼容性。
默认方法与抽象方法不同之处在于抽象方法必须要求实现,但是默认方法则没有这个要求。相反,每个接口都必须提供一个所谓的默认实现,这样所有的接口实现者将会默认继承它(如果有必要的话,可以覆盖这个默认实现)。让我们看看下面的例子:
private interface Defaulable {
// Interfaces now allow default methods, the implementer may or
// may not implement (override) them.
default String notRequired() {
return "Default implementation";
}
}
private static class DefaultableImpl implements Defaulable {
}
private static class OverridableImpl implements Defaulable {
@Override
public String notRequired() {
return "Overridden implementation";
}
}
Defaulable接口用关键字default声明了一个默认方法notRequired(),Defaulable接口的实现者之一DefaultableImpl实现了这个接口,并且让默认方法保持原样。Defaulable接口的另一个实现者OverridableImpl用自己的方法覆盖了默认方法。
Java 8带来的另一个有趣的特性是接口可以声明(并且可以提供实现)静态方法。例如:
private interface DefaulableFactory {
// Interfaces now allow static methods
static Defaulable create( Supplier< Defaulable > supplier ) {
return supplier.get();
}
}
下面的一小段代码片段把上面的默认方法与静态方法黏合到一起。
public static void main( String[] args ) {
Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new );
System.out.println( defaulable.notRequired() );
defaulable = DefaulableFactory.create( OverridableImpl::new );
System.out.println( defaulable.notRequired() );
}
这个程序的控制台输出如下:
Default implementation
Overridden implementation
在JVM中,默认方法的实现是非常高效的,并且通过字节码指令为方法调用提供了支持。默认方法允许继续使用现有的Java接口,而同时能够保障正常的编译过程。这方面好的例子是大量的方法被添加到java.util.Collection接口中去:stream(),parallelStream(),forEach(),removeIf(),……
尽管默认方法非常强大,但是在使用默认方法时我们需要小心注意一个地方:在声明一个默认方法前,请仔细思考是不是真的有必要使用默认方法,因为默认方法会带给程序歧义,并且在复杂的继承体系中容易产生编译错误。更多详情请参考官方文档
重复注解
自从Java 5引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。
重复注解机制本身必须用@Repeatable注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:
package com.javacodegeeks.java8.repeatable.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Repeatable;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
public class RepeatingAnnotations {
@Target( ElementType.TYPE )
@Retention( RetentionPolicy.RUNTIME )
public @interface Filters {
Filter[] value();
}
@Target( ElementType.TYPE )
@Retention( RetentionPolicy.RUNTIME )
@Repeatable( Filters.class )
public @interface Filter {
String value();
};
@Filter( "filter1" )
@Filter( "filter2" )
public interface Filterable {
}
public static void main(String[] args) {
for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {
System.out.println( filter.value() );
}
}
}
正如我们看到的,这里有个使用@Repeatable( Filters.class )注解的注解类Filter,Filters仅仅是Filter注解的数组,但Java编译器并不想让程序员意识到Filters的存在。这样,接口Filterable就拥有了两次Filter(并没有提到Filter)注解。
同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation( Filters.class )经编译器处理后将会返回Filters的实例)。
程序输出结果如下:
filter1
filter2
更多详情请参考官方文档
Java编译器的新特性
方法参数名字可以反射获取
很长一段时间里,Java程序员一直在发明不同的方式使得方法参数的名字能保留在Java字节码中,并且能够在运行时获取它们(比如,Paranamer类库)。最终,在Java 8中把这个强烈要求的功能添加到语言层面(通过反射API与Parameter.getName()方法)与字节码文件(通过新版的javac的–parameters选项)中。
package com.javacodegeeks.java8.parameter.names;
import java.lang.reflect.Method;
import java.lang.reflect.Parameter;
public class ParameterNames {
public static void main(String[] args) throws Exception {
Method method = ParameterNames.class.getMethod( "main", String[].class );
for( final Parameter parameter: method.getParameters() ) {
System.out.println( "Parameter: " + parameter.getName() );
}
}
}
如果不使用–parameters参数来编译这个类,然后运行这个类,会得到下面的输出:
Parameter: arg0
如果使用–parameters参数来编译这个类,程序的结构会有所不同(参数的真实名字将会显示出来):
Parameter: args
Java 类库的新特性
Java 8 通过增加大量新类,扩展已有类的功能的方式来改善对并发编程、函数式编程、日期/时间相关操作以及其他更多方面的支持。
Optional
到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google公司著名的Guava项目引入了Optional类,Guava通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到Google Guava的启发,Optional类已经成为Java 8类库的一部分。
Optional实际上是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。更多详情请参考官方文档。
我们下面用两个小例子来演示如何使用Optional类:一个允许为空值,一个不允许为空值。
public class 空指针Optional {
public static void main(String[] args) {
//使用of方法,仍然会报空指针异常
// Optional optional = Optional.of(null);
// System.out.println(optional.get());
//抛出没有该元素的异常
//Exception in thread "main" java.util.NoSuchElementException: No value present
// at java.util.Optional.get(Optional.java:135)
// at com.javase.Java8.空指针Optional.main(空指针Optional.java:14)
// Optional optional1 = Optional.ofNullable(null);
// System.out.println(optional1.get());
Optional optional = Optional.ofNullable(null);
System.out.println(optional.isPresent());
System.out.println(optional.orElse(0));//当值为空时给与初始值
System.out.println(optional.orElseGet(() -> new String[]{"a"}));//使用回调函数设置默认值
//即使传入Optional容器的元素为空,使用optional.isPresent()方法也不会报空指针异常
//所以通过optional.orElse这种方式就可以写出避免空指针异常的代码了
//输出Optional.empty。
}
}
如果Optional类的实例为非空值的话,isPresent()返回true,否从返回false。为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转化,然后返回一个新的Optional实例。orElse()方法和orElseGet()方法类似,但是orElse接受一个默认值而不是一个回调函数。下面是这个程序的输出:
Full Name is set? false
Full Name: [none]
Hey Stranger!
让我们来看看另一个例子:
Optional< String > firstName = Optional.of( "Tom" ); System.out.println( "First Name is set? " + firstName.isPresent() ); System.out.println( "First Name: " + firstName.orElseGet( () -> "[none]" ) ); System.out.println( firstName.map( s -> "Hey " + s + "!" ).orElse( "Hey Stranger!" ) ); System.out.println();
下面是程序的输出:
First Name is set? true
First Name: Tom
Hey Tom!
Stream
最新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream API极大简化了集合框架的处理(但它的处理的范围不仅仅限于集合框架的处理,这点后面我们会看到)。让我们以一个简单的Task类为例进行介绍:
Task类有一个分数的概念(或者说是伪复杂度),其次是还有一个值可以为OPEN或CLOSED的状态.让我们引入一个Task的小集合作为演示例子:
final Collection< Task > tasks = Arrays.asList(
new Task( Status.OPEN, 5 ),
new Task( Status.OPEN, 13 ),
new Task( Status.CLOSED, 8 )
);
我们下面要讨论的第一个问题是所有状态为OPEN的任务一共有多少分数?在Java 8以前,一般的解决方式用foreach循环,但是在Java 8里面我们可以使用stream:一串支持连续、并行聚集操作的元素。
// Calculate total points of all active tasks using sum()
final long totalPointsOfOpenTasks = tasks
.stream()
.filter( task -> task.getStatus() == Status.OPEN )
.mapToInt( Task::getPoints )
.sum();
System.out.println( "Total points: " + totalPointsOfOpenTasks );
程序在控制台上的输出如下:
Total points: 18
这里有几个注意事项。
第一,task集合被转换化为其相应的stream表示。然后,filter操作过滤掉状态为CLOSED的task。
下一步,mapToInt操作通过Task::getPoints这种方式调用每个task实例的getPoints方法把Task的stream转化为Integer的stream。最后,用sum函数把所有的分数加起来,得到最终的结果。
在继续讲解下面的例子之前,关于stream有一些需要注意的地方(详情在这里).stream操作被分成了中间操作与最终操作这两种。
中间操作返回一个新的stream对象。中间操作总是采用惰性求值方式,运行一个像filter这样的中间操作实际上没有进行任何过滤,相反它在遍历元素时会产生了一个新的stream对象,这个新的stream对象包含原始stream
中符合给定谓词的所有元素。
像forEach、sum这样的最终操作可能直接遍历stream,产生一个结果或副作用。当最终操作执行结束之后,stream管道被认为已经被消耗了,没有可能再被使用了。在大多数情况下,最终操作都是采用及早求值方式,及早完成底层数据源的遍历。
stream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。
stream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。
// Calculate total points of all tasks
final double totalPoints = tasks
.stream()
.parallel()
.map( task -> task.getPoints() ) // or map( Task::getPoints )
.reduce( 0, Integer::sum );
System.out.println( "Total points (all tasks): " + totalPoints );
这个例子和第一个例子很相似,但这个例子的不同之处在于这个程序是并行运行的,其次使用reduce方法来算最终的结果。
下面是这个例子在控制台的输出:
Total points (all tasks): 26.0
经常会有这个一个需求:我们需要按照某种准则来对集合中的元素进行分组。Stream也可以处理这样的需求,下面是一个例子:
// Group tasks by their status
final Map< Status, List< Task > > map = tasks
.stream()
.collect( Collectors.groupingBy( Task::getStatus ) );
System.out.println( map );
这个例子的控制台输出如下:
{CLOSED=[[CLOSED, 8]], OPEN=[[OPEN, 5], [OPEN, 13]]}
让我们来计算整个集合中每个task分数(或权重)的平均值来结束task的例子。
// Calculate the weight of each tasks (as percent of total points)
final Collection< String > result = tasks
.stream() // Stream< String >
.mapToInt( Task::getPoints ) // IntStream
.asLongStream() // LongStream
.mapToDouble( points -> points / totalPoints ) // DoubleStream
.boxed() // Stream< Double >
.mapToLong( weigth -> ( long )( weigth * 100 ) ) // LongStream
.mapToObj( percentage -> percentage + "%" ) // Stream< String>
.collect( Collectors.toList() ); // List< String >
System.out.println( result );
下面是这个例子的控制台输出:
[19%, 50%, 30%]
最后,就像前面提到的,Stream API不仅仅处理Java集合框架。像从文本文件中逐行读取数据这样典型的I/O操作也很适合用Stream API来处理。下面用一个例子来应证这一点。
final Path path = new File( filename ).toPath();
try( Stream< String > lines = Files.lines( path, StandardCharsets.UTF_8 ) ) {
lines.onClose( () -> System.out.println("Done!") ).forEach( System.out::println );
}
对一个stream对象调用onClose方法会返回一个在原有功能基础上新增了关闭功能的stream对象,当对stream对象调用close()方法时,与关闭相关的处理器就会执行。
Stream API、Lambda表达式与方法引用在接口默认方法与静态方法的配合下是Java 8对现代软件开发范式的回应。更多详情请参考官方文档。
Date/Time API (JSR 310)
Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。对日期与时间的操作一直是Java程序员最痛苦的地方之一。标准的 java.util.Date以及后来的java.util.Calendar一点没有改善这种情况(可以这么说,它们一定程度上更加复杂)。
这种情况直接导致了Joda-Time——一个可替换标准日期/时间处理且功能非常强大的Java API的诞生。Java 8新的Date-Time API (JSR 310)在很大程度上受到Joda-Time的影响,并且吸取了其精髓。新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。在设计新版API时,十分注重与旧版API的兼容性:不允许有任何的改变(从java.util.Calendar中得到的深刻教训)。如果需要修改,会返回这个类的一个新实例。
让我们用例子来看一下新版API主要类的使用方法。第一个是Clock类,它通过指定一个时区,然后就可以获取到当前的时刻,日期与时间。Clock可以替换System.currentTimeMillis()与TimeZone.getDefault()。
// Get the system clock as UTC offset final Clock clock = Clock.systemUTC(); System.out.println( clock.instant() ); System.out.println( clock.millis() );
下面是程序在控制台上的输出:
2014-04-12T15:19:29.282Z 1397315969360
我们需要关注的其他类是LocaleDate与LocalTime。LocaleDate只持有ISO-8601格式且无时区信息的日期部分。相应的,LocaleTime只持有ISO-8601格式且无时区信息的时间部分。LocaleDate与LocalTime都可以从Clock中得到。
// Get the local date and local time
final LocalDate date = LocalDate.now();
final LocalDate dateFromClock = LocalDate.now( clock );
System.out.println( date );
System.out.println( dateFromClock );
// Get the local date and local time
final LocalTime time = LocalTime.now();
final LocalTime timeFromClock = LocalTime.now( clock );
System.out.println( time );
System.out.println( timeFromClock );
下面是程序在控制台上的输出:
2014-04-12 2014-04-12 11:25:54.568 15:25:54.568
下面是程序在控制台上的输出:
2014-04-12T11:47:01.017-04:00[America/New_York] 2014-04-12T15:47:01.017Z 2014-04-12T08:47:01.017-07:00[America/Los_Angeles]
最后,让我们看一下Duration类:在秒与纳秒级别上的一段时间。Duration使计算两个日期间的不同变的十分简单。下面让我们看一个这方面的例子。
// Get duration between two dates final LocalDateTime from = LocalDateTime.of( 2014, Month.APRIL, 16, 0, 0, 0 ); final LocalDateTime to = LocalDateTime.of( 2015, Month.APRIL, 16, 23, 59, 59 ); final Duration duration = Duration.between( from, to ); System.out.println( "Duration in days: " + duration.toDays() ); System.out.println( "Duration in hours: " + duration.toHours() );
上面的例子计算了两个日期2014年4月16号与2014年4月16号之间的过程。下面是程序在控制台上的输出:
Duration in days: 365
Duration in hours: 8783
对Java 8在日期/时间API的改进整体印象是非常非常好的。一部分原因是因为它建立在“久战杀场”的Joda-Time基础上,另一方面是因为用来大量的时间来设计它,并且这次程序员的声音得到了认可。更多详情请参考官方文档。
并行(parallel)数组
Java 8增加了大量的新方法来对数组进行并行处理。可以说,最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度。下面的例子展示了新方法(parallelXxx)的使用。
package com.javacodegeeks.java8.parallel.arrays;
import java.util.Arrays;
import java.util.concurrent.ThreadLocalRandom;
public class ParallelArrays {
public static void main( String[] args ) {
long[] arrayOfLong = new long [ 20000 ];
Arrays.parallelSetAll( arrayOfLong,
index -> ThreadLocalRandom.current().nextInt( 1000000 ) );
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
i -> System.out.print( i + " " ) );
System.out.println();
Arrays.parallelSort( arrayOfLong );
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
i -> System.out.print( i + " " ) );
System.out.println();
}
}
上面的代码片段使用了parallelSetAll()方法来对一个有20000个元素的数组进行随机赋值。然后,调用parallelSort方法。这个程序首先打印出前10个元素的值,之后对整个数组排序。这个程序在控制台上的输出如下(请注意数组元素是随机生产的):
Unsorted: 591217 891976 443951 424479 766825 351964 242997 642839 119108 552378
Sorted: 39 220 263 268 325 607 655 678 723 793
CompletableFuture
在Java8之前,我们会使用JDK提供的Future接口来进行一些异步的操作,其实CompletableFuture也是实现了Future接口, 并且基于ForkJoinPool来执行任务,因此本质上来讲,CompletableFuture只是对原有API的封装, 而使用CompletableFuture与原来的Future的不同之处在于可以将两个Future组合起来,或者如果两个Future是有依赖关系的,可以等第一个执行完毕后再实行第二个等特性。
先来看看基本的使用方式:
public Future<Double> getPriceAsync(final String product) {
final CompletableFuture<Double> futurePrice = new CompletableFuture<>();
new Thread(() -> {
double price = calculatePrice(product);
futurePrice.complete(price); //完成后使用complete方法,设置future的返回值
}).start();
return futurePrice;
}
得到Future之后就可以使用get方法来获取结果,CompletableFuture提供了一些工厂方法来简化这些API,并且使用函数式编程的方式来使用这些API,例如:
Fufure<Double> price = CompletableFuture.supplyAsync(() -> calculatePrice(product));
代码是不是一下子简洁了许多呢。之前说了,CompletableFuture可以组合多个Future,不管是Future之间有依赖的,还是没有依赖的。
如果第二个请求依赖于第一个请求的结果,那么可以使用thenCompose方法来组合两个Future
public List<String> findPriceAsync(String product) {
List<CompletableFutute<String>> priceFutures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> task.getPrice(product),executor))
.map(future -> future.thenApply(Work::parse))
.map(future -> future.thenCompose(work -> CompletableFuture.supplyAsync(() -> Count.applyCount(work), executor)))
.collect(Collectors.toList());
return priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());
}
上面这段代码使用了thenCompose来组合两个CompletableFuture。supplyAsync方法第二个参数接受一个自定义的Executor。 首先使用CompletableFuture执行一个任务,调用getPrice方法,得到一个Future,之后使用thenApply方法,将Future的结果应用parse方法, 之后再使用执行完parse之后的结果作为参数再执行一个applyCount方法,然后收集成一个CompletableFuture<String>的List, 最后再使用一个流,调用CompletableFuture的join方法,这是为了等待所有的异步任务执行完毕,获得最后的结果。
注意,这里必须使用两个流,如果在一个流里调用join方法,那么由于Stream的延迟特性,所有的操作还是会串行的执行,并不是异步的。
再来看一个两个Future之间没有依赖关系的例子:
Future<String> futurePriceInUsd = CompletableFuture.supplyAsync(() -> shop.getPrice(“price1”))
.thenCombine(CompletableFuture.supplyAsync(() -> shop.getPrice(“price2”)), (s1, s2) -> s1 + s2);
这里有两个异步的任务,使用thenCombine方法来组合两个Future,thenCombine方法的第二个参数就是用来合并两个Future方法返回值的操作函数。
有时候,我们并不需要等待所有的异步任务结束,只需要其中的一个完成就可以了,CompletableFuture也提供了这样的方法:
//假设getStream方法返回一个Stream<CompletableFuture<String>> CompletableFuture[] futures = getStream(“listen”).map(f -> f.thenAccept(System.out::println)).toArray(CompletableFuture[]::new); //等待其中的一个执行完毕 CompletableFuture.anyOf(futures).join(); 使用anyOf方法来响应CompletableFuture的completion事件。
Java虚拟机(JVM)的新特性
PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。
总结
更多展望:Java 8通过发布一些可以增加程序员生产力的特性来推进这个伟大的平台的进步。现在把生产环境迁移到Java 8还为时尚早,但是在接下来的几个月里,它会被大众慢慢的接受。毫无疑问,现在是时候让你的代码与Java 8兼容,并且在Java 8足够安全稳定的时候迁移到Java 8。
参考文章
https://blog.csdn.net/shuaici...
https://blog.csdn.net/qq_3490...
https://www.jianshu.com/p/4df...
https://www.cnblogs.com/yangz...
https://www.cnblogs.com/Jackp...
微信公众号
Java技术江湖
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
Java工程师必备学习资源:一些Java工程师常用学习资源,关注公众号后,后台回复关键字 “Java” 即可免费无套路获取。

个人公众号:黄小斜
作者是跨考软件工程的 985 硕士,自学 Java 两年,拿到了 BAT 等近十家大厂 offer,从技术小白成长为阿里工程师。
作者专注于 JAVA 后端技术栈,热衷于分享程序员干货、学习经验、求职心得和程序人生,目前黄小斜的CSDN博客有百万+访问量,知乎粉丝2W+,全网已有10W+读者。
黄小斜是一个斜杠青年,坚持学习和写作,相信终身学习的力量,希望和更多的程序员交朋友,一起进步和成长!
关注公众号【黄小斜】后回复【原创电子书】即可领取我原创的电子书《菜鸟程序员修炼手册:从技术小白到阿里巴巴Java工程师》
程序员3T技术学习资源:一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 “资料” 即可免费无套路获取。

正文到此结束
- 本文标签: 数据 需求 DOM 开发 http scala id 字节码 rand 编译 线程 UI 代码 parse 参数 ask trait 希望 JVM UTC XEN find map GitHub 遍历 软件 src 微信公众号 Java集合 本质 tag java tar sql SDN 程序员 list Java类 免费 Collection 工程师 并发 spring Google App value java基础 2015 IO ELK stream mysql js 安全 多线程 CTO Collections 总结 文章 executor 专注 lambda linux https apr API 空间 Docker final ACE 函数式编程 springboot 构造方法 git 阿里巴巴 IDE 时间 实例 并发编程 博客 处理器 分布式 静态方法 tab 集群
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

