你的环境有问题吧?--byte数组转字符串的疑惑
1. 故事背景
小T是个测试MM,小C是个程序猿,今天早上他们又为一个bug吵架了。
小T:“这个显示是bug,在我的浏览器上显示不正确”

小C:“这个bug我不认,在我的电脑上显示正常,是你的环境有问题吧?”
小T:“我不管,反正我这个显示不正确,就是个bug”
小C:“我。。。。。。。。。。。。。。。。。”
最终leader出面,大家做到一起查找问题。(为防止公司信息泄露,下面为模拟程序)
public static void main(String[] args) throws UnsupportedEncodingException {
byte bytes[] = new byte[256];
for (int i = 0; i < 256; i++)
bytes[i] = (byte)i;
String str = new String(bytes);
for (int i = 0, n = str.length(); i < n; i++)
System.out.print((int)str.charAt(i) + " ");
}
小T首先展示程序输出:
小C也不甘示弱,在自己的电脑上运行,得到如下结果:
leader检查了小C和小T的程序后,发现程序完全一样,为什么会出现这种情况呢?
2. 事故查找
经debug发现,小T和小C的程序在
String str = new String(bytes);
这段代码时发生了不同:
小C的代码str为:
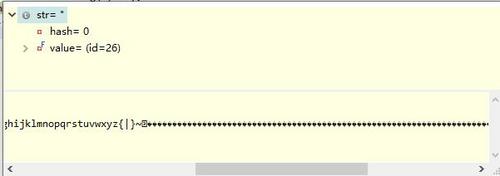
小T的代码为:

其中65533的图片显示为:

推测可能是编码问题,深入其源码内部,看看
/**
* Constructs a new {@code String} by decoding the specified array of bytes
* using the platform's default charset. The length of the new {@code
* String} is a function of the charset, and hence may not be equal to the
* length of the byte array.
*
* <p> The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @since JDK1.1
*/
public String(byte bytes[]) {
this(bytes, 0, bytes.length);
}
翻译过来就是:在通过解码使用平台缺省字符集的指定byte 数组来构造一个新的String 时,该新String 的长度是字符集的一个函数,因此,它可能不等于byte 数组的长度。当给定的所有字节在缺省字符集中并非全部有效时,这个构造器的行为是不确定的。
罪魁祸首就是String(byte[])构造。
3. 问题解决
小C承认了自己的错误,小T也高兴得提了个bug。接下来小C就要修改掉这个bug了。
public static void main(String[] args) throws UnsupportedEncodingException {
byte bytes[] = new byte[256];
for (int i = 0; i < 256; i++)
bytes[i] = (byte)i;
String str = new String(bytes,"ISO-8859-1");
for (int i = 0, n = str.length(); i < n; i++)
System.out.print((int)str.charAt(i) + " ");
}
指定字符集后,小T和小C又能愉快得玩耍了。
总结
每当你要将一个byte 序列转换成一个String 时,你都在使用某一个字符集,不管你是否显式地指定了它。如果你想让你的程序的行为是可预知的,那么就请你在每次使用字符集时都明确地指定。
参考资料:
【1】java解惑
【2】https://www.jianshu.com/p/52fd2a304228
【3】http://www.mytju.com/classcode/tools/encode_utf8.asp
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

