Java集合详解2:一文读懂Queue和LinkedList
《Java集合详解系列》是我在完成夯实Java基础篇的系列博客后准备开始写的新系列。
这些文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
https://github.com/h2pl/Java-...
喜欢的话麻烦点下Star、fork哈
文章首发于我的个人博客:
www.how2playlife.com
本文参考 http://cmsblogs.com/?p=155
和
https://www.jianshu.com/p/0e8...LinkedList
概述
LinkedList与ArrayList一样实现List接口,只是ArrayList是List接口的大小可变数组的实现,LinkedList是List接口链表的实现。基于链表实现的方式使得LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList逊色些。
LinkedList实现所有可选的列表操作,并允许所有的元素包括null。
除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
此类实现 Deque 接口,为 add、poll 提供先进先出队列操作,以及其他堆栈和双端队列操作。
所有操作都是按照双重链接列表的需要执行的。在列表中编索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。
同时,与ArrayList一样此实现不是同步的。
(以上摘自JDK 6.0 API)。
源码分析
定义
首先我们先看LinkedList的定义:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
从这段代码中我们可以清晰地看出LinkedList继承AbstractSequentialList,实现List、Deque、Cloneable、Serializable。其中AbstractSequentialList提供了 List 接口的骨干实现,从而最大限度地减少了实现受“连续访问”数据存储(如链接列表)支持的此接口所需的工作,从而以减少实现List接口的复杂度。Deque一个线性 collection,支持在两端插入和移除元素,定义了双端队列的操作。
属性
在LinkedList中提供了两个基本属性size、header。
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;
其中size表示的LinkedList的大小,header表示链表的表头,Entry为节点对象。
private static class Entry<E> {
E element; //元素节点
Entry<E> next; //下一个元素
Entry<E> previous; //上一个元素
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
上面为Entry对象的源代码,Entry为LinkedList的内部类,它定义了存储的元素。该元素的前一个元素、后一个元素,这是典型的双向链表定义方式。
构造方法
LinkedList提供了两个构造方法:LinkedList()和LinkedList(Collection<? extends E> c)。
/**
* 构造一个空列表。
*/
public LinkedList() {
header.next = header.previous = header;
}
/**
* 构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列。
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
LinkedList()构造一个空列表。里面没有任何元素,仅仅只是将header节点的前一个元素、后一个元素都指向自身。
LinkedList(Collection<? extends E> c): 构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列。该构造函数首先会调用LinkedList(),构造一个空列表,然后调用了addAll()方法将Collection中的所有元素添加到列表中。以下是addAll()的源代码:
/**
* 添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
/**
* 将指定 collection 中的所有元素从指定位置开始插入此列表。其中index表示在其中插入指定collection中第一个元素的索引
*/
public boolean addAll(int index, Collection<? extends E> c) {
//若插入的位置小于0或者大于链表长度,则抛出IndexOutOfBoundsException异常
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length; //插入元素的个数
//若插入的元素为空,则返回false
if (numNew == 0)
return false;
//modCount:在AbstractList中定义的,表示从结构上修改列表的次数
modCount++;
//获取插入位置的节点,若插入的位置在size处,则是头节点,否则获取index位置处的节点
Entry<E> successor = (index == size ? header : entry(index));
//插入位置的前一个节点,在插入过程中需要修改该节点的next引用:指向插入的节点元素
Entry<E> predecessor = successor.previous;
//执行插入动作
for (int i = 0; i < numNew; i++) {
//构造一个节点e,这里已经执行了插入节点动作同时修改了相邻节点的指向引用
//
Entry<E> e = new Entry<E>((E) a[i], successor, predecessor);
//将插入位置前一个节点的下一个元素引用指向当前元素
predecessor.next = e;
//修改插入位置的前一个节点,这样做的目的是将插入位置右移一位,保证后续的元素是插在该元素的后面,确保这些元素的顺序
predecessor = e;
}
successor.previous = predecessor;
//修改容量大小
size += numNew;
return true;
}
在addAll()方法中,涉及到了两个方法,一个是entry(int index),该方法为LinkedList的私有方法,主要是用来查找index位置的节点元素。
/**
* 返回指定位置(若存在)的节点元素
*/
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: "
+ size);
//头部节点
Entry<E> e = header;
//判断遍历的方向
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
从该方法有两个遍历方向中我们也可以看出LinkedList是双向链表,这也是在构造方法中为什么需要将header的前、后节点均指向自己。
如果对数据结构有点了解,对上面所涉及的内容应该问题,我们只需要清楚一点:LinkedList是双向链表,其余都迎刃而解。
由于篇幅有限,下面将就LinkedList中几个常用的方法进行源码分析。
增加方法
add(E e): 将指定元素添加到此列表的结尾。
public boolean add(E e) {
addBefore(e, header);
return true;
}
该方法调用addBefore方法,然后直接返回true,对于addBefore()而已,它为LinkedList的私有方法。
private Entry<E> addBefore(E e, Entry<E> entry) {
//利用Entry构造函数构建一个新节点 newEntry,
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
//修改newEntry的前后节点的引用,确保其链表的引用关系是正确的
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
//容量+1
size++;
//修改次数+1
modCount++;
return newEntry;
}
在addBefore方法中无非就是做了这件事:构建一个新节点newEntry,然后修改其前后的引用。
LinkedList还提供了其他的增加方法:
add(int index, E element):在此列表中指定的位置插入指定的元素。 addAll(Collection<? extends E> c):添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。 addAll(int index, Collection<? extends E> c):将指定 collection 中的所有元素从指定位置开始插入此列表。 AddFirst(E e): 将指定元素插入此列表的开头。 addLast(E e): 将指定元素添加到此列表的结尾。
移除方法
remove(Object o):从此列表中移除首次出现的指定元素(如果存在)。该方法的源代码如下:
public boolean remove(Object o) {
if (o==null) {
for (Entry<E> e = header.next; e != header; e = e.next) {
if (e.element==null) {
remove(e);
return true;
}
}
} else {
for (Entry<E> e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
}
该方法首先会判断移除的元素是否为null,然后迭代这个链表找到该元素节点,最后调用remove(Entry<E> e),remove(Entry<E> e)为私有方法,是LinkedList中所有移除方法的基础方法,如下:
private E remove(Entry<E> e) {
if (e == header)
throw new NoSuchElementException();
//保留被移除的元素:要返回
E result = e.element;
//将该节点的前一节点的next指向该节点后节点
e.previous.next = e.next;
//将该节点的后一节点的previous指向该节点的前节点
//这两步就可以将该节点从链表从除去:在该链表中是无法遍历到该节点的
e.next.previous = e.previous;
//将该节点归空
e.next = e.previous = null;
e.element = null;
size--;
modCount++;
return result;
}
其他的移除方法:
clear(): 从此列表中移除所有元素。 remove():获取并移除此列表的头(第一个元素)。 remove(int index):移除此列表中指定位置处的元素。 remove(Objec o):从此列表中移除首次出现的指定元素(如果存在)。 removeFirst():移除并返回此列表的第一个元素。 removeFirstOccurrence(Object o):从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。 removeLast():移除并返回此列表的最后一个元素。 removeLastOccurrence(Object o):从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。
查找方法
对于查找方法的源码就没有什么好介绍了,无非就是迭代,比对,然后就是返回当前值。 get(int index):返回此列表中指定位置处的元素。 getFirst():返回此列表的第一个元素。 getLast():返回此列表的最后一个元素。 indexOf(Object o):返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。 lastIndexOf(Object o):返回此列表中最后出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
Queue
Queue接口定义了队列数据结构,元素是有序的(按插入顺序),先进先出。Queue接口相关的部分UML类图如下:
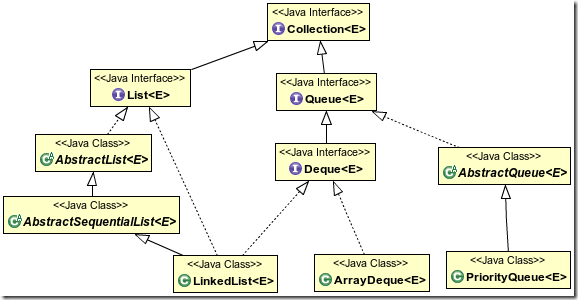
DeQueue
DeQueue(Double-ended queue)为接口,继承了Queue接口,创建双向队列,灵活性更强,可以前向或后向迭代,在队头队尾均可心插入或删除元素。它的两个主要实现类是ArrayDeque和LinkedList。
ArrayDeque (底层使用循环数组实现双向队列)
创建
public ArrayDeque() {
// 默认容量为16
elements = new Object[16];
}
public ArrayDeque(int numElements) {
// 指定容量的构造函数
allocateElements(numElements);
}
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;// 最小容量为8
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
// 如果要分配的容量大于等于8,扩大成2的幂(是为了维护头、尾下标值);否则使用最小容量8
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
elements = new Object[initialCapacity];
}
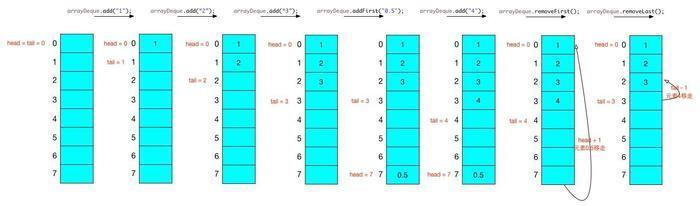
add操作
add(E e) 调用 addLast(E e) 方法:
public void addLast(E e) {
if (e == null)
throw new NullPointerException("e == null");
elements[tail] = e; // 根据尾索引,添加到尾端
// 尾索引+1,并与数组(length - 1)进行取‘&’运算,因为length是2的幂,所以(length-1)转换为2进制全是1,
// 所以如果尾索引值 tail 小于等于(length - 1),那么‘&’运算后仍为 tail 本身;如果刚好比(length - 1)大1时,
// ‘&’运算后 tail 便为0(即回到了数组初始位置)。正是通过与(length - 1)进行取‘&’运算来实现数组的双向循环。
// 如果尾索引和头索引重合了,说明数组满了,进行扩容。
if ((tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();// 扩容为原来的2倍
}
addFirst(E e) 的实现:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException("e == null");
// 此处如果head为0,则-1(1111 1111 1111 1111 1111 1111 1111 1111)与(length - 1)进行取‘&’运算,结果必然是(length - 1),即回到了数组的尾部。
elements[head = (head - 1) & (elements.length - 1)] = e;
// 如果尾索引和头索引重合了,说明数组满了,进行扩容
if (head == tail)
doubleCapacity();
}
remove操作
remove()方法最终都会调对应的poll()方法:
public E poll() {
return pollFirst();
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked") E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
// 头索引 + 1
head = (h + 1) & (elements.length - 1);
return result;
}
public E pollLast() {
// 尾索引 - 1
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked") E result = (E) elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t;
return result;
}
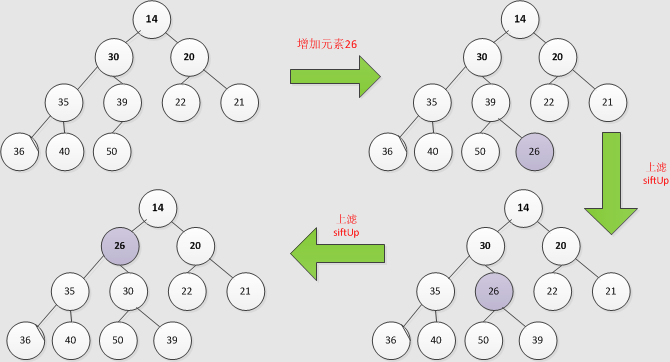
PriorityQueue(底层用数组实现堆的结构)
优先队列内部维护着一个堆,每次取数据的时候都从堆顶拿数据(堆顶的优先级最高),这就是优先队列的原理。
add 添加方法
public boolean add(E e) {
return offer(e); // add方法内部调用offer方法
}
public boolean offer(E e) {
if (e == null) // 元素为空的话,抛出NullPointerException异常
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length) // 如果当前用堆表示的数组已经满了,调用grow方法扩容
grow(i + 1); // 扩容
size = i + 1; // 元素个数+1
if (i == 0) // 堆还没有元素的情况
queue[0] = e; // 直接给堆顶赋值元素
else // 堆中已有元素的情况
siftUp(i, e); // 重新调整堆,从下往上调整,因为新增元素是加到最后一个叶子节点
return true;
}
private void siftUp(int k, E x) {
if (comparator != null) // 比较器存在的情况下
siftUpUsingComparator(k, x); // 使用比较器调整
else // 比较器不存在的情况下
siftUpComparable(k, x); // 使用元素自身的比较器调整
}
private void siftUpUsingComparator(int k, E x) {
while (k > 0) { // 一直循环直到父节点还存在
int parent = (k - 1) >>> 1; // 找到父节点索引,等同于(k - 1)/ 2
Object e = queue[parent]; // 获得父节点元素
// 新元素与父元素进行比较,如果满足比较器结果,直接跳出,否则进行调整
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e; // 进行调整,新位置的元素变成了父元素
k = parent; // 新位置索引变成父元素索引,进行递归操作
}
queue[k] = x; // 新添加的元素添加到堆中
}
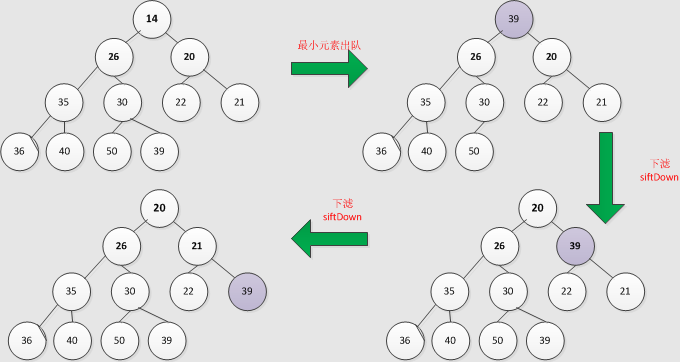
poll,出队方法
public E poll() {
if (size == 0)
return null;
int s = --size; // 元素个数-1
modCount++;
E result = (E) queue[0]; // 得到堆顶元素
E x = (E) queue[s]; // 最后一个叶子节点
queue[s] = null; // 最后1个叶子节点置空
if (s != 0)
siftDown(0, x); // 从上往下调整,因为删除元素是删除堆顶的元素
return result;
}
private void siftDown(int k, E x) {
if (comparator != null) // 比较器存在的情况下
siftDownUsingComparator(k, x); // 使用比较器调整
else // 比较器不存在的情况下
siftDownComparable(k, x); // 使用元素自身的比较器调整
}
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1; // 只需循环节点个数的一般即可
while (k < half) {
int child = (k << 1) + 1; // 得到父节点的左子节点索引,即(k * 2)+ 1
Object c = queue[child]; // 得到左子元素
int right = child + 1; // 得到父节点的右子节点索引
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0) // 左子节点跟右子节点比较,取更大的值
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0) // 然后这个更大的值跟最后一个叶子节点比较
break;
queue[k] = c; // 新位置使用更大的值
k = child; // 新位置索引变成子元素索引,进行递归操作
}
queue[k] = x; // 最后一个叶子节点添加到合适的位置
}
remove,删除队列元素
public boolean remove(Object o) {
int i = indexOf(o); // 找到数据对应的索引
if (i == -1) // 不存在的话返回false
return false;
else { // 存在的话调用removeAt方法,返回true
removeAt(i);
return true;
}
}
private E removeAt(int i) {
modCount++;
int s = --size; // 元素个数-1
if (s == i) // 如果是删除最后一个叶子节点
queue[i] = null; // 直接置空,删除即可,堆还是保持特质,不需要调整
else { // 如果是删除的不是最后一个叶子节点
E moved = (E) queue[s]; // 获得最后1个叶子节点元素
queue[s] = null; // 最后1个叶子节点置空
siftDown(i, moved); // 从上往下调整
if (queue[i] == moved) { // 如果从上往下调整完毕之后发现元素位置没变,从下往上调整
siftUp(i, moved); // 从下往上调整
if (queue[i] != moved)
return moved;
}
}
return null;
}
先执行 siftDown() 下滤过程:
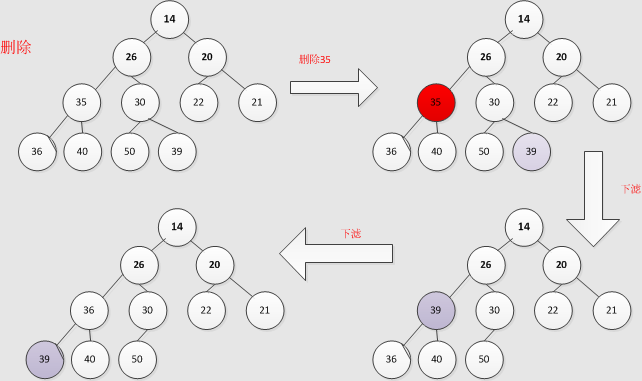
再执行 siftUp() 上滤过程:
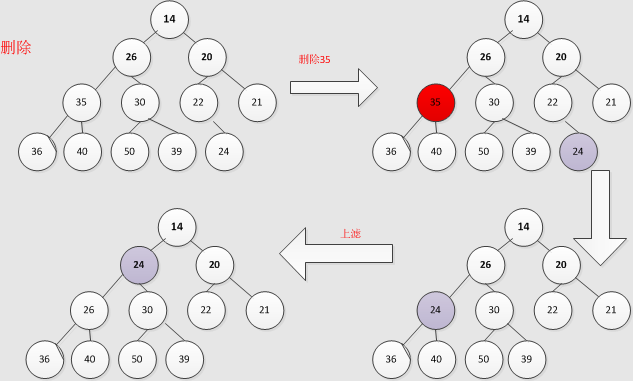
总结和同步的问题
1、jdk内置的优先队列PriorityQueue内部使用一个堆维护数据,每当有数据add进来或者poll出去的时候会对堆做从下往上的调整和从上往下的调整。
2、PriorityQueue不是一个线程安全的类,如果要在多线程环境下使用,可以使用 PriorityBlockingQueue 这个优先阻塞队列。其中add、poll、remove方法都使用 ReentrantLock 锁来保持同步,take() 方法中如果元素为空,则会一直保持阻塞。
参考文章
http://cmsblogs.com/?p=155
https://www.jianshu.com/p/0e8...
https://blog.csdn.net/Faker_W...
https://blog.csdn.net/m0_3786...
https://www.iteye.com/blog/sh...
https://blog.csdn.net/weixin_...
微信公众号
Java技术江湖
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
Java工程师必备学习资源:一些Java工程师常用学习资源,关注公众号后,后台回复关键字 “Java” 即可免费无套路获取。

个人公众号:黄小斜
黄小斜是跨考软件工程的 985 硕士,自学 Java 两年,拿到了 BAT 等近十家大厂 offer,从技术小白成长为阿里工程师。
作者专注于 JAVA 后端技术栈,热衷于分享程序员干货、学习经验、求职心得和程序人生,目前黄小斜的CSDN博客有百万+访问量,知乎粉丝2W+,全网已有10W+读者。
黄小斜是一个斜杠青年,坚持学习和写作,相信终身学习的力量,希望和更多的程序员交朋友,一起进步和成长!关注公众号【黄小斜】后回复【原创电子书】即可领取我原创的电子书《菜鸟程序员修炼手册:从技术小白到阿里巴巴Java工程师》
程序员3T技术学习资源:一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 “资料” 即可免费无套路获取。

本文由博客一文多发平台 OpenWrite 发布!
正文到此结束
- 本文标签: db 集群 SDN 开发 删除 Collection 工程师 递归 源码 cat 多线程 软件 http IO ELK 类图 java 线程 API list DDL queue 专注 zab spring find 数据 Docker src 微信公众号 springboot 构造方法 mysql tar UI 遍历 同步 免费 分布式 equals linux sql 程序员 java基础 文章 id ArrayList https 安全 代码 总结 1111 希望 LinkedList git 阿里巴巴 GitHub 锁 博客 Java集合 索引
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

