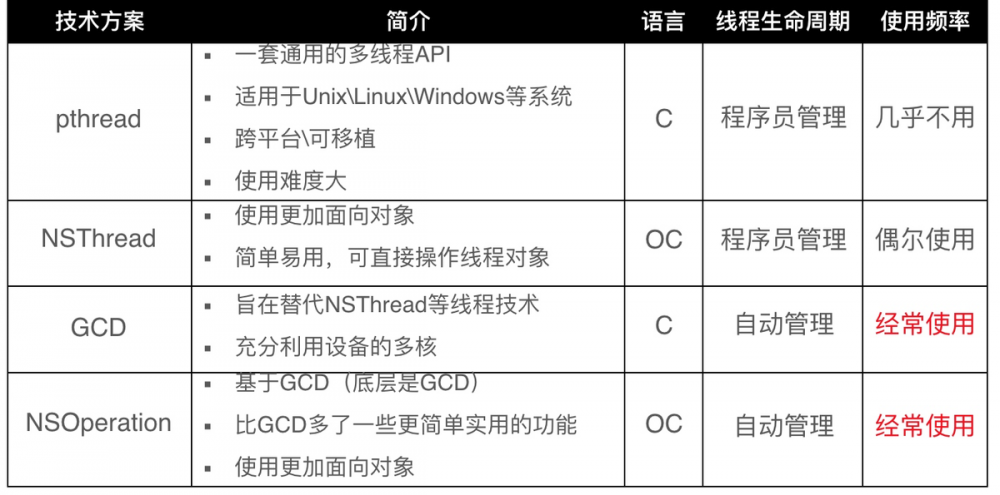
【iOS】架构师之路~底层原理三 : (多线程、内存管理)
pthread / NSThread /GCD /NSOperation 复制代码
14.2GCD的常用函数
GCD中有2个用来执行任务的函数 用同步的方式执行任务 dispatch_sync(dispatch_queue_t queue, dispatch_block_t block); queue:队列 block:任务 用异步的方式执行任务 dispatch_async(dispatch_queue_t queue, dispatch_block_t block); GCD源码:https://github.com/apple/swift-corelibs-libdispatch 复制代码
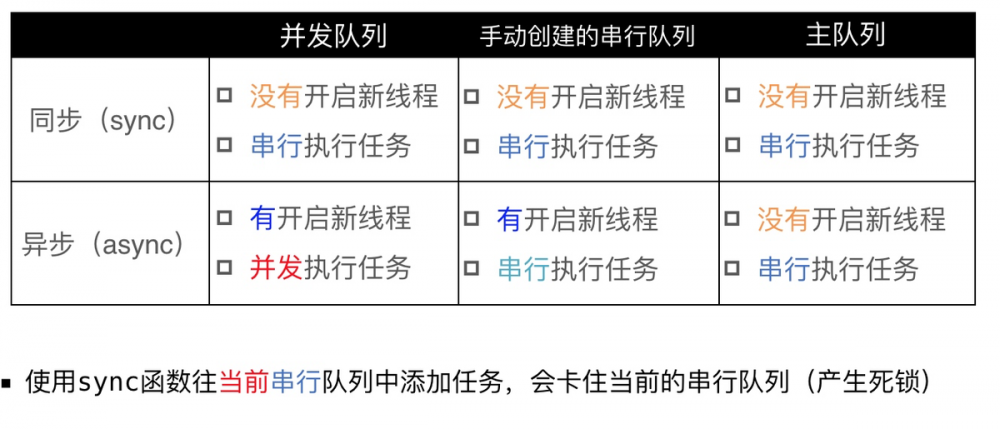
14.3 GCD的队列
GCD的队列可以分为2大类型 并发队列(Concurrent Dispatch Queue) 可以让多个任务并发(同时)执行(自动开启多个线程同时执行任务) 并发功能只有在异步(dispatch_async)函数下才有效 串行队列(Serial Dispatch Queue) 让任务一个接着一个地执行(一个任务执行完毕后,再执行下一个任务) 复制代码
14.4 容易混淆的术语
有4个术语比较容易混淆:同步、异步、并发、串行 同步和异步主要影响:能不能开启新的线程 同步:在当前线程中执行任务,不具备开启新线程的能力 异步:在新的线程中执行任务,具备开启新线程的能力 并发和串行主要影响:任务的执行方式 并发:多个任务并发(同时)执行 串行:一个任务执行完毕后,再执行下一个任务 复制代码
14.5 各种队列的执行效果
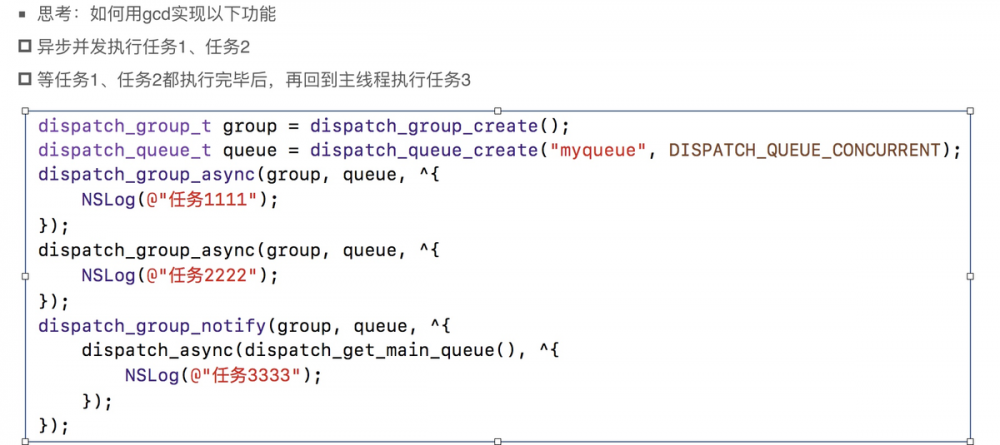
14.6 GCD队列组的使用
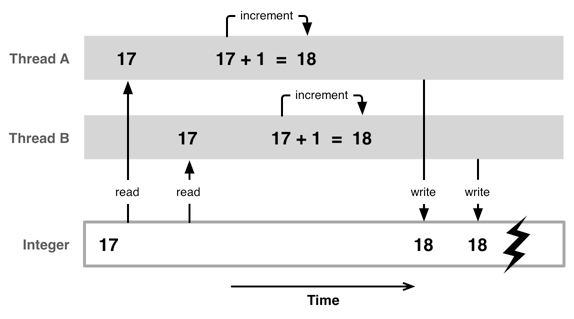
14.7 多线程的安全隐患
资源共享 1块资源可能会被多个线程共享,也就是多个线程可能会访问同一块资源 比如多个线程访问同一个对象、同一个变量、同一个文件 当多个线程访问同一块资源时,很容易引发数据错乱和数据安全问题 复制代码
14.8 多线程安全隐患的解决方案
14.9 iOS中的线程同步方案 线程安全.线程锁
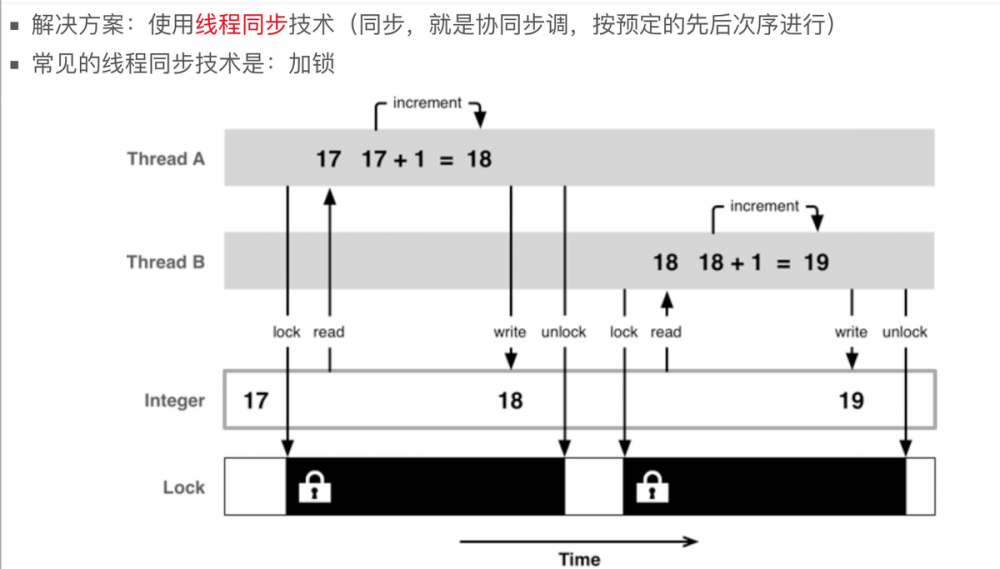
解决方案: 使用线程同步技术(同步,就是协同步调,按预定的先后次序进行) 常见线程同步技术: 加锁
OSSpinLock os_unfair_lock pthread_mutex dispatch_semaphore dispatch_queue(DISPATCH_QUEUE_SERIAL) NSLock NSRecursiveLock NSCondition NSConditionLock @synchronized 复制代码
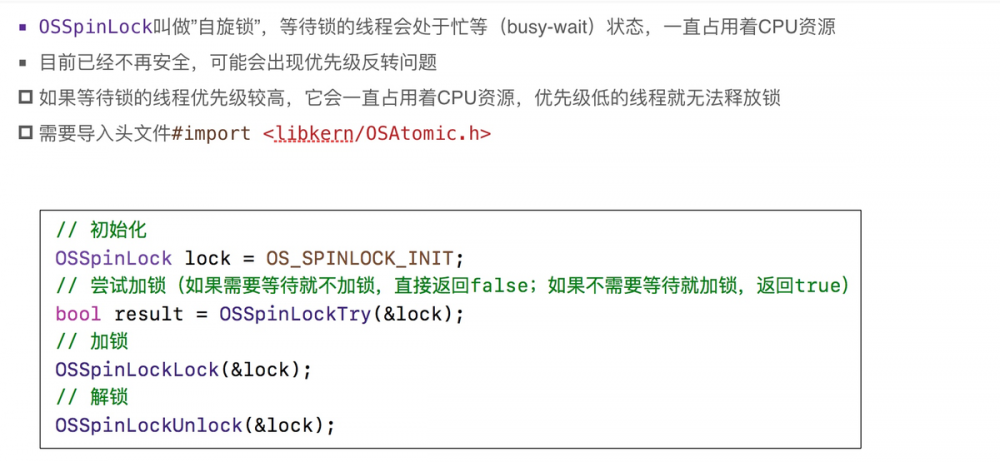
14.10 OSSpinLock (自旋锁) 不安全
14.11 OSUnfairLock (互斥锁) 运行效率最高

14.12 pthread_mutex
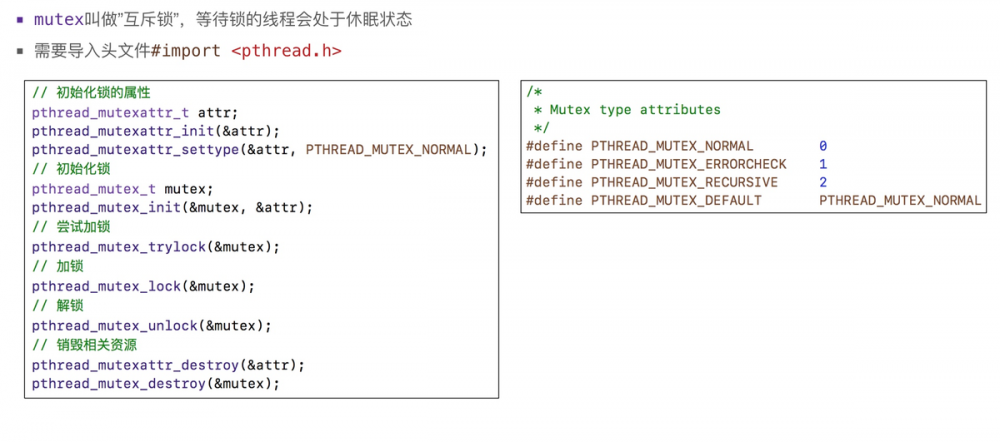
mutex 互斥锁,等待锁的线程会处于休眠状态
14.13 NSLock、NSRecursiveLock

14.14 NSCondition

14.15 dispatch_queue (SerialQueue)
使用GCD串行队列,实现同步 复制代码

14.16 dispatch_semaphore (信号量) 可以用于控制最大并发数量
semaphore叫做”信号量” 信号量的初始值,可以用来控制线程并发访问的最大数量 信号量的初始值为1,代表同时只允许1条线程访问资源,保证线程同步 复制代码

14.17 @synchronized (互斥锁)
@synchronized是对mutex递归锁的封装 源码查看:objc4中的objc-sync.mm文件 @synchronized(obj)内部会生成obj对应的递归锁,然后进行加锁、解锁操作 复制代码
14.18 iOS线程同步方案性能比较

os_unfair_lock ios10 开始 OSSpanLock ios10 废弃 dispatch_semaphore dispatch_mutex dispatch_queue 串行 NSLock 对 mutex 封装 @synchronized 最差 复制代码
14.19 自旋锁、互斥锁比较
什么情况使用自旋锁比较划算? 预计线程等待锁的时间很短 加锁的代码(临界区)经常被调用,但竞争情况很少发生 CPU资源不紧张 多核处理器 什么情况使用互斥锁比较划算? 预计线程等待锁的时间较长 单核处理器 临界区有IO操作 临界区代码复杂或者循环量大 临界区竞争非常激烈 复制代码
14.20 Atomic 和 Noatomic
atomic用于保证属性setter、getter的原子性操作,相当于在getter和setter内部加了线程同步的锁 可以参考源码objc4的objc-accessors.mm 它并不能保证使用属性的过程是线程安全的 复制代码
14.21 多线程 读写线程安全方案
思考如何实现以下场景 同一时间,只能有1个线程进行写的操作 同一时间,允许有多个线程进行读的操作 同一时间,不允许既有写的操作,又有读的操作 上面的场景就是典型的“多读单写”,经常用于文件等数据的读写操作,iOS中的实现方案有 pthread_rwlock:读写锁 dispatch_barrier_async:异步栅栏调用 复制代码
14.22 pthread_rwlock

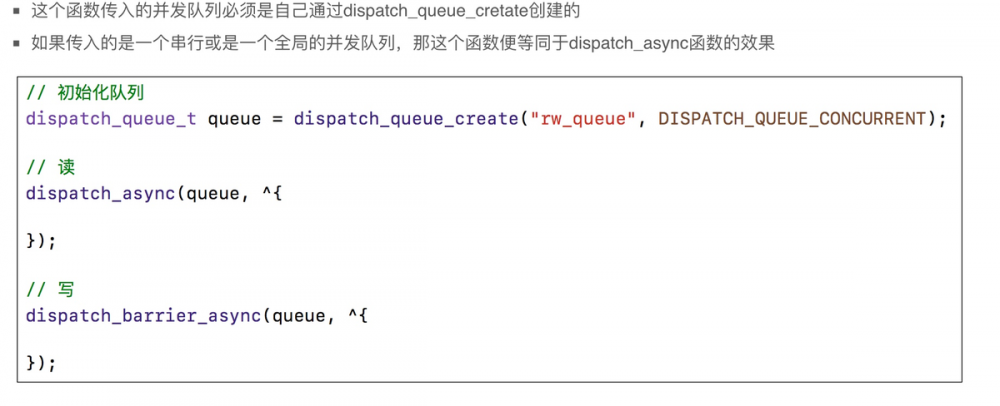
14.23 dispatch_barrier_async
十五. 内存管理
15.1 CADisplayLink、NSTimer使用注意
CADisplayLink 保证调用频率和刷帧频率一直,60FPS, 不用设置时间间隔,每秒钟60次
可以使用 proxy 代理解决循环引用
CADisplayLink、NSTimer会对target产生强引用,如果target又对它们产生强引用,那么就会引发循环引用
复制代码
解决方案1.使用block

解决方案2.使用代理对象(NSProxy)
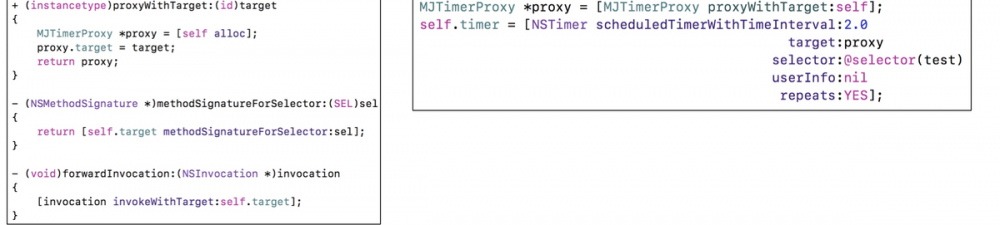
15.2 NSProxy 也属于基类
代理,用于解决循环引用,,用于消息转发,不会在父类查找方法 NSObject 和 NSProxy 区别 复制代码
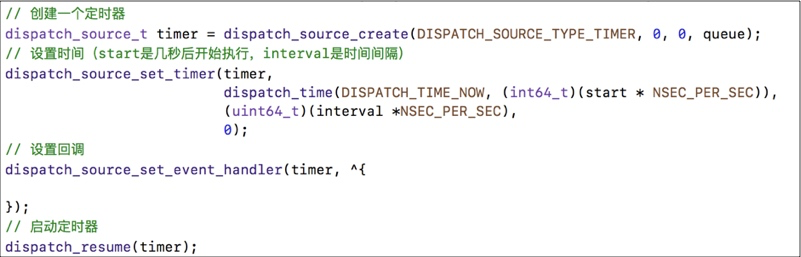
15.3 GCD定时器
NSTimer依赖于RunLoop,如果RunLoop的任务过于繁重,可能会导致NSTimer不准时 而GCD的定时器会更加准时,GCD定时器,不依赖 Runloop ,会很准时,依赖内核 复制代码
15.4 iOS 程序的内存布局
低地址-> 高地址 保留->代码段->数据段(字符串常量,已初始化全局数据,未初始化数据)>堆->栈内存-> 内核区域 代码段: 编译之后的代码 数据段: 字符串常量,已经初始化的全局变量,或者静态变量,未初始化的全局变量,静态变量 堆 (低>高) 通过 alloc malloc calloc 动态分配的内存 栈 (高地址 从 低地址) 函数调用开销() 复制代码

15.5 Tagged Pointer
从64bit开始,iOS引入了Tagged Pointer技术,用于优化NSNumber、NSDate、NSString等小对象的存储 在没有使用Tagged Pointer之前, NSNumber等对象需要动态分配内存、维护引用计数等,NSNumber指针存储的是堆中NSNumber对象的地址值 使用Tagged Pointer之后,NSNumber指针里面存储的数据变成了:Tag + Data,也就是将数据直接存储在了指针中 当指针不够存储数据时,才会使用动态分配内存的方式来存储数据 objc_msgSend能识别Tagged Pointer,比如NSNumber的intValue方法,直接从指针提取数据,节省了以前的调用开销 如何判断一个指针是否为Tagged Pointer? iOS平台,最高有效位是1(第64bit) Mac平台,最低有效位是1 复制代码
判断是否为Tagged Pointer

15.6 OC对象的内存管理
在iOS中,使用引用计数来管理OC对象的内存 一个新创建的OC对象引用计数默认是1,当引用计数减为0,OC对象就会销毁,释放其占用的内存空间 调用retain会让OC对象的引用计数+1,调用release会让OC对象的引用计数-1 内存管理的经验总结 当调用alloc、new、copy、mutableCopy方法返回了一个对象,在不需要这个对象时,要调用release或者autorelease来释放它 想拥有某个对象,就让它的引用计数+1;不想再拥有某个对象,就让它的引用计数-1 可以通过以下私有函数来查看自动释放池的情况 extern void _objc_autoreleasePoolPrint(void); 复制代码
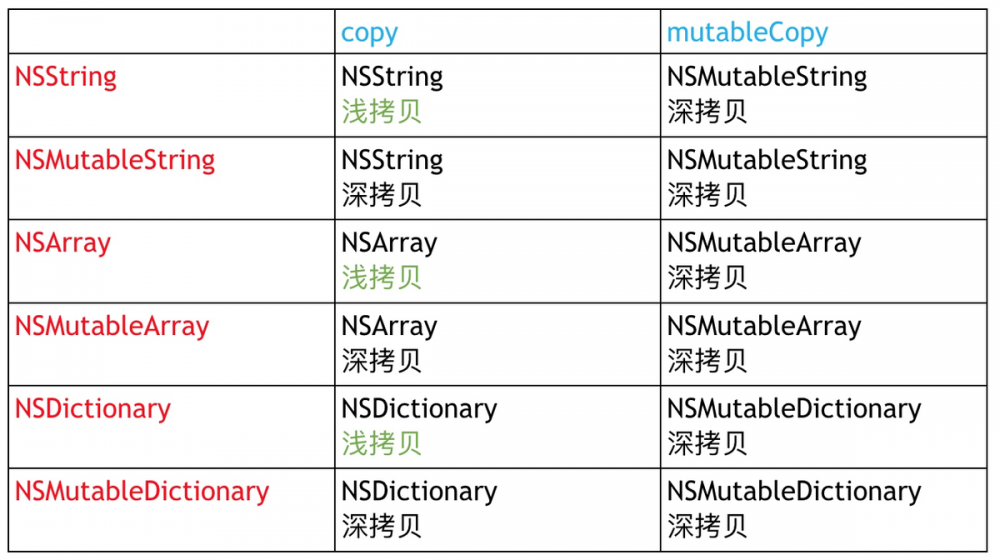
15.7 copy和mutableCopy
15.8 引用计数器的存储 retaincount

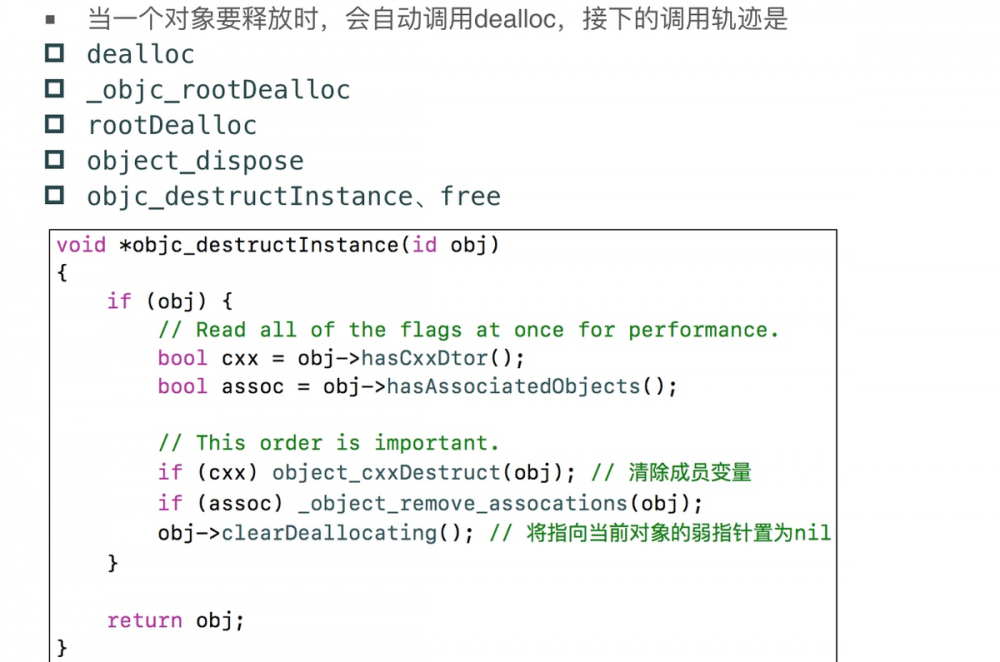
15.9 dealloc
15.10 autoreleasePool 自动释放池
自动释放池的主要底层数据结构是:__AtAutoreleasePool、AutoreleasePoolPage 调用了autorelease的对象最终都是通过AutoreleasePoolPage对象来管理的 源码分析 -clang重写@autoreleasepool -objc4源码:NSObject.mm 复制代码
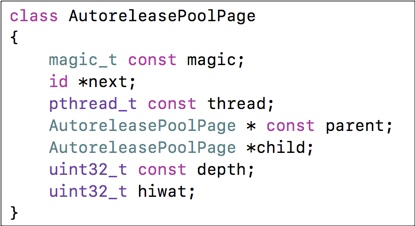
15.11 AutoreleasePoolPage的结构
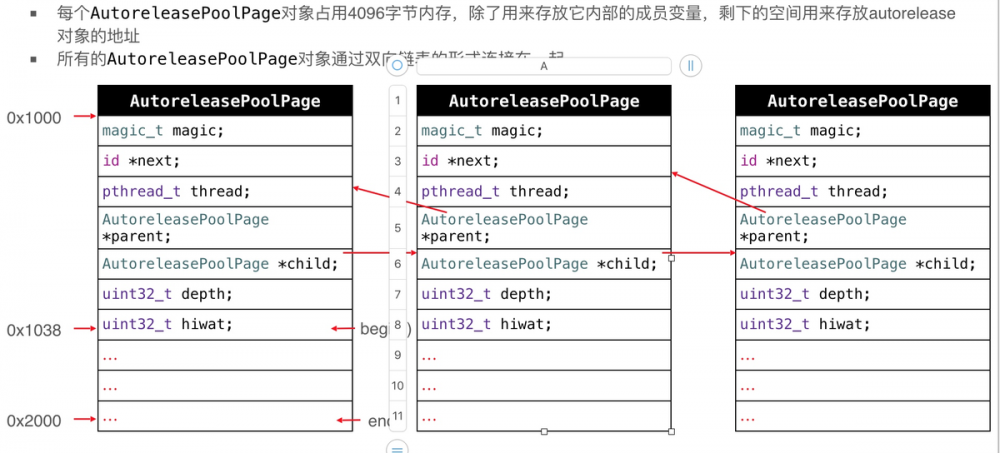
调用push方法会将一个POOL_BOUNDARY入栈,并且返回其存放的内存地址 调用pop方法时传入一个POOL_BOUNDARY的内存地址,会从最后一个入栈的对象开始发送release消息,直到遇到这个POOL_BOUNDARY id *next指向了下一个能存放autorelease对象地址的区域 复制代码
15.12 runloop 和 autoreleasePool
iOS在主线程的Runloop中注册了2个Observer
-第1个Observer监听了kCFRunLoopEntry事件,会调用objc_autoreleasePoolPush()
-第2个Observer
监听了kCFRunLoopBeforeWaiting事件,会调用objc_autoreleasePoolPop()、objc_autoreleasePoolPush()
监听了kCFRunLoopBeforeExit事件,会调用objc_autoreleasePoolPop()
复制代码
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

