从零开始利用JPA与SHARDING-JDBC动态划分月表
数据量按照分片键(入库时间)进入对应的月表,查询时根据分片键的值查询指定表;但是每次查询都必须带上分片键,这就不是很友好,所以另外后面也有说明在没有指定分片键时如何查询最近的两个月。
前期准备
建表语句
-- 逻辑表,每个月表都根据逻辑表生成 CREATE TABLE `EXAMPLE` ( `ID` bigint(36) NOT NULL AUTO_INCREMENT, `NAME` varchar(255) NOT NULL, `CREATED` datetime(3) DEFAULT NULL, `UPDATED` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- 月表 CREATE TABLE `EXAMPLE_201909` ( `ID` bigint(36) NOT NULL AUTO_INCREMENT, `NAME` varchar(255) NOT NULL, `CREATED` datetime(3) DEFAULT NULL, `UPDATED` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; CREATE TABLE `EXAMPLE_201910` ( `ID` bigint(36) NOT NULL AUTO_INCREMENT, `NAME` varchar(255) NOT NULL, `CREATED` datetime(3) DEFAULT NULL, `UPDATED` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 复制代码
实体类
@Entity
@Data
@Table(name = "EXAMPLE")
public class Example implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private String id;
@Column(name = "NAME")
private String name;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS", timezone = "GMT+8")
@Column(name = "CREATED")
private Date created;
@Column(name = "UPDATED", insertable = false, updatable = false)
private Date updated;
}
复制代码
repo
import java.util.Date;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import com.test.sharding.entity.Example;
public interface ExampleRepo extends JpaRepository<Example, Long>, JpaSpecificationExecutor<Example> {
List<Example> findByCreatedBetween(Date start, Date end);
}
复制代码
Maven依赖
经过测试,支持springboot 2.0.X+与1.5.X+。
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>4.6.7</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.20</version> </dependency> 复制代码
分片算法实现
由于选择的分片策略是 StandardShardingStrategy (在后面的配置文件中会配置),所以需要试下下面两个分片算法:
- 精确分片算法
import java.util.Collection;
import java.util.Date;
import cn.hutool.core.date.DateUtil;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Date> {
// 可以优化为全局变量
private static String yearAndMonth = "yyyyMM";
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {
StringBuffer tableName = new StringBuffer();
tableName.append(shardingValue.getLogicTableName()).append("_")
.append(DateUtil.format(shardingValue.getValue(), yearAndMonth));
return tableName.toString();
}
}
复制代码
- 范围分片算法
public class TimeRangeShardingAlgorithm implements RangeShardingAlgorithm<Date> {
private static String yearAndMonth = "yyyyMM";
/**
* 只查询最近两个月的数据
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> shardingValue) {
Collection<String> result = new LinkedHashSet<String>();
Range<Date> range = shardingValue.getValueRange();
// 获取范围
String end = DateUtil.format(range.lowerEndpoint(), yearAndMonth);
// 获取前一个月
String start = DateUtil.format(range.upperEndpoint(), yearAndMonth);
result.add(shardingValue.getLogicTableName() + "_" + start);
if (!end.equals(start)) {
result.add(shardingValue.getLogicTableName() + "_" + end);
}
return result;
}
}
复制代码
application.yml配置
spring:
datasource: # 可有可无,在配置了sharding之后,默认只会有sharding数据源生效
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/ddssss
username: root
password: ppppppp
tomcat:
initial-size: 5
driver-class-name: com.mysql.jdbc.Driver
jpa:
database: mysql
sharding:
jdbc:
datasource:
names: month-0 # 数据源名称
month-0:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ddssss
username: root
password: ppppppp
type: com.alibaba.druid.pool.DruidDataSource
config:
sharding:
tables:
month: # 表名
key-generator-column-name: id # 主键名称
table-strategy:
standard:
sharding-column: ccreated # 分片键
precise-algorithm-class-name: com.example.sharding.config.MyPreciseShardingAlgorithm # 实现类的完全限定类名
range-algorithm-class-name: com.example.sharding.config.MyRangeShardingAlgorithm # 实现类的完全限定类名
props:
sql.show: true # 是否显示SQL ,默认为false
复制代码
测试
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import javax.persistence.criteria.Predicate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.stereotype.Component;
import com.alibaba.fastjson.JSONObject;
import com.test.sharding.entity.Example;
import com.test.sharding.repository.ExampleRepo;
import cn.hutool.core.date.DateUtil;
import lombok.extern.slf4j.Slf4j;
@Component
@Slf4j
public class StartRunner implements CommandLineRunner {
@Autowired
ExampleRepo exampleRepo;
@Override
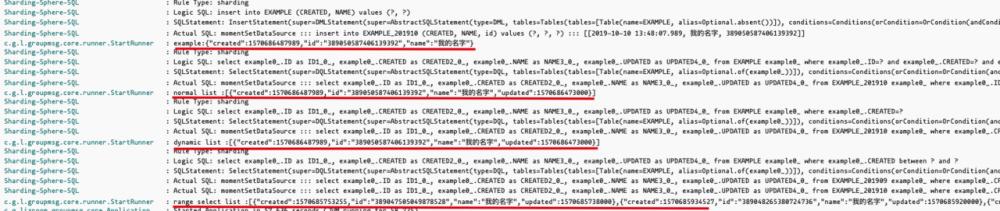
public void run(String... args) throws Exception {
log.info("==============init===================");
Example example = new Example();
example.setName("我的名字");
example.setCreated(new Date());
exampleRepo.save(example);
log.info("example:{}", JSONObject.toJSONString(example));
// 普通条件查询
List<Example> list = exampleRepo.findAll(org.springframework.data.domain.Example.<Example>of(example));
log.info("normal list :{}", JSONObject.toJSONString(list));
// 动态条件查询
Example condtion = new Example();
condtion.setCreated(example.getCreated());
list = exampleRepo.findAll(getIdSpecification(condtion));
log.info("dynamic list :{}", JSONObject.toJSONString(list));
// 范围查询
Date end = new Date();
list = exampleRepo.findByCreatedBetween(DateUtil.lastMonth()
.toJdkDate(), end);
log.info("range select list :{}", JSONObject.toJSONString(list));
}
protected Specification<Example> getIdSpecification(final Example condtion) {
return (root, query, cb) -> {
List<Predicate> list = new ArrayList<>();
list.add(cb.equal(root.<Date>get("created"), condtion.getCreated()));
Predicate[] predicates = new Predicate[list.size()];
query.where(list.toArray(predicates));
return query.getRestriction();
};
}
}
复制代码
启动后就会看到日志如下:
数据库:
-
表:

-
数据

后记
虽然这样实现了基于时间的动态划分月表查询与插入,但在实际使用中却还有着许多小问题,比如:save方法在指定了主键的情况下依然会进行 INSERT 而不是 UPDATE 、查询时必须带上分片键、还需要手动创建后续的月表。
针对这三个问题,需要做进一步的优化。
问题产生的原因
- 为什么save方法在指定了主键的情况下依然会进行
INSERT而不是UPDATE
JPA的SAVE在指定的主键不为空时会先去表里查询该主键是否存在,但是这样查询的条件是只有主键而没有分片键的,Sharding-JDBC的策略是在没有指定分片键时会去查询所有的分片表。
但是这里就是有一个误区,Sharding-JDBC主动查询所有的分片表指的是固定分片的情况。比如这里有另外一张表,根据ID奇偶分片,分出来有两张表。那么所有的数据都会在者两张表中,我们在配置的时候也是直接配置者两张表。
对于我们现在的需求来说就不适用,因为我们的分表规则是根据时间来的,每年每月都有一张新表,所以对于没有指定分片键值得查询,Sharding-JDBC默认值查询了逻辑表。此时返回空,JPA就会认为该主键没有数据,所以对应的SQL是 INSERT 而不是 UPDATE 。
- 为什么查询时必须带上分片键
理由和上述是一样的,Sharding-JDBC在没有指定分片键时值查询了逻辑表。
- 还需要手动创建后续的月表
首先,每个月都需要创建对应的月表这个是肯定的,当然也可以直接一次性县创建几年的表,但我感觉没意义,这种重复的事情应该让程序来做,定时创建月表。
解决方案
针对问题1与问题2,我直接重写Sharding-JDBC的路由规则,可以完美解决。
- 重写路由规则
需要修改类 io.shardingsphere.core.routing.type.standard.StandardRoutingEngine 的 routeTables 方法,并且声明了一个静态变量记录需要分表的逻辑表,具体代码如下:
// 时间格式化
private static String yearAndMonth = "yyyyMM";
// 保存需要分表的逻辑表
private static final Set<String> needRoutTables = new HashSet<>(
Lists.newArrayList("EXAMPLE"));
复制代码
private Collection<DataNode> routeTables(final TableRule tableRule, final String routedDataSource,
final List<ShardingValue> tableShardingValues) {
Collection<String> availableTargetTables = tableRule.getActualTableNames(routedDataSource);
// 路由表,根据分表算法得到,动态分表时如果条件里没有分片键则返回逻辑表,本文是:EXAMPLE
Collection<String> routedTables = new LinkedHashSet<>(tableShardingValues.isEmpty() ? availableTargetTables
: shardingRule.getTableShardingStrategy(tableRule)
.doSharding(availableTargetTables, tableShardingValues));
// 如果得到的路由表只有一个,因为大于2的情况都应该是制定了分片键的(分表是不建议联表查询的)
if (routedTables.size() <= 1) {
// 得到逻辑表名
String routeTable = routedTables.iterator()
.next();
// 判断是否需要分表,true代表需要分表
if (needRoutTables.contains(routeTable)) {
// 移除逻辑表
routedTables.remove(routeTable);
Date now = new Date();
// 月份后缀,默认最近两个月
String nowSuffix = DateUtil.format(now, yearAndMonth);
String lastMonthSuffix = DateUtil.format(DateUtil.lastMonth(), yearAndMonth);
routedTables.add(routeTable + "_" + nowSuffix);
routedTables.add(routeTable + "_" + lastMonthSuffix);
}
}
Preconditions.checkState(!routedTables.isEmpty(), "no table route info");
Collection<DataNode> result = new LinkedList<>();
for (String each : routedTables) {
result.add(new DataNode(routedDataSource, each));
}
return result;
}
复制代码
针对问题3,利用程序定时建表,我这里没有选择通用的建表语句:
-- ****** 日期,在程序里动态替换 CREATE TABLE `EXAMPLE_******` ( `ID` bigint(36) NOT NULL AUTO_INCREMENT, `NAME` varchar(255) NOT NULL, `CREATED` datetime(3) DEFAULT NULL, `UPDATED` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 复制代码
主要原因有以下两点
- 在一般的项目里的表字段一般都不会这么少,建表语句会很长
- 而且后期的维护也不好,对于表任何改动都需要在程序里也需要维护
我选择了根据模板来创建表,SQL如下:
-- ****** 日期,在程序里动态替换 CREATE TABLE IF NOT EXISTS `EXAMPLE_******` LIKE `EXAMPLE` 复制代码
这样的好处就是建表语句相对精简、不需要关心表结构了,一切从模板新建月表。但是这也引出了一个新的问题,Sharding-JDBC不支持这样的语法。所以又需要修改源代码重写一下拦截规则。具体就是类 io.shardingsphere.core.parsing.parser.sql.ddl.create.table.AbstractCreateTableParser 的 parse 方法:
public final DDLStatement parse() {
lexerEngine.skipAll(getSkippedKeywordsBetweenCreateIndexAndKeyword());
lexerEngine.skipAll(getSkippedKeywordsBetweenCreateAndKeyword());
CreateTableStatement result = new CreateTableStatement();
if (lexerEngine.skipIfEqual(DefaultKeyword.TABLE)) {
lexerEngine.skipAll(getSkippedKeywordsBetweenCreateTableAndTableName());
} else {
throw new SQLParsingException("Can't support other CREATE grammar unless CREATE TABLE.");
}
tableReferencesClauseParser.parseSingleTableWithoutAlias(result);
// 注释掉这个命令
// lexerEngine.accept(Symbol.LEFT_PAREN);
do {
parseCreateDefinition(result);
} while (lexerEngine.skipIfEqual(Symbol.COMMA));
// 注释掉这个命令
// lexerEngine.accept(Symbol.RIGHT_PAREN);
return result;
}
复制代码
总结
到此一个完整的动态划分月表就已经完成了,同时也掌握了Sharding-JDBC的一些基础知识和操作。
正文到此结束
- 本文标签: tk maven 总结 cat Word 需求 id root key junit js src UI bean App ArrayList spring GMT db final 数据库 http 代码 Collection web json zab https lib 配置 Persistence CTO LinkedList mysql tag node REST find DDL API IO Select Statement apache 2019 ip example sql JPA 注释 sharding tab list HashSet tar core IDE executor DOM JDBC update rand tomcat dataSource Datanode ACE 时间 springboot 测试 value druid entity 数据 ORM parse equals java
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

