Spark On Hbase的官方jar包编译与使用
Spark读写HBase没有专门的 Maven 依赖包可用,HBase也没提供现成的HBase Spark Connector,但hbase官网指向一个项目可从源码编译。这样就有类似spark-kafka,spark-hive的spark-hbase依赖了。
编译 hbase-spark 源码获取jar包
源码地址
Apache Hbase维护的项目,从此处下载源码压缩包: Hbase Connectors-Spark源码
Apache HBase™ Spark Connector
- Scala and Spark Versions
To generate an artifact for a different spark version and/or scala version, pass command-line options as follows (changing version numbers appropriately):
$ mvn -Dspark.version=2.3.1 -Dscala.version=2.11.8 -Dscala.binary.version=2.11 clean install 复制代码
准备编译出Spark2.3.1&Scala2.11.8的hbase-spark依赖:
unzip hbase-connectors-master.zip cd hbase-connectors-master/ mvn -Dspark.version=2.3.1 -Dscala.version=2.11.8 -Dscala.binary.version=2.11 clean install 复制代码
编译报错
- maven版本过低,安装一下maven3.5.4,配置环境变量即可。
- TestJavaHBaseContext Failed,编译时添加 -DskipTests即可
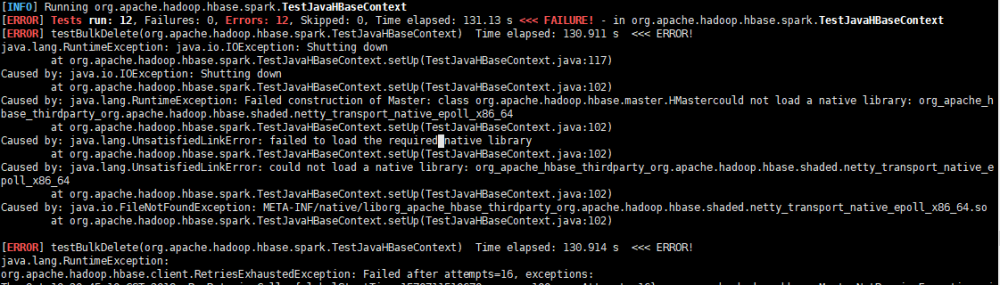
mvn -Dspark.version=2.3.1 -Dscala.version=2.11.8 -Dscala.binary.version=2.11 -DskipTests clean install
编译成功
位置:~/hbase-connectors-master/spark/hbase-spark/target
,现在可以在项目中使用了。
使用hbase-spark-1.0.1-SNAPSHOT.jar
使用HBaseContext写数据
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
//从编译的hbase-spark-1.0.1-SNAPSHOT.jar中引入
import org.apache.hadoop.hbase.spark.HBaseContext
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import java.util.UUID
object SparkWithHBase {
def main(args: Array[String]): Unit = {
//Spark统一入口
val spark = SparkSession.builder()
.appName("Spark JDBC Test")
.master("local")
.getOrCreate()
//列族名称
val SRC_FAMILYCOLUMN = "info"
//Hbase配置
val config = HBaseConfiguration.create()
config.set("hbase.zookeeper.quorum", "manager.bigdata")
config.set("hbase.zookeeper.property.clientPort", "2181")
//Hbase上下文,是API的核心
val hbaseContext = new HBaseContext(spark.sparkContext, config)
//读取数据源,封装成<RowKey,Values>这种格式
val rdd: RDD[(String, Array[(String, String)])] = spark.read.csv("hdfs://manager.bigdata:8020/traffic.txt")
.rdd
.map(r => {
(UUID.randomUUID().toString, Array((r.getString(0), "c1"), (r.getString(1), "c2"), (r.getString(2), "c3")))
})
//使用批量put方法写入数据
hbaseContext.bulkPut[(String, Array[(String, String)])](rdd,
TableName.valueOf("spark_hbase_bulk_put"),
row => {
val put = new Put(Bytes.toBytes(row._1))
row._2.foreach(putValue => put.addColumn(
Bytes.toBytes(SRC_FAMILYCOLUMN),
Bytes.toBytes(putValue._2),
Bytes.toBytes(putValue._1)))
put
})
}
}
复制代码
经查询,数据成功写入HBase。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

