Linker 2.6 版本正式支持分布式跟踪功能

作者 | Alex Leong
作者 | 核子可乐
我们很高兴地宣布 Linkerd 2.6 版本将正式迎来分布式跟踪支持功能!这意味着 Linkerd 数据平面现在可以进行范围跟踪,允许用户查看各项请求在 Linkerd 代理中花费的确切时间。相信很多朋友都清楚,在实践场景中实现分布式跟踪往往非常困难,因此在本文中,我们将结合参考架构,就如何通过 Linkerd 使用分布式跟踪功能为您提供最佳实践与建议。
跟踪无疑是分布式系统性能调试中的一大重要工具,能够帮助我们准确判断系统中的性能瓶颈,以及各个组件的具体延迟成本。总而言之,分布式跟踪做出了重要的运营承诺;但根据我们的经验,在实际场面中践行这些承诺往往相当困难。
首先,分布式跟踪生态系统往往非常复杂,其中包含一系列令人眼花缭乱的项目,例如 Zipkin、Jaeger、OpenTracing、OpenCensus、OpenTelemetry 以及其他种种方案选项。各个项目之间还存在一定的功能交集,而且不同项目间的互操作效果也有所区别。可怕的是,即使是用于衡量这些互操作效果的指标,也足以令人感到头晕目眩。
更糟糕的是,service mesh 的介入进一步提高了决策的复杂程度。分布式跟踪与 service mesh 之间存在着功能交集,例如绘制应用程序拓扑结构的能力等。在另一方面,service mesh 中的大多数功能无需变更代码即可实现,但分布式跟踪却往往会给代码内容造成影响。
考虑到我们在 Linkerd 社区当中观察到的各类实际问题,接下来的工作就非常明确了:我们不仅要在 Linkerd 2.6 版本当中“添加分布式跟踪”并保证其易用性,同时还要帮助大家了解如何在自己的实际 Linkerd 应用程序当中享受到这项功能带来的便利。
Linkerd 2.6 中的分布式跟踪
首先,让我们先聊聊 Linkerd 中关于“分布式跟踪支持”的确切定义。说起来非常简单:当 Linkerd 数据平面代理在一条代理转发的 HTTP 请求中发现 b3 格式的跟踪标头时(后文会提到 Linkerd 中为什么会出现这种特殊的请求格式),Linkerd 就会为该请求发出跟踪范围。该范围包含请求在 Linkerd 代理中所花费时间的确切信息,同时也将包含后续出现的其他一些信息。
就这么简单。大家可以看到,Linkerd 在分布式跟踪中的作用相当清晰易懂。但为了让 Linkerd 的这一功能实际起效,最困难的其实在于满足其他几个配合性条件。
还有啥条件?要使用 Linkerd 的全新分布式跟踪功能,大家需要在系统中部署以下几个组件:
-
一个入口层,用于立足特定请求启动跟踪功能。
-
一套应用程序客户端库。(您的应用程序代码必须能够传播跟踪标头,在理想情况下最好还能发送自己的跨度信息。)
-
跟踪收集器,用于收集跨度数据并将其转换为跟踪操作。
-
跟踪后端,用于存储跟踪数据并允许用户进行查看 / 查询。
演示部分
下面,让我们看看参考架构中的分布式跟踪是如何工作的。接下来,我们会具体介绍每一个组件,并阐述如何在您自己的应用程序当中使用这些组件。首先,请确保您的 Linkerd 2.6 CLI 正常可用,且已经在集群上安装了 Linkerd 2.6 版本。如果尚未安装,请首先安装或者升级。
$ linkerd version Client version: stable-2.6 Server version: stable-2.6
开始克隆参考架构库:
git clone git@github.com:adleong/emojivoto.git && /
cd emojivoto
接下来,我们需要安装 Jaeger 与 OpenCensus 收集器。这些组件对于 Linkerd 来说非常重要,请确保它们能够通过安全连接从 Linkerd 代理处接收跨度。
linkerd inject tracing.yml | kubectl apply -f -
最后,我们需要安装 Nginx 入口控制器以及 Emojivoto 应用程序本体。由于我们利用 Linkerd 注入这些组件,因此能够在跟踪结果中看到 Linkerd 代理自身。
linkerd inject emojivoto.yml | kubectl apply -f - && /
linkerd inject ingress.yml | kubectl apply -f -
在全部准备就绪之后,我们可以使用 Jaeger 仪表板对系统进行整体跟踪。
kubectl -n tracing port-forward deploy/jaeger 16686 &; /
open http://localhost:16686
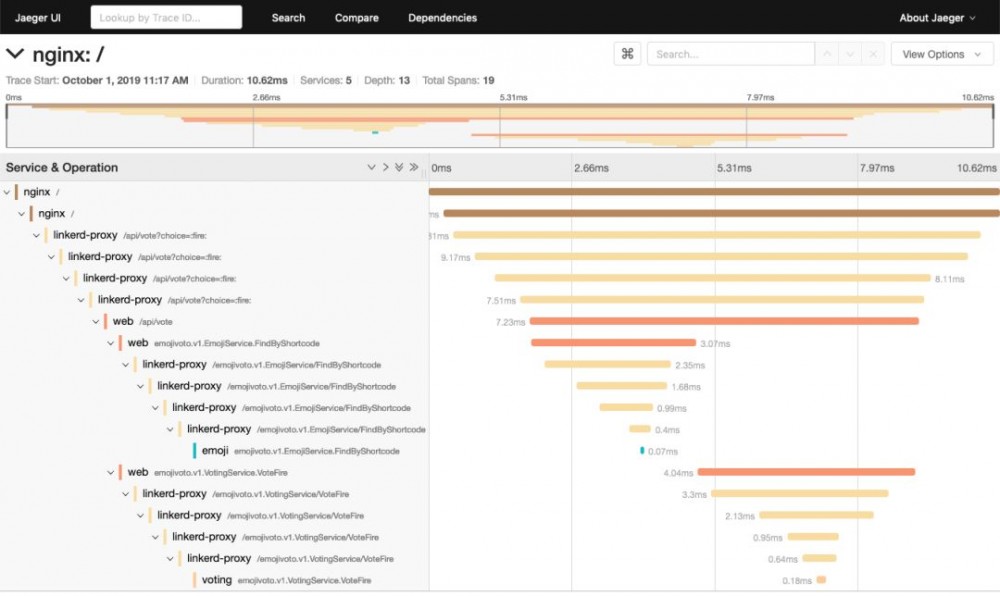
Linkerd 分布式跟踪参考架构
这套参考架构绝不是实现应用程序分布式跟踪的唯一方法,甚至不能算是最佳实践方法,毕竟具体取决于您的应用程序情况以及实际需求。但这确实是个不错的上手起点,而且无论是否配合 service mesh 都能提供良好的运行效果。
这套参考架构共包含四大组件,分别为:作为入口的 Nginx,作为客户端库的 OpenCensus,作为跟踪收集器的 OpenCensus 以及作为后端的 Jaeger。我们将在后文中对各组件做出具体阐述。当然,这些组件也是可以替换的,我们将在对应部分介绍可以选择不同的替代性选项。
入口: Nginx
入口对于分布式跟踪而言特别重要,因为其负责为每个跟踪创建根跨度,并确定是否应该对该跟踪进行采样。由入口做出全部采样决策,能够确保我们对整个跟踪流程进行采样,或者完全不采样,同时避免产生“部分跟踪”问题。
分布式跟踪系统完全依靠服务来传递关于当前跟踪活动的元数据,这些元数据涵盖当前跟踪接收到的请求及其发出的请求。我们将这些元数据称为跟踪上下文,且通常将其编码在一个或者多个请求标头当中。跟踪上下文标头的格式多种多样,但我们希望生态系统最终能够逐步收敛为开放标准,例如 W3C tracecontext。在今天的示例中,我们只使用 b3 格式。作为最早的使用格式之一,b3 格式支持范围最广,特别是在 Nginx 这类入口中拥有良好的匹配效果。
这套参考架构包含一个简单的 Nginx config,该配置会对 50% 的跟踪进行采样并将跟踪数据发送至收集器(仅代表和 Zipkin 协议)。当然,对于本示例而言,大家可以随意选择入口控制器来替换 Nginx 完成以下功能:
-
支持概率抽样。
-
以 b3 格式编码跟踪上下文。
-
在 OpenCensus 收集器支持的协议中扩展跨度。
客户端库: OpenCensus
虽然服务可以通过手动方式对传播标头进行传播跟踪,但直接使用具备以下三项功能的库能够极大简化操作流程:
-
将跟踪上下文从传入的请求标头传播至传出的请求标头。
-
修改跟踪上下文(即开始一个新跨度)。
-
将此数据传输至跟踪收集器。
我们建议大家使用 OpenCensus,并使用以下配置:
-
b3 传播 (默认配置)
-
OpenCensus 代理导出器
OpenCensus 代理导出器将通过 gRPC API 把跟踪数据导出至 OpenCensus 收集器。具体 OpenCensus 配置方法因编程语言而异,这里不再一一赘述。另外,大家也可以通过本示例中的 Emojivoto 查看 Go 语言的端到端展示。
大家可能会注意到,OpenCensus 项目目前处于维护模式,并计划后续被合并至 OpenTelemetry 项目当中。遗憾的是,目前 OpenTelemetry 尚未公布生产就绪版本,因此当下最好的选择仍然是 OpenCensus。
收集器: OpenCensus
OpenCensus 收集器负责接收来自 OpenCensus 代理导出器的跟踪数据,并可能需要在将数据发送至 Jaeger 之前执行转换与过滤操作。这种首先将 OpenCensus 导出器数据发送至 OpenCensus 收集器的做法,能够为我们提供显著的灵活性优势。这意味着我们可以切换至 OpenCensus 所支持的任意后端,而无需中断应用程序运行。
后端: Jaeger
Jaeger 是目前使用范围最广的跟踪后端之一,其主要优势包括:易于使用,且提供强大的跟踪可视化能力。当然,大家也可以根据喜好改用 OpenCensus 所支持的任何其他后端。
Linkerd
如果您的应用程序已经注入 Linkerd,那么 Linkerd 代理也将参与跟踪,并负责将跟踪数据发送至 OpenCensus 收集器。这不仅丰富了跟踪数据的内容,同时也允许大家准确查看请求在代理及网络上具体花费了多少时间。要实现 Linkerd 介入,您需要:
-
在希望介入跟踪的命名空间或者 pod 规范中,对 config.linkerd.io/trace-collector 注释进行设置。具体设置方法为添加 OpenCensus 收集器服务的地址。在我们的参考架构中,该地址为:oc-collector.tracing:55678。
-
在希望介入跟踪的命名空间或者 pod 规范中,对 config.alpha.linkerd.io/trace-collector-service-account 注释进行设置。具体设置方法为添加该收集器的服务账户名称,从优同确保代理与收集器之间进行安全通信。如果您将收集器作为默认服务账户运行,则可以省略这个步骤。参考架构就采取这种方法,因此直接省略。
-
确保您希望发送跨度的 pod 已经注入有 Linkerd 代理。
-
确保 OpenCensus 收集器已经注入有 Linkerd 代理。
虽然 Linkerd 目前只能主动参与使用 b3 传播格式的跟踪(如之前参考架构部分所述),但 Linkerd 会始终以透明方式转发未知的请求标头,意味着其永远不会干扰到使用其他传播格式的跟踪活动。我们也有计划进一步扩展 Linkerd 的传播格式支持能力,大家敬请期待。
总结
希望我们的这套参考架构能够帮助大家轻松理解分布式跟踪的整个流程与所涉及的具体组件,并掌握如何对自己的应用程序进行检测。虽然这里提出的参考架构并非实现分布式跟踪的唯一方法,但我们希望它能够成为各位用户探索新功能的理想起点。如果您还有任何建议或者疑问,也请随时与我们联系!
原文链接:
https://linkerd.io/2019/10/07/a-guide-to-distributed-tracing-with-linkerd/
活动推荐
如果你想知道 Facebook、LinkedIn、阿里巴巴、百度等公司是如何落地实践 AIOps 的,请关注 QCon 上海 2019,学习到他们的经验可以让大家权衡自己的系统整合落地方案,少走很多弯路。这里还有国内大型互联网公司在监控领域最前沿的产品、技术和理念,帮你平衡日增海量数据与实时精准展现之间的矛盾。大会 报名中倒计时 ,团购更优惠,有任何问题欢迎联系票务小姐姐 Ring:17310043226(微信同号)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

