IoC 之装载 BeanDefinitions 总结
最近时间重新对spring源码进行了解析,以便后续自己能够更好的阅读spring源码,想要一起深入探讨请加我QQ:1051980588
1 ClassPathResource resource = new ClassPathResource("bean.xml");
2 DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
3 XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
4 reader.loadBeanDefinitions(resource);
对spring源码解析上面是最基本的几行代码,接下来我会对这基本代码深入探索,当然有些代码解释是基于其他博客借鉴过来的,如有相同希望见谅
-
ClassPathResource resource = new ClassPathResource("bean.xml");: 根据 Xml 配置文件创建 Resource 资源对象。ClassPathResource 是 Resource 接口的子类,bean.xml文件中的内容是我们定义的 Bean 信息。 -
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();:创建一个 BeanFactory 。DefaultListableBeanFactory 是 BeanFactory 的一个子类,BeanFactory 作为一个接口,其实它本身是不具有独立使用的功能的,而 DefaultListableBeanFactory 则是真正可以独立使用的 IoC 容器,它是整个 Spring IoC 的始祖,在后续会有专门的文章来分析它。 -
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);:创建 XmlBeanDefinitionReader 读取器,用于载入 BeanDefinition 。 -
reader.loadBeanDefinitions(resource);:开始 BeanDefinition 的载入和注册进程,完成后的 BeanDefinition 放置在 IoC 容器中。
1. Resource 定位
Spring 为了解决资源定位的问题,提供了两个接口:Resource、ResourceLoader,其中:
- Resource 接口是 Spring 统一资源的抽象接口
- ResourceLoader 则是 Spring 资源加载的统一抽象。
Resource 资源的定位需要 Resource 和 ResourceLoader 两个接口互相配合,在上面那段代码中 new ClassPathResource("bean.xml") 为我们定义了资源,那么 ResourceLoader 则是在什么时候初始化的呢?看 XmlBeanDefinitionReader 构造方法:
1 // XmlBeanDefinitionReader.java
2 public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) {
3 super(registry);
4 }
我们可以看见 直接调用父类 AbstractBeanDefinitionReader 构造方法,代码如下:
1 // AbstractBeanDefinitionReader.java
2
3 protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
4 Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
5 this.registry = registry;
6 // Determine ResourceLoader to use.
7 if (this.registry instanceof ResourceLoader) {
8 this.resourceLoader = (ResourceLoader) this.registry;
9 } else {
10 this.resourceLoader = new PathMatchingResourcePatternResolver();
11 }
12
13 // Inherit Environment if possible
14 if (this.registry instanceof EnvironmentCapable) {
15 this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
16 } else {
17 this.environment = new StandardEnvironment();
18 }
19 }
核心在于设置 resourceLoader 这段,如果设置了 ResourceLoader 则用设置的,否则使用 PathMatchingResourcePatternResolver ,该类是一个集大成者的 ResourceLoader。
2. BeanDefinition 的载入和解析
reader.loadBeanDefinitions(resource); 代码段,开启 BeanDefinition 的解析过程。如下:
1 // XmlBeanDefinitionReader.java
2 @Override
3 public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
4 return loadBeanDefinitions(new EncodedResource(resource));
5 }
在这个方法会将资源 resource 包装成一个 EncodedResource 实例对象,然后调用 #loadBeanDefinitions(EncodedResource encodedResource) 方法。而将 Resource 封装成 EncodedResource 主要是为了对 Resource 进行编码,保证内容读取的正确性。代码如下:
1 // XmlBeanDefinitionReader.java
2
3 public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
4 // ... 省略一些代码
5 try {
6 // 将资源文件转为 InputStream 的 IO 流
7 InputStream inputStream = encodedResource.getResource().getInputStream();
8 try {
9 // 从 InputStream 中得到 XML 的解析源
10 InputSource inputSource = new InputSource(inputStream);
11 if (encodedResource.getEncoding() != null) {
12 inputSource.setEncoding(encodedResource.getEncoding());
13 }
14 // ... 具体的读取过程
15 return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
16 }
17 finally {
18 inputStream.close();
19 }
20 }
21 // 省略一些代码
22 }
从 encodedResource 源中获取 xml 的解析源,然后调用 #doLoadBeanDefinitions(InputSource inputSource, Resource resource) 方法,执行具体的解析过程。
// XmlBeanDefinitionReader.java
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 获取 XML Document 实例
Document doc = doLoadDocument(inputSource, resource);
// 根据 Document 实例,注册 Bean 信息
int count = registerBeanDefinitions(doc, resource);
return count;
}
// ... 省略一堆配置
}
2.1 转换为 Document 对象
调用在上面方法中 #doLoadDocument(InputSource inputSource, Resource resource) 方法,会将 Bean 定义的资源转换为 Document 对象。代码如下:
// XmlBeanDefinitionReader.java
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
该方法接受五个参数:
inputSource :加载 Document 的 Resource 源。
entityResolver :解析文件的解析器。
errorHandler :处理加载 Document 对象的过程的错误。
validationMode :验证模式。
namespaceAware :命名空间支持。如果要提供对 XML 名称空间的支持,则为 true
#loadDocument(InputSource inputSource, EntityResolver entityResolver, ErrorHandler errorHandler, int validationMode, boolean namespaceAware) 方法,在类 DefaultDocumentLoader 中提供了实现。代码如下:
1 // DefaultDocumentLoader.java
2
3 @Override
4 public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
5 ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
6 // 创建 DocumentBuilderFactory
7 DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
8 // 创建 DocumentBuilder
9 DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
10 // 解析 XML InputSource 返回 Document 对象
11 return builder.parse(inputSource);
12 }
2.2 注册 BeanDefinition 流程
这到这里,就已经将定义的 Bean 资源文件,载入并转换为 Document 对象了。那么,下一步就是如何将其解析为 SpringIoC 管理的 BeanDefinition 对象,并将其注册到容器中。这个过程由方法 #registerBeanDefinitions(Document doc, Resource resource) 方法来实现。代码如下
1 // XmlBeanDefinitionReader.java
2
3 public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
4 // 创建 BeanDefinitionDocumentReader 对象
5 BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
6 // 获取已注册的 BeanDefinition 数量
7 int countBefore = getRegistry().getBeanDefinitionCount();
8 // 创建 XmlReaderContext 对象
9 // 注册 BeanDefinition
10 documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
11 // 计算新注册的 BeanDefinition 数量
12 return getRegistry().getBeanDefinitionCount() - countBefore;
13 }
(1)首先,创建 BeanDefinition 的解析器 BeanDefinitionDocumentReader 。
(2)然后,调用该 BeanDefinitionDocumentReader 的 #registerBeanDefinitions(Document doc, XmlReaderContext readerContext) 方法,开启解析过程,这里使用的是委派模式,具体的实现由子类 DefaultBeanDefinitionDocumentReader 完成。代码如下:
1 // DefaultBeanDefinitionDocumentReader.java
2
3 @Override
4 public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
5 this.readerContext = readerContext;
6 // 获得 XML Document Root Element
7 // 执行注册 BeanDefinition
8 doRegisterBeanDefinitions(doc.getDocumentElement());
9 }
2.2.1 对 Document 对象的解析从 Document 对象中获取根元素 root,然后调用 #doRegisterBeanDefinitions(Element root)` 方法,开启真正的解析过程。代码如下:
// DefaultBeanDefinitionDocumentReader.java
protected void doRegisterBeanDefinitions(Element root) {
// ... 省略部分代码(非核心)
this.delegate = createDelegate(getReaderContext(), root, parent);
// 解析前处理
preProcessXml(root);
// 解析
parseBeanDefinitions(root, this.delegate);
// 解析后处理
postProcessXml(root);
}
#parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) 是对根元素 root 的解析注册过程。代码如下:
// DefaultBeanDefinitionDocumentReader.java
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 如果根节点使用默认命名空间,执行默认解析
if (delegate.isDefaultNamespace(root)) {
// 遍历子节点
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 如果该节点使用默认命名空间,执行默认解析
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
// 如果该节点非默认命名空间,执行自定义解析
} else {
delegate.parseCustomElement(ele);
}
}
}
// 如果根节点非默认命名空间,执行自定义解析
} else {
delegate.parseCustomElement(root);
}
}
迭代 root 元素的所有子节点,对其进行判断:
#parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) BeanDefinitionParserDelegate#parseCustomElement(Element ele)
2.2.1.1 默认标签解析
若定义的元素节点使用的是 Spring 默认命名空间,则调用 #parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) 方法,进行默认标签解析。代码如下:
// DefaultBeanDefinitionDocumentReader.java
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) { // import
importBeanDefinitionResource(ele);
} else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { // alias
processAliasRegistration(ele);
} else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { // bean
processBeanDefinition(ele, delegate);
} else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { // beans
// recurse
doRegisterBeanDefinitions(ele);
}
}
对四大标签: <import> 、 <alias> 、 <bean> 、 <beans> 进行解析。
2.2.1.2 自定义标签解析
对于默认标签则由 parseCustomElement(Element ele) 方法,负责解析。代码如下:
1 // BeanDefinitionParserDelegate.java
2
3 @Nullable
4 public BeanDefinition parseCustomElement(Element ele) {
5 return parseCustomElement(ele, null);
6 }
7
8 @Nullable
9 public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
10 // 获取 namespaceUri
11 String namespaceUri = getNamespaceURI(ele);
12 if (namespaceUri == null) {
13 return null;
14 }
15 // 根据 namespaceUri 获取相应的 Handler
16 NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
17 if (handler == null) {
18 error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
19 return null;
20 }
21 // 调用自定义的 Handler 处理
22 return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
23 }
获取节点的 namespaceUri ,然后根据该 namespaceUri 获取相对应的 NamespaceHandler,最后调用 NamespaceHandler 的 #parse(Element element, ParserContext parserContext) 方法,即完成自定义标签的解析和注入。
2.2.2 注册 BeanDefinition
经过上面的解析,则将 Document 对象里面的 Bean 标签解析成了一个个的 BeanDefinition ,下一步则是将这些 BeanDefinition 注册到 IoC 容器中。动作的触发是在解析 Bean 标签完成后,代码如下
// DefaultBeanDefinitionDocumentReader.java
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 进行 bean 元素解析。
// 如果解析成功,则返回 BeanDefinitionHolder 对象。而 BeanDefinitionHolder 为 name 和 alias 的 BeanDefinition 对象
// 如果解析失败,则返回 null 。
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 进行自定义标签处理
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 进行 BeanDefinition 的注册
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
} catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 发出响应事件,通知相关的监听器,已完成该 Bean 标签的解析。
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
调用 BeanDefinitionReaderUtils.registerBeanDefinition() 方法,来注册。其实,这里面也是调用 BeanDefinitionRegistry 的 #registerBeanDefinition(String beanName, BeanDefinition beanDefinition) 方法,来注册 BeanDefinition 。不过,最终的实现是在 DefaultListableBeanFactory 中实现,代码如下:
1 // DefaultListableBeanFactory.java
2 @Override
3 public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
4 throws BeanDefinitionStoreException {
5 // ...省略校验相关的代码
6 // 从缓存中获取指定 beanName 的 BeanDefinition
7 BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
8 // 如果已经存在
9 if (existingDefinition != null) {
10 // 如果存在但是不允许覆盖,抛出异常
11 if (!isAllowBeanDefinitionOverriding()) {
12 throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
13 } else {
14 // ...省略 logger 打印日志相关的代码
15 }
16 // 【重点】允许覆盖,直接覆盖原有的 BeanDefinition 到 beanDefinitionMap 中。
17 this.beanDefinitionMap.put(beanName, beanDefinition);
18 // 如果未存在
19 } else {
20 // ... 省略非核心的代码
21 // 【重点】添加到 BeanDefinition 到 beanDefinitionMap 中。
22 this.beanDefinitionMap.put(beanName, beanDefinition);
23 }
24 // 重新设置 beanName 对应的缓存
25 if (existingDefinition != null || containsSingleton(beanName)) {
26 resetBeanDefinition(beanName);
27 }
28 }
这段代码最核心的部分是这句 this.beanDefinitionMap.put(beanName, beanDefinition) 代码段。所以,注册过程也不是那么的高大上,就是利用一个 Map 的集合对象来存放: key 是 beanName , value 是 BeanDefinition 对象
3. 小结
至此,整个 IoC 的初始化过程就已经完成了,从 Bean 资源的定位,转换为 Document 对象,接着对其进行解析,最后注册到 IoC 容器中,都已经完美地完成了。现在 IoC 容器中已经建立了整个 Bean 的配置信息,这些 Bean 可以被检索、使用、维护,他们是控制反转的基础,是后面注入 Bean 的依赖。最后用一张流程图来结束这篇总结之文。
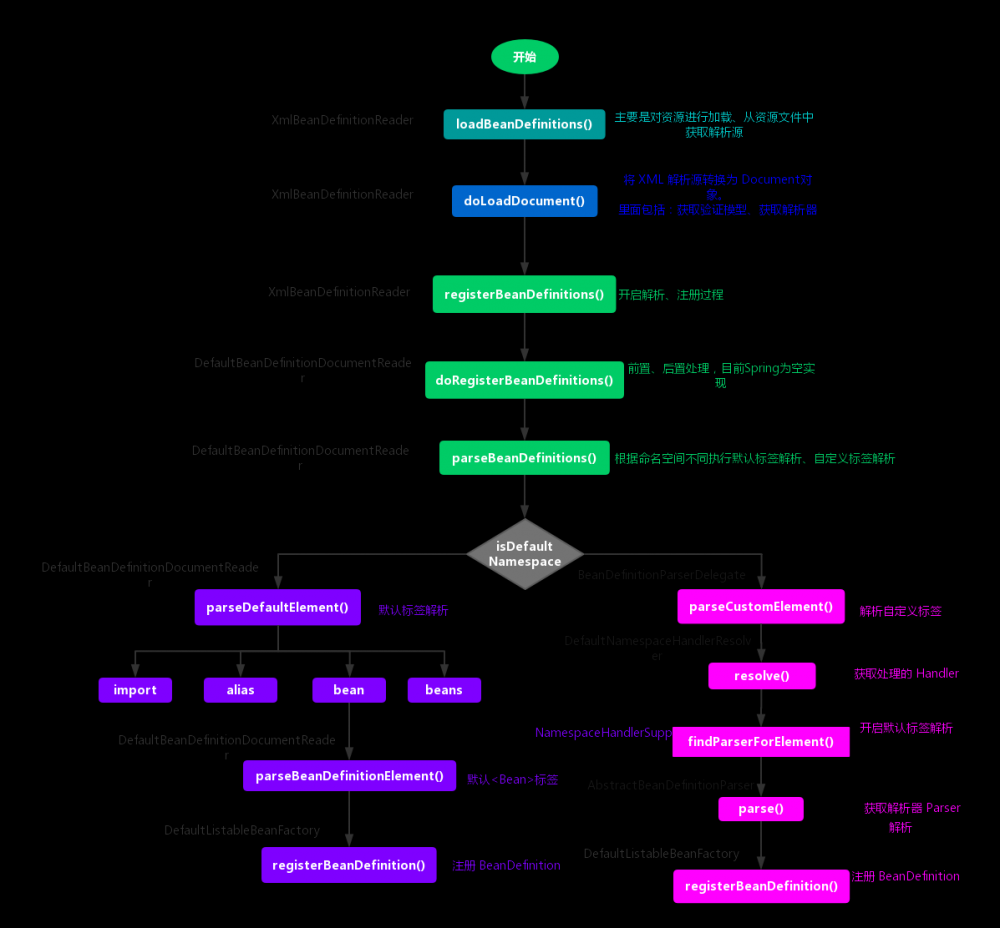
正文到此结束
- 本文标签: spring 管理 遍历 参数 http IO 自定义标签 rmi db IDE 解析 list entity ioc stream node UI HTML value src bean 缓存 tab 配置 CTO key build BeanDefinition springioc 源码 map CEO XML schema 监听器 构造方法 classpath cat 空间 实例 spring ioc 文章 equals root 进程 时间 Document 总结 ACE id java https 代码 parse final 博客 希望
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

