Hutool 指南 API
介绍一款超厉害的国产 Java工具——Hutool 。Hutool是一个Java工具包类库,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类。适用于很多项目以及Web开发,并且与其他框架没有耦合性。
=========================================================
1. Hutool之时间工具——DateUtil
1.1 时间日期类介绍
-
DateUtil针对日期时间操作提供一系列静态方法 -
DateTime提供类似于Joda-Time中日期时间对象的封装,继承Date -
FastDateFormat提供线程安全的针对Date对象的格式化和日期字符串解析支持。此对象在实际使用中并不需要感知,相关操作已封装在DateUtil和DateTime的相关方法中。 -
DateBetween计算两个时间间隔的类,除了通过构造新对象使用外,相关操作也已封装在DateUtil和DateTime的相关方法中。 -
TimeInterval一个简单的计时器类,常用于计算某段代码的执行时间,提供包括毫秒、秒、分、时、天、周等各种单位的花费时长计算,对象的静态构造已封装在DateUtil中。 -
DatePattern提供常用的日期格式化模式,包括String和FastDateFormat两种类型。
主要需要了解DateUtil类,DateTime类以及DatePattern类就可以应对大多数时间日期的操作。
1.2 时间工具类DateUtil
DateUtil中都是静态方法, 下面是一些 简单方法 ;
now():String //当前日期时间 yyyy-MM-dd hh:mm:ss
today():String //今天日期 yyyy-MM-dd
date():DateTime
/*当前时间的DateTime对象(相当于new DateTime()或者new Date()),
此外还提供一个重载方法,传递long类型参数,是给定一个Unix时间戳,
返回这个时间戳的时间。*/
lastWeek():DateTime //上周今天(往前7天)
lastMonth():DateTime //上个月今天(往前一个月)
nextWeek():DateTime //下周今天(往后7天)
nextMonth():DateTime //下个月今天(往后一个月)
yesterday():DateTime //昨天同时
tomorrow():DateTime //明天同时
currentSeconds():long //毫秒数
thisYear():int //年份
thisMonth():int //月份(从0开始)
thisWeekOfMonth():int //本月周次(从1开始)
thisWeekOfYear():int //本年周次(从1开始)
thisDayOfMonth():int //本月第几天(从1开始)
thisDayOfWeek():int //本周第几天(从1开始)
thisHour(boolean is24HourClock):int //当前小时
thisMinute():int //当前分
thisSecond():int //当前秒
复制代码
1.3 日期与字符串之间的转化
1.3.1 解析日期字符串
将一些固定格式的字符串-->Date对象:
yyyy-MM-dd hh:mm:ss
yyyy-MM-dd
hh:mm:ss
yyyy-MM-dd hh:mm
如果你的日期格式不是这几种格式,则需要指定日期格式,对于以上格式还有专门的方法对应:
parseDateTime parseDate ParseTime
DateUtil.parse()
DateUtil.parse(String,String) //Date 转换为指定格式的Date对象
复制代码
1.3.2 格式化日期
需要将日期时间格式化输出,Hutool提供了一些方法实现:
DateUtil.formatDateTime(Date date):String //将返回“yyyy-MM-dd hh:mm:ss”格式字符串
DateUtil.formatDate(Date date):String //将返回“yyyy-MM-dd“格式字符串
DateUtil.formatTime(Date date):String //将返回“hh:mm:ss“格式字符串
DateUtil.format(Date,String):String //将返回指定格式的字符串
复制代码
1.4 开始和结束时间
Hutool可以很方便的获得某天/某月/某年的开始时刻和结束时刻:
beginOfDay(Date):Date 一天开始时刻 endOfDay(Date):Date 一天结束时刻 beginOfMonth(Date):Date endOfMonth(Date):Date beginOfYear(Date):Date endOfYear(Date):Date getBeginTimeOfDay 获得给定日期当天的开始时间,开始时间是00:00 getEndTimeOfDay 获得给定日期当天的结束时间,结束时间是23:59。 复制代码
需要指定日期做偏移,则使用offsiteDay、offsiteWeek、offsiteMonth来获得指定 日期偏移 天、偏移周、偏移月,指定的偏移量正数向未来偏移,负数向历史偏移。
如果以上还不能满足偏移要求,则使用offsiteDate偏移制定量,其中参数calendarField为偏移的粒度大小(小时、天、月等)使用Calendar类中的常数。
1.5 时间间隔
1.between方法
Hutool可以方便的计算时间间隔,使用 DateUtil.between(Date begin,Date end,DateUnit):long
计算间隔,方法有三个参数,前两个分别是开始时间和结束时间,第三个参数是DateUnit的枚举,
表示差值以什么为单位。
DateUnit的取值可以是DateUnit.DAY(天),DateUnit.HOUR(小时),DateUnit.WEEK(周),
DateUnit.SECOND(秒),DateUnit.MINUTE(分钟);
2.formatBetween方法
也可以将差值转为指定具体的格式,比如 XX天XX小时XX分钟XX秒 这样的格式,可以使用
DateUtil.formatBetween(Date begin,Date end,Level):String 方法,有三个参数,
前两个依然是开始和结束时间,第三个参数表示精确度,比如Level.SECOND表示精确到秒,
即XX天XX小时XX分钟XX秒的格式。
3.diff方法
返回两个日期的时间差,参数diffField定义了这个差的单位,单位的定义在DateUtil的常量中,
例如DateUtil.SECOND_MS表示两个日期相差的秒数。
复制代码
1.6 计算年龄
用了Hutool可以瞬间计算年龄,你还需要担心什么虚岁周岁吗?不需要,Hutool说多少就是多少。我们可以使用如下方法:
age(Date begin,Date end):int 出生和去世日期计算年龄 ageOfNow(String birthday):int 计算到当前日期的年龄 ageOfNow(Date birthday):int 计算到当前日期的年龄 复制代码
1.7 判断闰年
使用 DateUtil.isLeapYear(in year) :boolean判断是否为闰年。
1.8 DateTime
了解了DateUtil,再来看DateTime应该是很简单的,因为DateTime里面的大多数方法和DateUtil是类似的。DateTime类继承自java.util.Date,完全可以替代Date的使用并且还有其他的实用方法!
首先来了解一下DateTime的构造方法:
方法一:使用new DateTime dt=new DateTime(); //创建当前时刻 DateTime dt=new DateTime(Date date); //使用Date对象构造 DateTime dt=new DateTime(long timeMillis); //使用毫秒数构造 方法二:使用of()方法 DateTime dt=DateTime.of(); 方法三:使用now()方法 DateTime dt=DateTime.now(); //创建当前时刻 DateTime里面还有两个非常实用的方法,就是before(Date when):boolean 和 after(Date when):boolean, 它们可以判断时间的先后。 复制代码
1.9 DatePattern
最后了解一下DatePattern类,这个类主要是提供了一些 指定的时间日期格式(都是String类型) ,包括地区的区别表示:
格式化模板:
DatePattern.CHINESE_DATE_PATTERN //yyyy年MM月dd日
DatePattern.NORM_DATE_PATTERN //yyyy-MM-dd
DatePattern.NORM_TIME_PATTERN //HH:mm:ss
DatePattern.NORM_DATETIME_PATTERN //yyyy-MM-dd HH:mm:ss
DatePattern.UTC_PATTERN //yyyy-MM-dd'T'HH:mm:ss'Z'
DatePattern.PURE_DATE_PATTERN //yyyyMMdd
DatePattern.PURE_TIME_PATTERN //HHmmss
DatePattern.PURE_DATETIME_PATTERN //yyyyMMddHHmmss
复制代码
作者:「612星球的一只天才猪」路小磊
原文链接:https://blog.csdn.net/tianc_pig/article/details/87826810
https://my.oschina.net/looly/blog/268552
来源:CSDN oschina
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复制代码
=========================================================
2. Hutool之字符串工具——StrUtil
字符串工具指 cn.hutool.core.util.StrUtil 类,其中对String的多种方法进行了封装并且提供了其他方便实用的方法。StrUtil中的方法是静态方法。
2.1 从多个字符串中判断是否有空
这里的空有两层含义:一是null或者“”(空串),二是不可见字符构成的字符串(不可见字符串),比如由空格构成的字符串(“ ”)。针对两种情况Hutool提供了不同的方法来解决。
类似于 Apache Commons Lang 中的StringUtil,之所以使用StrUtil而不是使用StringUtil是因为前者更短,而且Str这个简写我想已经深入人心。常用的方法, 例如isBlank、isNotBlank、isEmpty、isNotEmpty这些就不做介绍了,判断字符串是否为空,下面我说几个比较好用的功能。
常用的方法如下表所示:
isBlank(CharSequence arg0):boolean //判断字符串是否为null或者””或者是不可见字符串 isEmpty(charSequence arg0):boolean //判断字符串是否为null或者”” hasBlank(CharSequence…arg0):boolean //判断多个字符串中是否有null或者””或者是不可见字符串 hasEmpty(CharSequence…arg0):boolean //判断多个字符串中是否有null或者”” 表单登录时,常用hasEmpty()方法。 复制代码
2.2 sub方法
sub()方法相当于subString()方法;
有三个参数:第一个是截取的字符串,后两个是首尾位置。sub()方法有一个最大的特点就是容错率非常高,并且-1表示最后一个字符,-2表示倒数第二个字符,以此类推。 并且首尾位置也可以颠倒。
String testStr="my name is smartPig"; String result01=StrUtil.sub(testStr, 0, 4); //my n /*虽然是4-0,但是实际上还是算成0-4*/ String result02=StrUtil.sub(testStr, 4, 0); //my n String result03=StrUtil.sub(testStr, -1, 3); //name is smartPi String result04=StrUtil.sub(testStr, -4, 3); //name is smar 复制代码
2.3 format方法
format方法类似于JDBC中PreparedStatement中的?占位符,可以在字符串中使用”{}”作为占位符。
String testStr="{} name is smart{}";
String result=StrUtil.format(testStr, "my","Pig"); //my对应第一个{},Pig对应第二个{}
//结果如下:my name is smartPig
复制代码
2.4 去除前后缀
Hutool可以去除字符串的前缀/后缀,这个特点非常适用于去除文件的后缀名。相关方法如下表:
removeSuffix(CharSequence str, CharSequence suffix) //去除后缀 removeSuffixIgnoreCase(CharSequence str, CharSequence suffix) //去除后缀,忽略大小写 removePrefix(CharSequence str, CharSequence suffix) //去除前缀 removePrefixIgnoreCase(CharSequence str, CharSequence suffix) //去除前缀,忽略大小写 复制代码
2.5 字符串常量
Hutool定义了一些字符常量,可以灵活使用。部分常量如下所示: 复制代码
StrUtil.DOT //点.
StrUtil.DOUBLE_DOT //双点..
StrUtil.UNDERLINE //下划线_
StrUtil.EMPTY //横杠_
StrUtil.BACKSLASH //反斜杠/
StrUtil.DASHED //破折-
StrUtil.BRACKET_END //右中扩号]
StrUtil.BRACKET_START //左中括号[
StrUtil.COLON //冒号:
StrUtil.COMMA //逗号,
StrUtil.DELIM_END //右大括号}
StrUtil.DELIM_START //左大括号{
复制代码
2.6 字符串逆序
Hutool可以很容易的实现字符串逆序。可以使用StrUtil.reverse(String str):String方法。 复制代码
2.7 encode、decode方法
把String.getByte(String charsetName)方法封装在这里了,原生的String.getByte()这个方法太坑了,使用系统编码, 经常会有人跳进来导致乱码问题,所以就加了这两个方法强制指定字符集了,包了个try抛出一个运行时异常, 省的我得在业务代码里处理那个恶心的UnsupportedEncodingException。 复制代码
作者:「612星球的一只天才猪」路小磊
原文链接:https://blog.csdn.net/tianc_pig/article/details/87944463
https://my.oschina.net/looly/blog/262775
来源:CSDN oschina
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复制代码
=========================================================
3. Hutool之随机工具——RandomUtil
随机工具的主要方法如下:
RandomUtil.randomInt 获得指定范围内的随机数 RandomUtil.randomEle 随机获得列表中的元素 RandomUtil.randomString 获得一个随机的字符串(只包含数字和字符) RandomUtil.randomNumbers 获得一个只包含数字的字符串 RandomUtil.randomNumber 获得一个随机数 RandomUtil.randomChar 获得随机字符 复制代码
这些方法都有一些重载方法,如下表:
randomInt():int //获得一个随机整数 randomInt(int limit):int //获得一个<limit的随机整数 randomInt(int min,int max):int //获得一个随机整数n(min<=n<max) randomChar():char //获得一个随机字符 randomChar(Strint str):char //从指定字符串中获得一个随机字符 randomNumber():int //获得一个随机数 randomNumbers(int length):String //获得长度为length由数字组成的字符串 randomString(int length):String //获得一个长度为length的字符串,只包含数字和字符 randomString(String str,int length):String //从str中随机产生指定长度的字符串(所有字符来源于str) randomEle(T array[]):T //从数组中随机获取一个数据 randomEle(List<T> list):T //从List中随机获取一个数据 randomEle(List<T> list,int limit):T //从List的前limit个中随机获取一个数据(limit从1开始) 复制代码
作者:「612星球的一只天才猪」 原文链接:https://blog.csdn.net/tianc_pig/article/details/88034976 来源:CSDN 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
4. Hutool之正则工具——ReUtil
4.1 判断是否匹配
使用 isMatch(String regex,CharSequence content):boolean 第一个参数是正则,第二个是匹配的内容。 复制代码
4.2 删除所匹配的内容
delFirst(String regex,CharSequence content):String //删除匹配的第一个字符串,返回删除后的字符串 delAll(String regex,CharSequence content):String //删除匹配的所有字符串,返回删除后的字符串 复制代码
4.3 得到匹配的内容
使用findAll(String regex, CharSequence content, int group): List<String> 可以获得所有匹配的内容 复制代码
4.4 替换匹配内容
使用replaceAll(CharSequence content, String regex, String replacementTemplate):String 可以替换匹配的内容。 复制代码
4.4 自动转义特殊字符
使用escape(CharSequence arg0):String 可以将用于正则表达式中的某些特殊字符进行转义,变成转义字符。 复制代码
作者:「612星球的一只天才猪」 原文链接:https://blog.csdn.net/tianc_pig/article/details/88134882 来源:CSDN 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
5. Hutool之分页工具——PageUtil
PageUtil的静态方法 复制代码
transToStartEnd(int,int):int[] //将页数和页容量转换为数据表中的起始位置
/*第一个参数是页码数,第二个参数是每一页的容量,
返回值是一个长度为2的数组,分别表示开始位置和结束位置。*/
/*获得指定页的结果集
@param pageNum 页数(从1开始)
@param pageSize 每页容量
int startEnd[]=PageUtil.transToStartEnd(pageNum, pageSize);*/
totalPage(int,int):int //由总记录数和页容量获得页数
//第一个参数是总的记录数,第二个参数是每页的容量,返回值是总页数。
/*
@param totalCount 总记录数
@param pageSize 每页的记录数
int totalPage = PageUtil.totalPage(totalCount, pageSize);*/
彩虹分页算法
rainbow(int,int):int[]
//第一个参数表示当前页码,第二个参数表示总页数,这种情况默认是一次显示所有的页码
//(这个方法个人觉得没有什么用)
rainbow(int,int,int):int[]
//第一个参数表示当前页码,第二个参数表示总页数,第三个参数表示每一次最多显示的页数
复制代码
彩虹分页算法应用于网页中需要经常显示【上一页】1 2 3 4 5 【下一页】这种页码的情况,一般都根据当前的页码动态的更新所显示出来的页码,因为每次所显示的页码的数量是固定的。
/**
* 测试分页彩虹算法
* @param curPage 当前页数
* @param totalPage 总页数
*/
public static String rainbowPage(int curPage,int totalPage) {
int rainbow[]=PageUtil.rainbow(curPage,totalPage);
return Arrays.toString(rainbow);
}
/**
* 测试分页彩虹算法
* @param curPage 当前页数
* @param totalPage 总页数
* @param size 每次显示的页数量
*/
public static String rainbowPage(int curPage,int totalPage,int size) {
int rainbow[]=PageUtil.rainbow(curPage,totalPage,size);
return Arrays.toString(rainbow);
}
复制代码
MyBatis就提供了分页工具,并且支持插件分页
作者:「612星球的一只天才猪」 原文链接:https://blog.csdn.net/tianc_pig/article/details/88628323 来源:CSDN 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
6. Hutool之集合工具——CollectionUtil
主要增加了对数组、集合类的操作。
6.1 join 方法
将集合转换为字符串,这个方法还是挺常用,是StrUtil.split的反方法。这个方法的参数支持各种类型对象的集合,最后连接每个对象时候调用其toString()方法。如下:
String[] col= new String[]{a,b,c,d,e};
String str = CollectionUtil.join(col, "#"); //str -> a#b#c#d#e
复制代码
6.2 sortPageAll、sortPageAll2方法
功能是:将给定的多个集合放到一个列表(List)中,根据给定的Comparator对象排序,然后分页取数据。这个方法非常类似于数据库多表查询后排序分页,这个方法存在的意义也是在此。sortPageAll2功能和sortPageAll的使用方式和结果是 一样的,区别是sortPageAll2使用了BoundedPriorityQueue这个类来存储组合后的列表,不知道哪种性能更好一些,所以就都保留了。如下:
Comparator<Integer> comparator = new Comparator<Integer>(){ //Integer比较器
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
};
//新建三个列表,CollectionUtil.newArrayList方法表示新建ArrayList并填充元素
List<Integer> list1 = CollectionUtil.newArrayList(1, 2, 3);
List<Integer> list2 = CollectionUtil.newArrayList(4, 5, 6);
List<Integer> list3 = CollectionUtil.newArrayList(7, 8, 9);
//参数表示把list1,list2,list3合并并按照从小到大排序后,取0~2个(包括第0个,不包括第2个),结果是[1,2]
@SuppressWarnings("unchecked")
List<Integer> result = CollectionUtil.sortPageAll(0, 2, comparator, list1, list2, list3);
System.out.println(result); //输出 [1,2]
复制代码
6.3 sortEntrySetToList方法
主要是对 Entry<Long, Long> 按照Value的值做排序,使用局限性较大
6.4 popPart方法
这个方法传入一个栈对象,然后弹出指定数目的元素对象,弹出是指pop()方法,会从原栈中删掉。
6.5 newHashMap、newHashSet、newArrayList方法
这些方法是新建相应的数据结构,数据结构元素的类型取决于你变量的类型,如下:
HashMap<String, String> map = CollectionUtil.newHashMap(); HashSet<String> set = CollectionUtil.newHashSet(); ArrayList<String> list = CollectionUtil.newArrayList(); 复制代码
6.6 append方法
在给定数组里末尾加一个元素,其实List.add()也是这么实现的,这个方法存在的意义是只有少量的添加元素时使用,因为内部使用了System.arraycopy,每调用一次就要拷贝数组一次。这个方法也是为了在某些只能使用数组的情况下使用,省去了先要转成List,添加元素,再转成Array。
6.7 resize方法
重新调整数据的大小,如果调整后的大小比原来小,截断,如果比原来大,则多出的位置空着。(貌似List在扩充的时候会用到类似的方法)
6.8 addAll方法
将多个数据合并成一个数组
6.9 range方法
这个方法来源于Python的一个语法糖,给定开始和结尾以及步进,就会生成一个等差数列(列表)
int[] a1 = CollectionUtil.range(6); //[0,1,2,3,4,5] int[] a2 = CollectionUtil.range(4, 7); //[4,5,6] int[] a3 = CollectionUtil.range(4, 9, 2); //[4,6,8] 复制代码
6.10 sub方法
对集合切片,其他类型的集合会转换成List,封装List.subList方法,自动修正越界等问题,完全避免IndexOutOfBoundsException异常。
6.11 isEmpty、isNotEmpty方法
判断集合是否为空(包括null和没有元素的集合)。
6.12 zip方法
此方法也是来源于Python的一个语法糖,给定两个集合,然后两个集合中的元素一一对应,成为一个Map。此方法还有一个重载方法,可以传字符,然后给定分隔符,字符串会被split成列表。
String[] keys = new String[]{"a", "b", "c"};
Integer[] values = new Integer[]{1, 2, 3};
Map<String, Integer> map = CollectionUtil.zip(keys,values);
System.out.println(map); // {b=2, c=3, a=1}
String a = "a,b,c";
String b = "1,2,3";
Map<String, String> map2 = CollectionUtil.zip(a,b, ",");
System.out.println(map2); // {b=2, c=3, a=1}
复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/262786 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
7. Hutool之类处理工具——ClassUtil
主要是封装了一些反射的方法,而这个类中最有用的方法是scanPackage方法,这个方法会扫描classpath下所有类,这个在Spring中是特性之一,主要为Hulu框架中类扫描的一个基础
7.1 scanPackage方法
此方法唯一的参数是包的名称,返回结果为此包以及子包下所有的类。方法使用很简单,但是过程复杂一些,包扫面首先会调用 getClassPaths方法获得ClassPath,然后扫描ClassPath,如果是目录,扫描目录下的类文件,或者jar文件。如果是jar包,则直接从jar包中获取类名。这个方法的作用显而易见,就是要找出所有的类,在Spring中用于依赖注入,在Hulu中则用于找到Action类。当然,也可以传一个ClassFilter对象,用于过滤不需要的类。
7.2 getMethods方法
此方法同Class对象的·getMethods·方法,只不过只返回方法的名称(字符串),封装非常简单。
7.3 getClassPaths方法
此方法是获得当前线程的ClassPath,核心是Thread.currentThread().getContextClassLoader().getResources的调用。
7.4 getJavaClassPaths方法
此方法用于获得java的系统变量定义的ClassPath。
7.5 parse方法
此方法封装了强制类型转换,首先会调用对象本身的cast方法,失败则尝试是否为基本类型(int,long,double,float等),再失败则尝试日期、数字和字节流,总之这是一个包容性较好的类型转换方法,省去我们在不知道类型的情况下多次尝试的繁琐。
7.6 parseBasic方法
此方法被parse方法调用,专门用于将字符集串转换为基本类型的对象(Integer,Double等等)。可以说这是一个一站式的转换方法,JDK的方法名太别扭了,例如你要转换成Long,你得调用Long.parseLong方法,直接Long.parse不就行了……真搞不懂,所以才有了这个方法。
7.7 castToPrimitive方法
这个方法比较别扭,就是把例如Integer类变成int.class,貌似没啥用处,忘了哪里用了,如果你能用到,就太好了。
7.8 getClassLoader和getContextClassLoader方法
后者只是获得当前线程的ClassLoader,前者在获取失败的时候获取ClassUtil这个类的ClassLoader。
7.9 newInstance方法
实例化对象,封装了Class.forName(clazz).newInstance()方法。
7.10 cloneObj方法
克隆对象。对于有些对象没有实现Cloneable接口的对象想克隆下真是费劲,例如封装Redis客户端的时候,配置对象想克隆下基本不可能,于是写了这个方法,原理是使用ObjectOutputStream复制对象流。
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/268087 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
8. Hutool之类文件工具——FileUtil
8.1 简介
在Java工具中,文件操作应该也是使用相当频繁的,但是Java对文件的操作由于牵涉到流,所以较为繁琐,各种Stream也是眼花缭乱,因此大部分项目里的util包中我想都有一个FileUtil的类,而本类就是对众多FileUtil的总结。
8.2 Linux命令对应方法
这些方法都是按照Linux命令来命名的,方便熟悉Linux的用户见名知意,例如:
ls 返回给定目录的所有文件对象列表,路径可以是相对ClassPath路径或者绝对路径,不可以是压缩包里的路径。 listFileNames 则是返回指定目录下的所有文件名,支持jar等压缩包。 touch 创建文件,如果给定路径父目录不存在,也一同创建。 del 删除文件或者目录,目录下有嵌套目录或者文件会一起删除。 mkdir 创建目录,父目录不存在自动创建。 createTempFile 创建临时文件,在程序运行完毕的时候,这个文件会被删除。 copy 复制文件或目录,目标文件对象可以是目录,自动用原文件名,可以选择是否覆盖目标文件。 move 移动文件或目录,原理是先复制,再删除原文件或目录 isExist 文件或者目录是否存在。 复制代码
8.3 常用方法
getAbsolutePath 获得绝对路径,如果给定路劲已经是绝对路径,返回原路径,否则根据ClassPath
或者给定类的相对位置获得其绝对位置
close 对于实现了Closeable接口的对象,可以直接调用此方法关闭,且是静默关闭,关闭出错将不
会有任何调试信息。这个方法也是使用非常频繁的,例如文件流的关闭等等。
equals 比较两个文件是否相同
复制代码
8.4 文件读写
8.4.1 写文件
getBufferedWriter 获得带缓存的写入对象,可以写字符串等。 getPrintWriter 对 getBufferedWriter的包装,可以有println等方法按照行写出。 getOutputStream 会的文件的写出流想对象。 writeString直接写字符串到文件,会覆盖之前的内容。 appendString 追加字符串到文本。 writeLines appendLines 覆盖写入和追加文本列表,每个元素都是一行。 writeBytes 写字节码。 writeStream 写流中的内容到文件里。 复制代码
8.4.2 读文件
getReader 获得带缓存的Reader对象。 readLines 按行读取文件中的数据,返回List,每一个元素都是一行文本。 load 按照给定的ReaderHandler对象读取文件中的数据,ReaderHandler是一个借口,实现后就可以操作Reader对象了,这个方法存在是为了避免用户手动调用close方法。 readString 直接读出文件中的所有文本。 readBytes 读字节码 复制代码
8.4.3 其他
isModifed 文件是否被修改过,需要传入一个时间戳,用来比对最后修改时间。 getExtension 获得文件的扩展名。 复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/288525 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
9. Hutool之有界优先队列-BoundedPriorityQueue
9.1 由来
举个例子: 我有一个用户表,这个表根据用户名被Hash到不同的数据库实例上,我要找出这些用户中最热门的5个,怎么做?我是这么做的:
在每个数据库实例上找出最热门的5个 将每个数据库实例上的这5条数据按照热门程度排序,最后取出前5条 复制代码
这个过程看似简单,但是你应用服务器上的代码要写不少。首先需要Query N个列表,加入到一个新列表中,排序,再取前5。这个过程不但代码繁琐,而且牵涉到多个列表,非常浪费空间。于是, BoundedPriorityQueu e应运而生。
/**
* 有界优先队列
*/
public class BoundedPriorityQueueDemo {
public static void main(String[] args) {
//初始化队列,设置队列的容量为5(只能容纳5个元素),
//元素类型为integer使用默认比较器,在队列内部将按照从小到大排序
BoundedPriorityQueue<Integer> queue = new BoundedPriorityQueue<Integer>(5);
//初始化队列,使用自定义的比较器
queue = new BoundedPriorityQueue<>(5, new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
//定义了6个元素,当元素加入到队列中,会按照从小到大排序,
//当加入第6个元素的时候,队列末尾(最大的元素)将会被抛弃
int[] array = new int[]{5,7,9,2,3,8};
for (int i : array) {
queue.offer(i);
}
//队列可以转换为List
ArrayList<Integer> list = queue.toList();
System.out.println(queue);
}
}
原理: 设定好队列的容量,然后把所有的数据add或者offer进去(两个方法相同),就会得到前5条数据。
复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/389940 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
10. Hutool之定时任务工具-CronUtil
10.1 由来
Java中定时任务使用的最多的就是 quartz 了,但是这个框架太过庞大,而且也不需要用到这么多东西,使用方法也是比较复杂。于是便寻找新的框架代替。用过Linux的 crontab 的人都知道,使用其定时的表达式可以非常灵活的定义定时任务的时间以及频率(Linux的crontab精确到分,而quaeta的精确到秒,不过对来说精确到分已经够用了,精确到秒的可以使用Timer可以搞定),然后就是crontab的配置文件,可以把定时任务很清晰的罗列出来。(记得当时Spring整合quartz的时候那XML看的眼都花了)。于是我便找到了一个轻量调度框架——cron4j
10.2 封装
为了隐藏这个框架里面的东西,对其做了封装,所谓封装,就是把任务调度放在一个配置文件里,然后启动即可(与Linux的crontab非常像)。
10.3 配置文件
对于Maven项目,首先在src/main/resources/config下放入cron4j.setting文件(默认是这个路径的这个文件),然后在文件中放入定时规则,规则如下:
#注释 [包名] TestJob = */10 * * * * TestJob2 = */10 * * * * 第二行等号前面是要执行的定时任务类名,等号后面是定时表达式。 TestJob是一个实现了Runnable接口的类,在start()方法里就可以加逻辑。 复制代码
关于定时任务表达式,它与Linux的crontab表达式一模一样,具体请看这里: www.cnblogs.com/peida/archi…
10.4 启动 关闭 定时任务
调用CronUtil.start()既可启动定时任务服务,CrontabUtil.stop()关闭服务。想动态的添加定时任务,使用CronUtil.schedule(String schedulingPattern, Runnable task)方法即可(使用此方法加入的定时任务不会被写入到配置文件)。
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/379677 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
11. Hutool之类型转换类-Convert
11.1 类型转换类Convert
在Java开发中会面对各种各样的类型转换问题,尤其是从命令行获取的用户参数、从HttpRequest获取的Parameter等等,这些参数类型多种多样,怎么去转换他们呢?常用的办法是先整成String,然后调用xxx. parse xxx方法,还要承受转换失败的风险,不得不加一层try catch,这个小小的过程混迹在业务代码中会显得非常难看和臃肿,于是把这种类型转换的任务封装在了Conver类中。
1. toStr、toInt、toLong、toDouble、toBool方法
这几个方法基本代替了JDK的XXX.parseXXX方法,传入两个参数,第一个是Object类型的被转换的值,
第二个参数是默认值。这些方法做转换并不抛出异常,当转换失败或者提供的值为null时,
只会返回默认值,返回的类型全部使用了包装类,方便我们需要null的情况。
2. 半角转全角toSBC和全角转半角toDBC
在很多文本的统一化中这两个方法非常有用,主要对标点符号的全角半角转换。
复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/270829 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
12. Hutool之单例池——Singleton
12.1 原因
使用单例不外乎两种方式:
在对象里加个静态方法getInstance()来获取。 此方式可以参考 【转】线程安全的单例模式[https://my.oschina.net/looly/blog/152865] 这篇博客, 可分为饿汉和饱汉模式。 通过Spring这类容器统一管理对象,用的时候去对象池中拿。Spring也可以通过配置决定懒汉或者饿汉模式 复制代码
说实话更倾向于第二种,但是Spring更对的的注入,而不是拿,于是想做Singleton这个类,维护一个单例的池,用这个单例对象的时候直接来拿就可以,这里用的懒汉模式。只是想把单例的管理方式换一种思路,希望管理单例的是一个容器工具,而不是一个大大的框架,这样能大大减少单例使用的复杂性。
12.2 使用
import com.xiaoleilu.hutool.Singleton;
/**
* 单例样例
*/
public class SingletonDemo {
/**
* 动物接口
*/
public static interface Animal{
public void say();
}
/**
* 狗实现
*/
public static class Dog implements Animal{
@Override
public void say() {
System.out.println("汪汪");
}
}
/**
* 猫实现
*/
public static class Cat implements Animal{
@Override
public void say() {
System.out.println("喵喵");
}
}
public static void main(String[] args) {
Animal dog = Singleton.get(Dog.class);
Animal cat = Singleton.get(Cat.class);
//单例对象每次取出为同一个对象,除非调用Singleton.destroy()或者remove方法
System.out.println(dog == Singleton.get(Dog.class)); //true
System.out.println(cat == Singleton.get(Cat.class)); //true
dog.say(); //汪汪
cat.say(); //喵喵
}
}
复制代码
12.2 总结
如有兴趣可以看下这个类,实现非常简单,一个HashMap用于做为单例对象池,通过newInstance()实例化对象(不支持带参数的构造方法),无论取还是创建对象都是线程安全的(在单例对象数量非常庞大且单例对象实例化非常耗时时可能会出现瓶颈),考虑到在get的时候使双重检查锁,但是并不是线程安全的,故直接加了synchronized做为修饰符,欢迎在此给出建议。
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/284922 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
13. Hutool之Properties替代——Setting
13.1 前言
对于JDK自带的Properties读取的Properties文件,有很多限制,首先是ISO8859-1编码导致没法加中文的value和注释(用日本的那个插件在Eclipse里可以读写,放到服务器上读就费劲了),再就是不支持变量分组等功能,因此有了Setting类。
13.2 由来
配置文件中使用变量这个需求由来已久,在Spring中PropertyPlaceholderConfigurer类就用于在ApplicationContext.xml中使用Properties文件中的变量替换。 分组的概念我第一次在Linux的rsync的/etc/rsyncd.conf配置文件中有所了解,发现特别实用具体大家可以百度。
而这两种功能后来在jodd的Props才有所发现,它的这个配置文件扩展类十分强大,甚至支持多行等等功能,本来想直接使用,避免重复造轮子,可是发现很多特性完全用不到,而且没有需要的便捷功能,于是便造了Setting这个轮子。
配置文件格式example.setting
<!-- lang: shell -->
# -------------------------------------------------------------
# ----- Setting File with UTF8-----
# ----- 数据库配置文件 -----
# -------------------------------------------------------------
#中括表示一个分组,其下面的所有属性归属于这个分组,在此分组名为demo,也可以没有分组
[demo]
#自定义数据源设置文件,这个文件会针对当前分组生效,用于给当前分组配置单独的数据库连接池参数,
#没有则使用全局的配置
ds.setting.path = config/other.setting
#数据库驱动名,如果不指定,则会根据url自动判定
driver = com.mysql.jdbc.Driver
#JDBC url,必须
url = jdbc:mysql://fedora.vmware:3306/extractor
#用户名,必须
user = root${driver}
#密码,必须,如果密码为空,请填写 pass =
pass = 123456
复制代码
配置文件可以放在任意位置,具体Setting类如何寻在在构造方法中提供了多种读取方式,具体稍后介绍。现在说下配置文件的具体格式, Setting配置文件类似于Properties文件,规则如下:
-
注释用#开头表示,只支持单行注释,空行和无法正常被识别的键值对也会被忽略,可作为注释,但是建议显式指定注释。
-
键值对使用key = value 表示,key和value在读取时会trim掉空格,所以不用担心空格。
-
分组为中括号括起来的内容(例如配置文件中的[demo]),中括号以下的行都为此分组的内容,无分组相当于空字符分组,即[]。若某个key是name,分组是group,加上分组后的key相当于group.name。
-
支持变量,默认变量命名为 {driver}会被替换为com.mysql.jdbc.Driver,为了性能,Setting创建的时候构造方法会指定是否开启变量替换,默认不开启。
<!-- lang: java -->
import java.io.IOException;
import com.xiaoleilu.hutool.CharsetUtil;
import com.xiaoleilu.hutool.FileUtil;
import com.xiaoleilu.hutool.Setting;
/**
* Setting演示样例类
*/
public class SettingDemo {
public static void main(String[] args) throws IOException {
//-------------------------初始化
//读取classpath下的XXX.setting,不使用变量
Setting setting = new Setting("XXX.setting");
//读取classpath下的config目录下的XXX.setting,不使用变量
setting = new Setting("config/XXX.setting");
//读取绝对路径文件/home/looly/XXX.setting(没有就创建,关于touch请查阅FileUtil)
//第二个参数为自定义的编码,请保持与Setting文件的编码一致
//第三个参数为是否使用变量,如果为true,则配置文件中的每个key都可以被之后的条目中的value引用形式为 ${key}
setting = new Setting(FileUtil.touch("/home/looly/XXX.setting"), CharsetUtil.UTF_8, true);
//读取与SettingDemo.class文件同包下的XXX.setting
setting = new Setting("XXX.setting", SettingDemo.class, CharsetUtil.UTF_8, true);
//--------------------------使用
//获取key为name的值
setting.getString("name");
//获取分组为group下key为name的值
setting.getString("name", "group1");
//当获取的值为空(null或者空白字符时,包括多个空格),返回默认值
setting.getStringWithDefault("name", "默认值");
//完整的带有key、分组和默认值的获得值得方法
setting.getStringWithDefault("name", "group1", "默认值");
//如果想获得其它类型的值,可以调用相应的getXXX方法,参数相似
//有时候需要在key对应value不存在的时候(没有这项设置的时候)告知用户,故有此方法打印一个debug日志
setting.getWithLog("name");
setting.getWithLog("name", "group1");
//重新读取配置文件,可以启用一个定时器调用此方法来定时更新配置
setting.reload();
//当通过代码加入新的键值对的时候,调用store会保存到文件,但是会覆盖原来的文件,并丢失注释
setting.setSetting("name1", "value");
setting.store("/home/looly/XXX.setting");
//获得所有分组名
setting.getGroups();
//将key-value映射为对象,原理是原理是调用对象对应的setXX方法
//setting.toObject();
//设定变量名的正则表达式。
//Setting的变量替换是通过正则查找替换的,如果Setting中的变量名和其他冲突,
//可以改变变量的定义方式
//整个正则匹配变量名,分组1匹配key的名字
setting.setVarRegex("//$//{(.*?)//}");
}
}
复制代码
对Properties的简单封装Props(版本2.0.0开始提供)
对于Properties的广泛使用使我也无能为力,有时候遇到Properties文件又想方便的读写也不容易,于是对Properties做了简单的封装,提供了方便的构造方法(与Setting一致),并提供了与Setting一致的getXXX方法来扩展Properties类,Props类继承自Properties,所以可以兼容Properties类,具体不再做介绍,有兴趣可以看下 cn.hutool.setting.dialect.Props
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/302407 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
14. Hutool-crypto模块
14.1 使用Hutool实现AES、DES加密解密
14.1.1 介绍
AES和DES同属对称加密算法,数据发信方将明文(原始数据)和加密密钥一起经过特殊加密算法处理后,使其变成复杂的加密密文发送出去。收信方收到密文后,若想解读原文,则需要使用加密用过的密钥及相同算法的逆算法对密文进行解密,才能使其恢复成可读明文。在对称加密算法中,使用的密钥只有一个,发收信双方都使用这个密钥对数据进行加密和解密,这就要求解密方事先必须知道加密密钥。
在Java世界中,AES、DES加密解密需要使用 Cipher对象 构建加密解密系统,Hutool中对这一对象做再包装,简化了加密解密过程。
14.1.2 引入Hutool
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.1.2</version>
</dependency>
复制代码
14.1.3 使用
** AES加密解密 String content = "test中文"; byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();//随机生成密钥 AES aes = SecureUtil.aes(key);//构建 byte[] encrypt = aes.encrypt(content);//加密 byte[] decrypt = aes.decrypt(encrypt);//解密 String encryptHex = aes.encryptHex(content);//加密为16进制表示 String decryptStr = aes.decryptStr(encryptHex);//解密为原字符串 ** DES加密解密, DES的使用方式与AES基本一致 String content = "test中文"; byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.DES.getValue()).getEncoded();//随机生成密钥 DES des = SecureUtil.des(key);//构建 byte[] encrypt = des.encrypt(content);//加密解密 byte[] decrypt = des.decrypt(encrypt); String encryptHex = des.encryptHex(content);//加密为16进制,解密为原字符串 String decryptStr = des.decryptStr(encryptHex); 复制代码
14.1.4 更多
Hutool中针对JDK支持的所有对称加密算法做了封装,封装为 SymmetricCrypto 类,AES和DES两个类是此类的简化表示。通过实例化这个类传入相应的算法枚举即可使用相同方法加密解密字符串或对象。
Hutool支持的对称加密算法枚举有:
AES ARCFOUR Blowfish DES DESede RC2 PBEWithMD5AndDES PBEWithSHA1AndDESede PBEWithSHA1AndRC2_40 复制代码
这些枚举全部在 SymmetricAlgorithm 中被列举
对称加密对象的使用也非常简单: String content = "test中文"; byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();//随机生成密钥 SymmetricCrypto aes = new SymmetricCrypto(SymmetricAlgorithm.AES, key);//构建 byte[] encrypt = aes.encrypt(content);//加密 byte[] decrypt = aes.decrypt(encrypt);//解密 String encryptHex = aes.encryptHex(content);//加密为16进制表示 String decryptStr = aes.decryptStr(encryptHex);//解密为字符串 复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/1504160 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
14.2 使用Hutool处理RSA等非对称加密
14.2.1 介绍
Hutool工具是一个国产开源Java工具集,旨在简化Java开发中繁琐的过程,Hutool-crypto模块便是针对JDK加密解密做了大大简化。
此文主要介绍利用Hutool-crypto简化非对称加密解密。
对于非对称加密,最常用的就是RSA和DSA,在Hutool中使用AsymmetricCrypto对象来负责加密解密。
非对称加密有公钥和私钥两个概念,私钥自己拥有,不能给别人,公钥公开。根据应用的不同,我们可以选择使用不同的密钥加密:
签名:使用私钥加密,公钥解密。用于让所有公钥所有者验证私钥所有者的身份并且用来防止私钥所有者发布的内容被篡改,
但是不用来保证内容不被他人获得。
加密:用公钥加密,私钥解密。用于向公钥所有者发布信息,这个信息可能被他人篡改,但是无法被他人获得。
复制代码
14.2.2 使用
14.2.2.1 引入Hutool
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.1.2</version>
</dependency>
复制代码
在非对称加密中,我们可以通过AsymmetricCrypto(AsymmetricAlgorithm algorithm)构造方法,通过传入不同的算法枚举,获得其加密解密器。
当然,为了方便,我们针对最常用的RSA和DSA算法构建了单独的对象:RSA和DSA。
14.2.2.2 基本使用
以RSA为例,介绍使用RSA加密和解密
在构建RSA对象时,可以传入公钥或私钥,当使用无参构造方法时,Hutool将自动生成随机的公钥私钥密钥对:
RSA rsa = new RSA();
rsa.getPrivateKey()//获得私钥
rsa.getPrivateKeyBase64()
rsa.getPublicKey()//获得公钥
rsa.getPublicKeyBase64()
byte[] encrypt = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa", CharsetUtil.CHARSET_UTF_8),
KeyType.PublicKey);//公钥加密,私钥解密
byte[] decrypt = rsa.decrypt(encrypt, KeyType.PrivateKey);
Assert.assertEquals("我是一段测试aaaa", StrUtil.str(decrypt, CharsetUtil.CHARSET_UTF_8));
//私钥加密,公钥解密
byte[] encrypt2 = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa", CharsetUtil.CHARSET_UTF_8), KeyType.PrivateKey);
byte[] decrypt2 = rsa.decrypt(encrypt2, KeyType.PublicKey);
Assert.assertEquals("我是一段测试aaaa", StrUtil.str(decrypt2, CharsetUtil.CHARSET_UTF_8));
复制代码
对于加密和解密可以完全分开,对于RSA对象,如果只使用公钥或私钥,另一个参数可以为null
14.2.2.3 自助生成密钥对
有时候想自助生成密钥对可以:
KeyPair pair = SecureUtil.generateKeyPair("RSA");
pair.getPrivate();
pair.getPublic();
复制代码
自助生成的密钥对是byte[]形式,我们可以使用Base64.encode方法转为Base64,便于存储为文本。
当然,如果使用RSA对象,也可以使用encryptStr和decryptStr加密解密为字符串
14.2.3 案例
已知私钥和密文,如何解密密文?
String PRIVATE_KEY = "MIICdQIBADANBgkqhkiG9w0BAQEFAASCAl8wggJbAgEAAoGBAIL7pbQ+5KKGYRhw7jE31hmA"
+ "f8Q60ybd+xZuRmuO5kOFBRqXGxKTQ9TfQI+aMW+0lw/kibKzaD/EKV91107xE384qOy6IcuBfaR5lv39OcoqNZ"
+ "5l+Dah5ABGnVkBP9fKOFhPgghBknTRo0/rZFGI6Q1UHXb+4atP++LNFlDymJcPAgMBAAECgYBammGb1alndta"
+ "xBmTtLLdveoBmp14p04D8mhkiC33iFKBcLUvvxGg2Vpuc+cbagyu/NZG+R/WDrlgEDUp6861M5BeFN0L9O4hz"
+ "GAEn8xyTE96f8sh4VlRmBOvVdwZqRO+ilkOM96+KL88A9RKdp8V2tna7TM6oI3LHDyf/JBoXaQJBAMcVN7fKlYP"
+ "Skzfh/yZzW2fmC0ZNg/qaW8Oa/wfDxlWjgnS0p/EKWZ8BxjR/d199L3i/KMaGdfpaWbYZLvYENqUCQQCobjsuCW"
+ "nlZhcWajjzpsSuy8/bICVEpUax1fUZ58Mq69CQXfaZemD9Ar4omzuEAAs2/uee3kt3AvCBaeq05NyjAkBme8SwB0iK"
+ "kLcaeGuJlq7CQIkjSrobIqUEf+CzVZPe+AorG+isS+Cw2w/2bHu+G0p5xSYvdH59P0+ZT0N+f9LFAkA6v3Ae56OrI"
+ "wfMhrJksfeKbIaMjNLS9b8JynIaXg9iCiyOHmgkMl5gAbPoH/ULXqSKwzBw5mJ2GW1gBlyaSfV3AkA/RJC+adIjsRGg"
+ "JOkiRjSmPpGv3FOhl9fsBPjupZBEIuoMWOC8GXK/73DHxwmfNmN7C9+sIi4RBcjEeQ5F5FHZ";
RSA rsa = new RSA(PRIVATE_KEY, null);
String a = "2707F9FD4288CEF302C972058712F24A5F3EC62C5A14AD2FC59DAB93503AA0FA17113A020EE4EA35EB53F"
+ "75F36564BA1DABAA20F3B90FD39315C30E68FE8A1803B36C29029B23EB612C06ACF3A34BE815074F5EB5AA3A"
+ "C0C8832EC42DA725B4E1C38EF4EA1B85904F8B10B2D62EA782B813229F9090E6F7394E42E6F44494BB8";
byte[] aByte = HexUtil.decodeHex(a);
byte[] decrypt = rsa.decrypt(aByte, KeyType.PrivateKey);
Assert.assertEquals("虎头闯杭州,多抬头看天,切勿只管种地", StrUtil.str(decrypt, CharsetUtil.CHARSET_UTF_8));
复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/1523094 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
15. Hutool-core模块
cn.hutool.core.bean 包下的DynaBean、BeanDesc、BeanDesc.PropDesc、BeanPath、BeanUtil
15.1、DynaBean:动态Bean,封装实例对象,进行反射调用
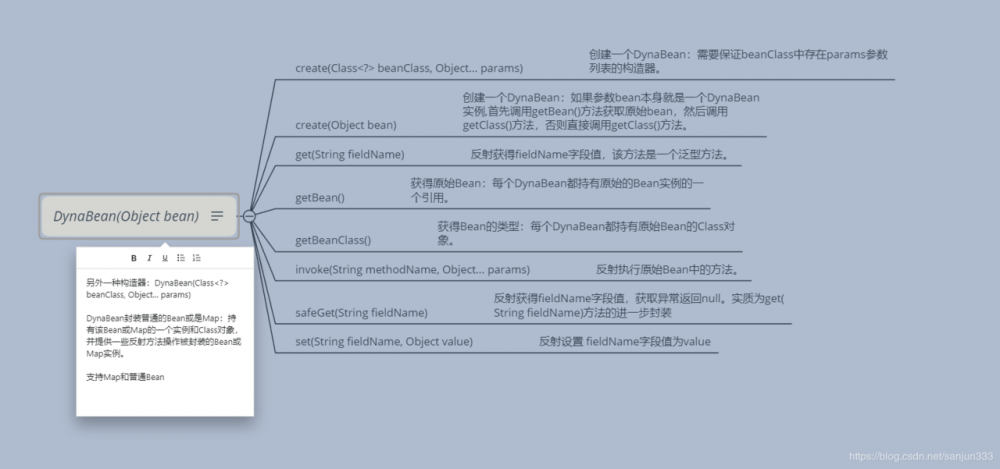
15.2、BeanDesc:Bean信息描述做为BeanInfo替代方案
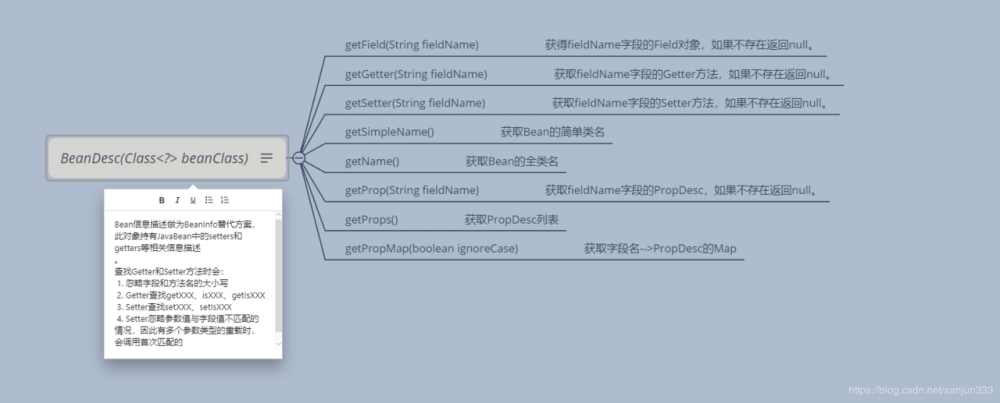
15.3、BeanDesc.PropDesc:属性描述

15.4、BeanPath:Bean路径表达式对象,用于属性检

15.5、BeanUtil:工具类

作者:豢龙先生 原文链接:https://blog.csdn.net/sanjun333/article/details/90645420 来源:CSDN 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
16. Hutool-http模块
使用Hutool爬取开源中国的开源资讯, 演示Hutool-http的http请求功能.
16.1 分析页面
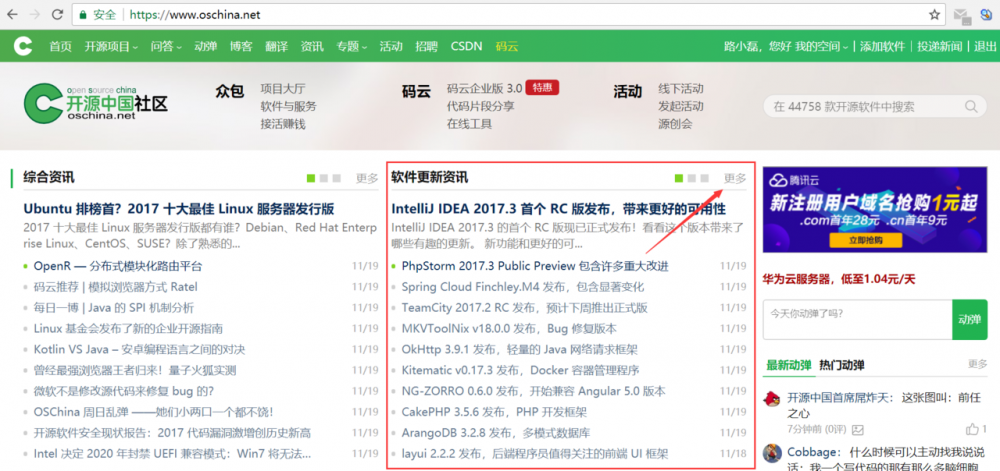
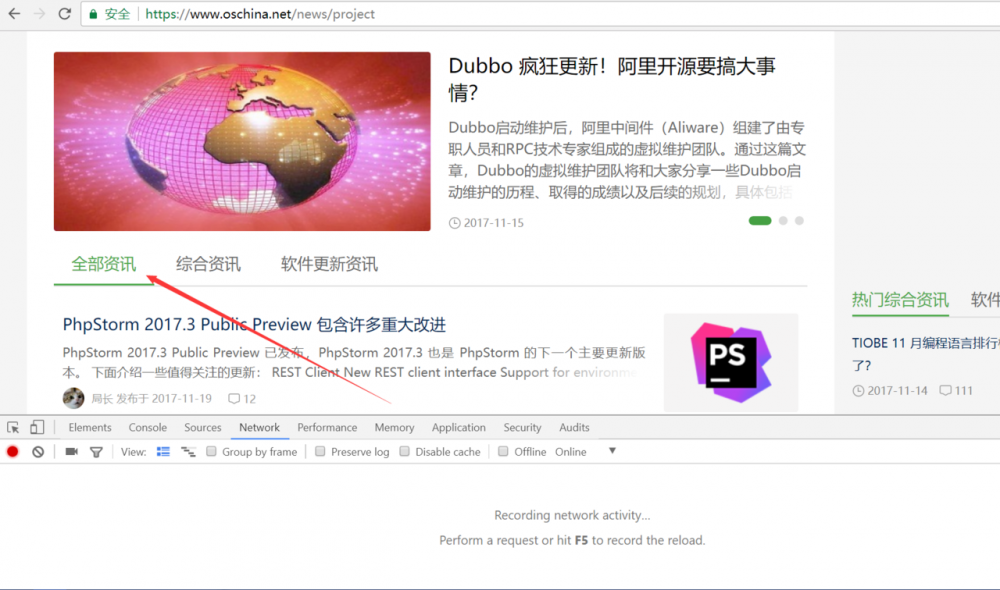
1.打开oschina的主页,我们找到最显眼的开源资讯模块,然后点击“更多”,打开“开源资讯”板块。
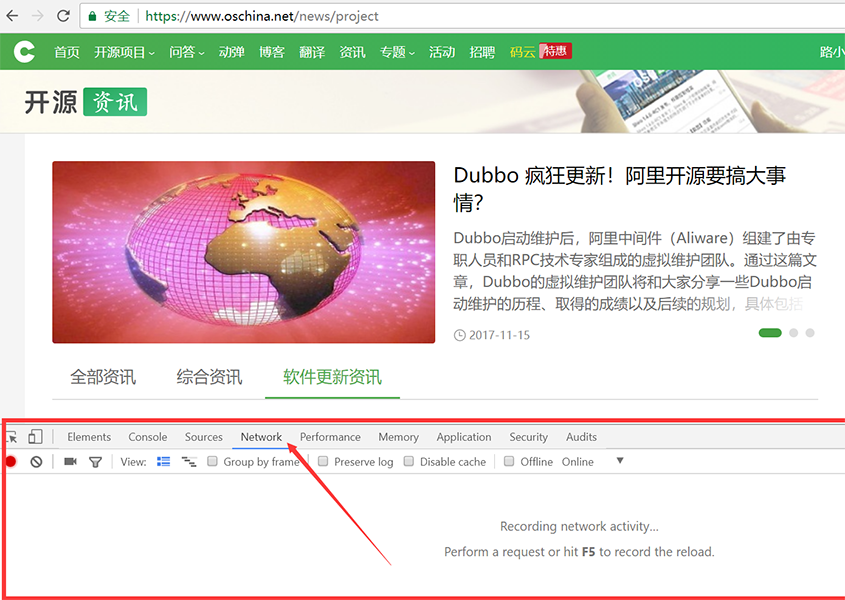
2.打开F12调试器,点击快捷键F12打开Chrome的调试器,点击“Network”选项卡,然后在页面上点击“全部资讯”。
3.由于oschina的列表页是通过下拉翻页的,因此下拉到底部会触发第二页的加载,此时我们下拉到底部,然后观察调试器中是否有新的请求出现。如图,我们发现第二个请求是列表页的第二页。
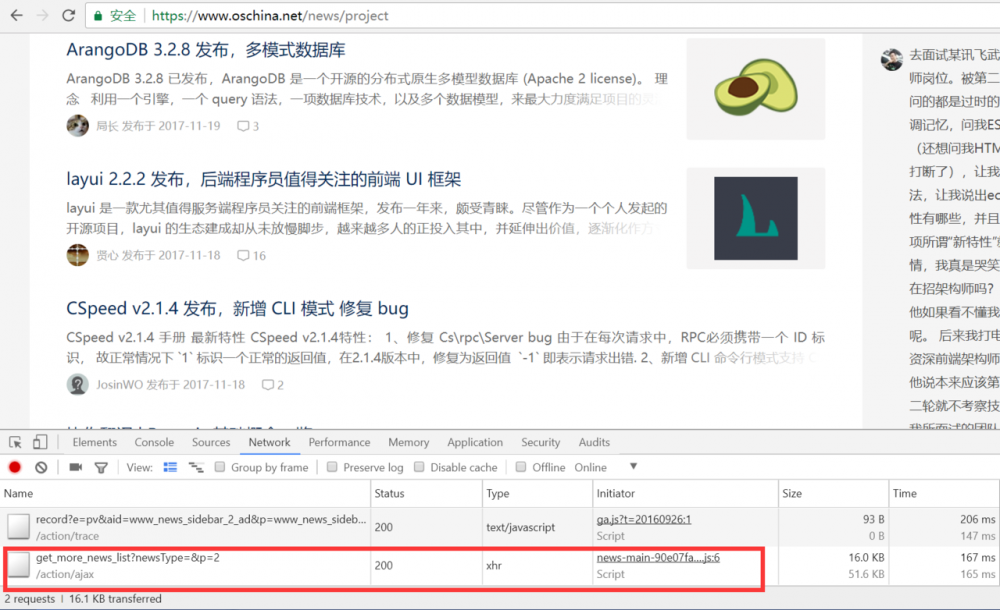
4.我们打开这个请求地址,可以看到纯纯的内容。红框所指地址为第二页的内容,很明显p参数代表了页码page。
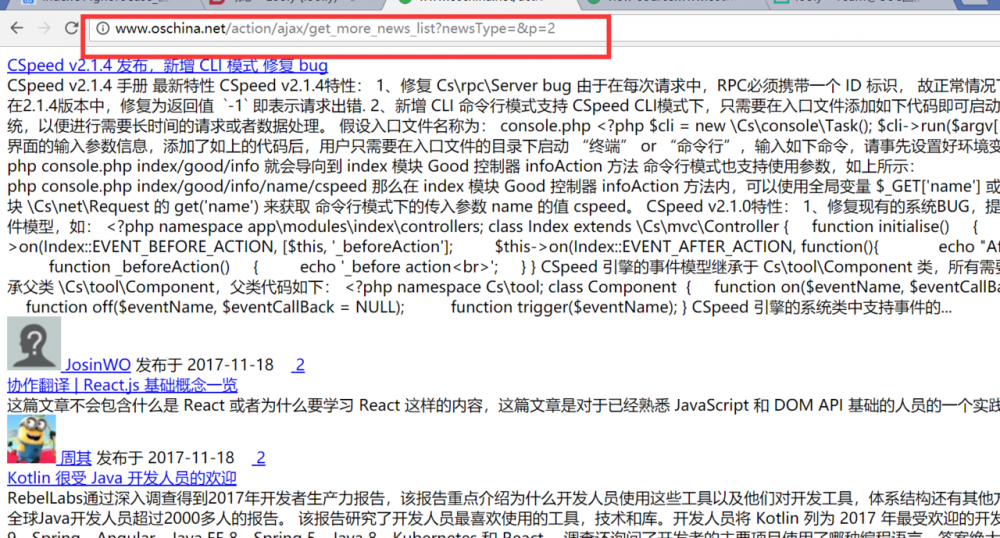
5.我们右键点击后查看源码,可以看到源码。
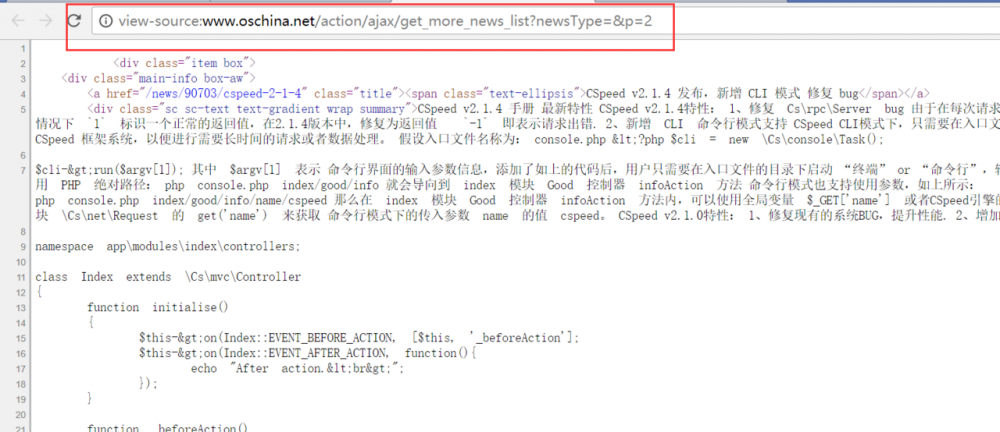
6.找到标题部门的HTML源码,然后搜索这个包围这个标题的HTML部分,看是否可以定位标题。
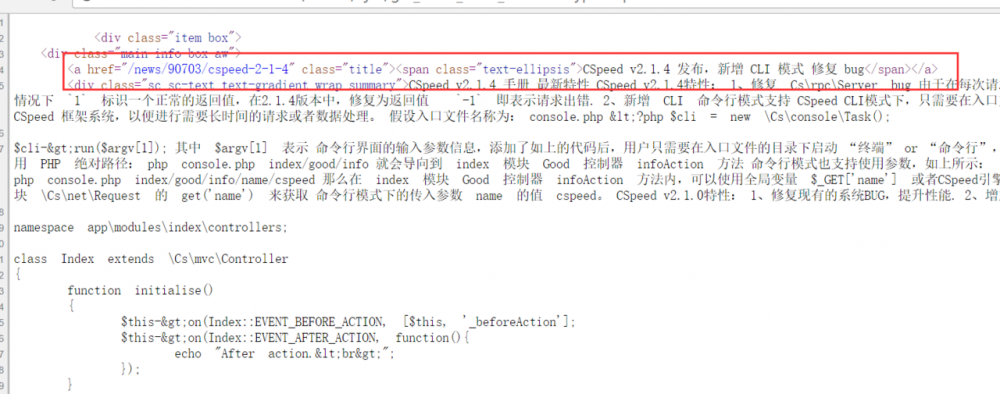
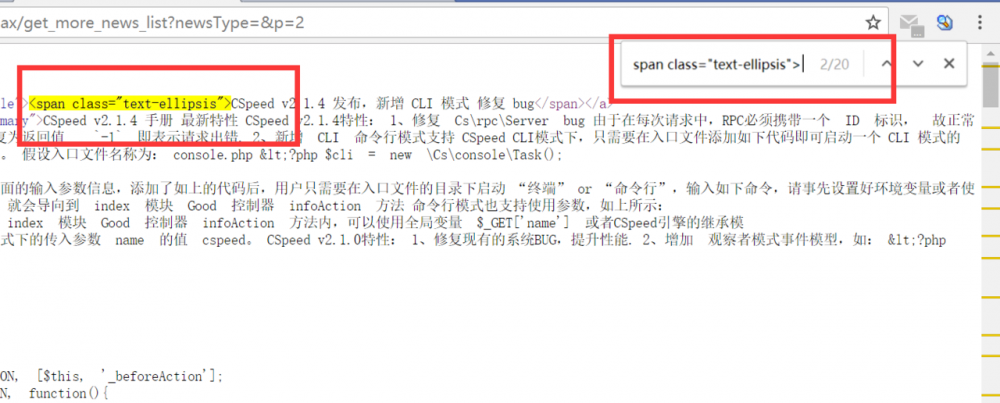
至此分析完毕,我们拿到了列表页的地址,也拿到了可以定位标题的相关字符(在后面用正则提取标题用),就可以开始使用Hutool编码了。
16.2 模拟Http请求爬取页面
使用Hutool-http配合ReUtil请求并提取页面内容非常简单,代码如下:
//请求列表页
String listContent = HttpUtil.get("http://www.oschina.net/action/ajax/get_more_news_list?newsType=&p=2");
//使用正则获取所有标题
List<String> titles = ReUtil.findAll("<span class=/"text-ellipsis/">(.*?)</span>", listContent, 1);
for (String title : titles) {
Console.log(title);//打印标题
}
第一行请求页面内容,第二行正则定位所有标题行并提取标题部分。
这里解释下正则部分:
ReUtil.findAll方法用于查找所有匹配正则表达式的内容部分,第二个参数1表示提取第一个括号(分组)中的内容,
0表示提取所有正则匹配到的内容。这个方法可以看下core模块中ReUtil章节了解详情。
<span class=/"text-ellipsis/">(.*?)</span>这个正则就是我们上面分析页面源码后得到的正则,
其中(.*?)表示我们需要的内容,.表示任意字符,*表示0个或多个,?表示最短匹配,整个正则的意思就是。
,以<span class=/"text-ellipsis/">开头,</span>结尾的中间所有字符,中间的字符要达到最短。
?的作用其实就是将范围限制到最小,不然</span>很可能匹配到后面去了。
复制代码
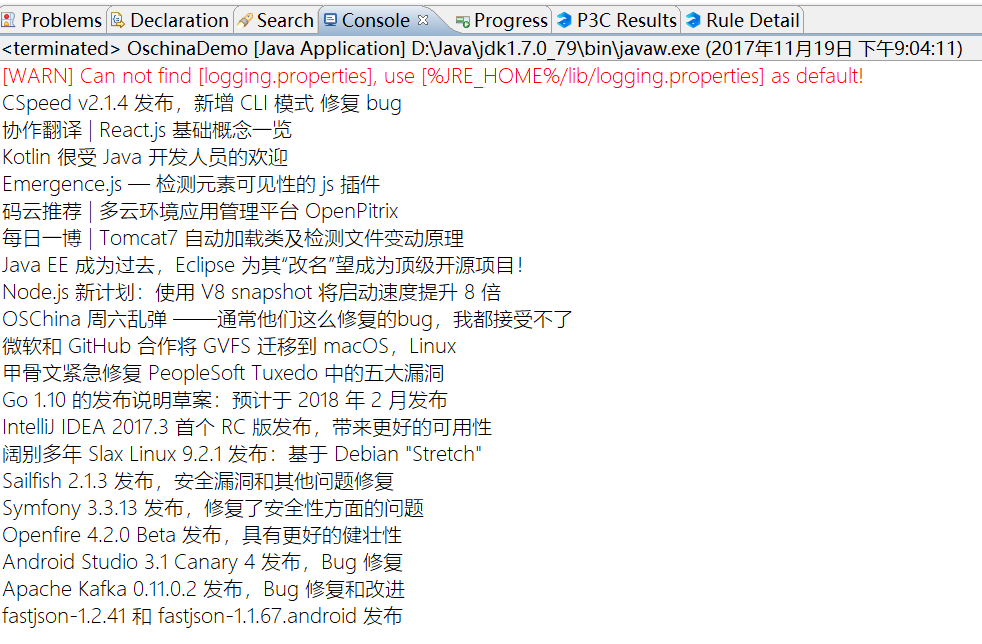
16.2 结语
不得不说,抓取本身并不困难,尤其配合Hutool会让这项工作变得更加简单快速,而其中的难点便是分析页面和定位我们需要的内容。
真正的内容抓取分为连个部分:
- 找到列表页(很多网站都没有一个总的列表页)
- 请求列表页,获取详情页地址
- 请求详情页并使用正则匹配我们需要的内容
- 入库或将内容保存为文件
而且在抓取过程中我们也会遇到各种问题,包括但不限于:
- 封IP
- 对请求Header有特殊要求
- 对Cookie有特殊要求
- 验证码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/1575851 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
17. Hutool之验证码工具——CaptchaUtil
使用Hutool [生成和验证] 图形验证码
17.1 由来
随着攻击防护做的越来越全面,而图形验证码又是一种简单有效的防攻击和防抓取手段,因此应用越来越广。而Hutool中抽象了验证码的实现,也提供了几个简单的验证码实现,从而大大减少服务端开发成本。
由于对验证码需求量巨大,且我之前项目中有所积累,因此在Hutool中加入验证码生成和校验功能。
17.2 引入Hutool
了解Hutool的更多信息请访问:http://hutool.cn/
<dependency>
<groupId>com.xiaoleilu</groupId>
<artifactId>hutool-all</artifactId>
<version>3.2.3</version>
</dependency>
复制代码
17.3 介绍
验证码功能位于 com.hutool.captcha 包中,核心接口为ICaptcha,此接口定义了以下方法:
createCode 创建验证码,实现类需同时生成随机验证码字符串和验证码图片
getCode 获取验证码的文字内容
verify 验证验证码是否正确,建议忽略大小写
write 将验证码写出到目标流中
复制代码
其中write方法只有一个OutputStream,ICaptcha实现类可以根据这个方法封装写出到文件等方法。
AbstractCaptcha为一个ICaptcha抽象实现类,此类实现了验证码文本生成、非大小写敏感的验证、写出到流和文件等方法,通过继承此抽象类只需实现createImage方法定义图形生成规则即可。
17.4 实现类
- LineCaptcha 线段干扰的验证码, 生成效果大致如下:
//定义图形验证码的长和宽
LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200, 100);
//LineCaptcha lineCaptcha = new LineCaptcha(200, 100, 4, 150);
//图形验证码写出,可以写出到文件,也可以写出到流
lineCaptcha.write("d:/line.png");
//验证图形验证码的有效性,返回boolean值
lineCaptcha.verify("1234");
复制代码
- CircleCaptcha 圆圈干扰验证码

//定义图形验证码的长、宽、验证码字符数、干扰元素个数
CircleCaptcha captcha = CaptchaUtil.createCircleCaptcha(200, 100, 4, 20);
//CircleCaptcha captcha = new CircleCaptcha(200, 100, 4, 20);
//图形验证码写出,可以写出到文件,也可以写出到流
captcha.write("d:/circle.png");
//验证图形验证码的有效性,返回boolean值
captcha.verify("1234");
复制代码
- ShearCaptcha 扭曲干扰验证码

//定义图形验证码的长、宽、验证码字符数、干扰线宽度
ShearCaptcha captcha = CaptchaUtil.createShearCaptcha(200, 100, 4, 4);
//ShearCaptcha captcha = new ShearCaptcha(200, 100, 4, 4);
//图形验证码写出,可以写出到文件,也可以写出到流
captcha.write("d:/shear.png");
//验证图形验证码的有效性,返回boolean值
captcha.verify("1234");
复制代码
- 写出到浏览器(Servlet输出)
ICaptcha captcha = ...; captcha.write(response.getOutputStream()); //Servlet的OutputStream记得自行关闭! 复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/1591079 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
18. 使用Hutool发送工作日报
18.1 使用到的模块和工具类
cron模块,用于定时发送邮件 extra模块,MailUtil,用于发送邮件 poi模块,WordWriter,用于生成日报的word 复制代码
18.2 项目结构
demo项目可以访问码云地址获取:https://gitee.com/loolly_admin/daily-work
src/main/java
cn/hutool/example/dailyWork/
DailyWorkGenerator.java ---- 日报生成器,用于生成Word文档
MailSendTask.java ---- 邮件发送任务,用于发送邮件
DailyWorkMain.java ---- 定时任务主程序,用于启动定时任务
src/main/resources
config/
cron.setting ---- 定时任务配置文件
mail.setting ---- 邮箱配置文件
复制代码
18.3 代码实现
1.生成日报Word
/** 标题字体 */
private static final Font TITLE_FONT = new Font("黑体", Font.PLAIN, 22);
/** 正文字体 */
private static final Font MAIN_FONT = new Font("宋体", Font.PLAIN, 14);
/**
* 生成日报
*
* @return 日报word文件
*/
public static File generate() {
// 1、准备文件
File wordFile = FileUtil.file(StrUtil.format("每日工作汇报_{}.docx", DateUtil.today()));
if(FileUtil.exist(wordFile)) {
// 如果文件存在,删除之(可能上次发送遗留)
wordFile.delete();
}
// 生成并写出word
Word07Writer writer = new Word07Writer(wordFile);
writer.addText(ParagraphAlignment.CENTER, TITLE_FONT, "工作日报");
writer.addText(MAIN_FONT, "");
writer.addText(MAIN_FONT, "尊敬的领导:");
writer.addText(MAIN_FONT, " 今天我在Hutool群里摸鱼,什么工作也没做。");
writer.close();
return wordFile;
}
复制代码
2.发送邮件在mail.setting中配置发件箱信息
# 发件人(必须正确,否则发送失败)
from = Hutool<hutool@yeah.net>
# 用户名(注意:如果使用foxmail邮箱,此处user为qq号)
user = hutool
# 密码
pass = XXXX
#使用 STARTTLS安全连接
startttlsEnable = true
#使用 SSL安全连接
sslEnable = true
=========================================================================
// 今天的日期,格式类似:2019-06-20
String today = DateUtil.today();
// 生成汇报Word
File dailyWorkDoc = DailyWorkGenerator.generate();
// 发送邮件
MailUtil.sendHtml("hutool@foxmail.com", StrUtil.format("{} 工作日报", today), "请见附件。", dailyWorkDoc);
StaticLog.debug("{} 工作日报已发送给领导!", today);
复制代码
3.定时发送,将刚才的发送邮件作为定时任务加入到配置文件:
[cn.hutool.example.dailyWork] # 每天下午6点定时发送 MailSendTask.execute = 00 00 18 * * * 复制代码
4.启动定时任务
// 设置秒匹配(只有在定时任务精确到秒的时候使用) CronUtil.setMatchSecond(true); // 启动定时任务,自动加载配置文件中的内容 CronUtil.start(); 复制代码
5.结果
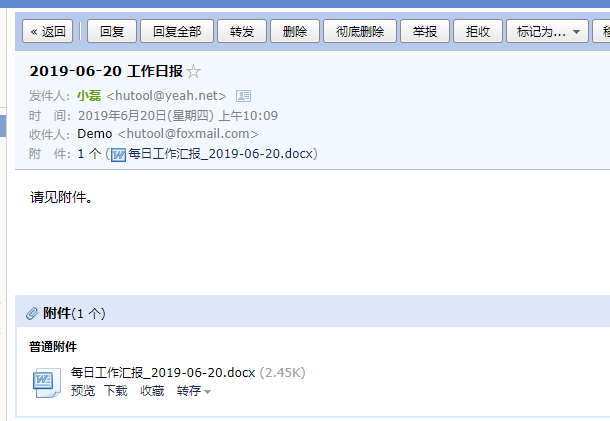
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/3064203 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
19. Hutool-log模块
19.1 Java日志框架分类
19.1.1 日志门面(Facade)
* Slf4j
全称Simple Logging Facade for JAVA,真正的日志门面,只提供接口方法,当配合特定的日志实现时,
需要引入相应的桥接包
* Common-logging
Apache提供的一个通用的日志接口,common-logging会通过动态查找的机制,在程序运行时自动找出真正
使用的日志库,自己也自带一个功能很弱的日志实现。
* 差别:
Common-logging 动态查找日志实现(程序运行时找出日志实现),
Slf4j 则是静态绑定(编译时找到实现),动态绑定因为依赖ClassLoader寻找和载入日志实现,因此类似于
OSGI那种使用独立ClassLoader就会造成无法使用的情况。
Slf4j 支持参数化的log字符串,避免了之前为了减少字符串拼接的性能损耗而不得不写的
if(logger.isDebugEnable()),现在可以直接写:logger.debug(“current user is: {}”, user)。
复制代码
19.1.2 日志实现
-
Log4j
Log4j可能是Java世界里最出名的日志框架了,支持各种目的地各种级别的日志输出。
-
LogBack
Log4j作者的又一力作(听说是受不了收费文档搞了个开源的,不需要桥接包完美适配Slf4j),感觉迄今为止最棒的日志框架了,一直都在用,配置文件够简洁,性能足够好。
JDK Logging 从JDK1.4开始引入,不得不说,你去Google下这个JDK自带的日志组件,并不如Log4j和LogBack之类好用,没有配置文件,日志级别不好理解,想顺心的用估计还得自己封装下,总之大家已经被Log4j惯坏了,JDK的设计并不能被大家认同,唯一的优点想就是不用引入新额jar包。
19.1.3 为什么会有门面
看了以上介绍,如果你不是混迹(深陷)Java多年的老手,估计会蒙圈儿了吧,那你肯定会问,要门面干嘛。有了手机就有手机壳、手机膜,框架也一样,门面的作用更多的还是三个字:解耦合。说白了,加入一个项目用了一个日志框架,想换咋整啊?那就一行一行的找日志改呗,想想都是噩梦。于是,门面出来了,门面说啦, 你用我的格式写日志,把日志想写哪儿写哪儿,例如Slf4j-api加上后,想换日志框架,直接把桥接包一换就行。方便极了。
说实话,现在Slf4j基本可以是Java日志的一个标准了,按照它写基本可以实现所有日志实现通吃,但是就有人不服,还写了门面的门面(没错,这个人就是我)。
19.1.4 门面的门面
如果看过Netty的源码,推荐你看下io.netty.util.internal.logging这个包里内容,会发现Netty又对日志封装了一层。
19.2 Hutool-log模块
无论是Netty的日志模块还是Hutool-log模块,思想类似于Common Logging,做动态日志实现查找,
然后找到相应的日志实现来写入日志,核心代码如下:
/**
* 决定日志实现
* @return 日志实现类
*/
public static Class<? extends AbstractLog> detectLog(){
List<Class<? extends AbstractLog>> logClassList = Arrays.asList(
Slf4jLog.class,
Log4jLog.class,
Log4j2Log.class,
ApacheCommonsLog.class,
JdkLog.class
);
for (Class<? extends AbstractLog> clazz : logClassList) {
try {
clazz.getConstructor(Class.class).newInstance(LogFactory.class).info("Use Log Framework: [{}]", clazz.getSimpleName());
return clazz;
} catch (Error | Exception e) {
continue;
}
}
return JdkLog.class;
}
复制代码
按顺序实例化相应的日志实现,如果实例化失败(一般是ClassNotFoundException),说明jar不存在,那实例化下一个,通过不停的尝试,最终如果没有引入日志框架,那使用JDK Logging(这个肯定会有的),当然这种方式也和Common-logging存在类似问题,不过不用到跨ClassLoader还是很好用的。
对于JDK Logging,也做了一些适配,使之可以与Slf4j的日志级别做对应,这样就将各个日志框架差异化降到最小。另一方面,如果你看过我的这篇日志,那你一定了解了我的类名自动识别功能,这样大家在复制类名的时候,就不用修改日志的那一行代码了,在所有类中,日志的初始化只有这一句:
Log log = LogFactory.get();
//=======实现方式 =======
/**
* @return 获得调用者的日志
* 通过堆栈引用获得当前类名。
*/
public static Log get() {
return getLog(new Exception().getStackTrace()[1].getClassName());
}
/**
* 日志统一接口
*/
public interface Log extends TraceLog, DebugLog, InfoLog, WarnLog, ErrorLog
这样就实现了单一使用,各个日志框架灵活引用的作用了。
复制代码
作者:路小磊 原文链接:https://my.oschina.net/looly/blog/543000 来源:oschina 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处 复制代码
=========================================================
正文到此结束
- 本文标签: 分页 root 图片 map example db 集合类 API JDBC CTO python git rand value java Property 网站 final 测试 希望 数据 代码 http servlet 字节码 Logback parse 正则表达式 Job tar mybatis web 自动生成 sql Ajax tab 乱码 管理 连接池 空间 ACE struct UTC key spring ODBC cat 锁 编译 MQ 调试 SDN ask mail equals stream 解析 linux 任务调度 插件 apache ORM 安全 开源 unix bug 领导 synchronized 注释 Word ip HashSet XML 目录 发送任务 线程 开发 ssl Collection UI core eclipse ArrayList Google 缓存 HTML Quartz js Chrome rsync bean 密钥 百度 源码 id IDE 时间 博客 shell 构造方法 加密 实例 云 queue 数据库 参数 服务器 IO 配置 src maven HashMap Netty Statement App kk https 2019 list zip Action 标题 总结 classpath 服务端 redis 需求 删除 VMware 静态方法 log4j2 DOM mysql Logging find
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐








相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

