消息队列的作用以及kafka和activemq的对比
背景分析
消息队列这个类型的组件一直是非常重要的组件,当经过两家企业后我就很坚信这个结论了。队列这种东西,最广泛的作用还是在于解耦,宽泛一点的说,它可以将不同部门的工作内容进行有效的整合,基于一个约定好的格式,就可以两头互相不干扰的进行开发。可以说这个生产消费的思想不仅仅适用于程序也适用于非常多的地方。
目前对于我看到的来说,kafka更多的还是做为一个数据源,数据桥梁的作用,不同业务之间的沟通。比如需要实时接入A部门的业务数据的话,就会有这样的手段:
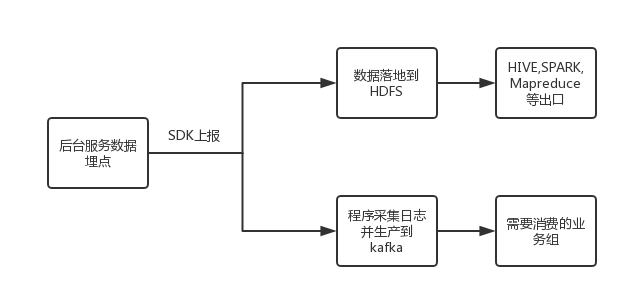
落地到HDFS的数据会用来进行一些算法上的离线处理,而kafka端则是给需要实时性的消费方。其实数据的消费方式无非也就实时和离线两种方式。
Kafka和activemq对比
相比过去经常使用的activemq,kafka确实非常的不同,做一个对比来深化印象
| 对比 | Activemq | Kafka |
|---|---|---|
| 接口协议 | 遵守JMS规范,各语言支持较好 | 没有遵循标准MQ接口协议,使用较为复杂 |
| 吞吐量 | 较低,磁盘随机读写 | 较高,磁盘顺序读写 |
| 游标位置 | AMQ来管理,无法读取历史数据 | 客户端自己管理,不乐意甚至重新读一遍也行 |
| HA机制 | 主从复制,竞争锁的方式来选举新的主节点 | 和hadoop系列产品一样,由zk管理所有节点 |
说到底,主要还是做为kafka的消费方,能感受到最大的不同还是在于几个:
-
吞吐量确实非常高
2.可以重读历史数据
但是也有一些缺点:
1.概念上比较复杂,相对于AMQ只需要知道ip和队列名你就能获得数据,Kafka使用起来非常繁琐
Kafka的基本概念(摘录)
1.Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
2.Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
3.Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
4.Segment:partition物理上由多个segment组成。
5.offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
Kafka消费端的常用参数
Properties props = new Properties();
//zk服务器的地址 xxxx:2181
props.put("zookeeper.connect", zookeeper);
//组的名称,区别于其他group否则会接收不到数据
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "8000");
props.put("zookeeper.connection.timeout.ms", "20000");
props.put("zookeeper.sync.time.ms", "2000");
props.put("auto.commit.interval.ms", "5000");
props.put("rebalance.max.retries", "5");
props.put("rebalance.backoff.ms", "60000");
props.put("auto.commit.enable", "true");
//重点参数,是否每次都从offset最前面开始读起
props.put("auto.offset.reset", "smallest");
Kafka的一些常用命令
查看所有的topic
bin/kafka-topics.sh --zookeeper zk1.test-inf-zk.data.m.com:2181/octopus,zk2.test-inf-zk.data.m.com:2181/octopus,zk3.test-inf-zk.data.m.com:2181/octopus --list
查看topic的偏移量
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic xiuxiu_sync_search_big_data --time -1 --broker-list 192.168.199.11:9092 --partitions 0
查看topic的状态
bin/kafka-topics.sh --zookeeper 192.168.199.11:2181 --topic xiuxiu_sync_search_big_data --descr
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

