一次超诡异的FGC,你之前肯定没碰到过的场景,快Get起来!
正撸着代码,内部聊天工具弹出一条信息: “ 我这个机器总是频繁FGC...快帮我看看 ”
我打开对话框,机智的回复一个表情:

继续默默撸码,代码是我的命,一日不撸,就蓝瘦。 随后,小伙伴砸了一段GC日志过来:
我这慧眼一瞧,看到了几个关键单词 FullGC 、 MetadataGCThreshold ,然后很随意的回复了
“ 是不是metaspace没有设置,或者设置太小,导致的FGC :sunglasses: ”
然后,又砸过来一段JVM参数配置
“ 应该不是,我们配置了
-XX:MaxMetaspaceSize=256m
-XX:MetaspaceSize=256m”
看到配置之后,有点懵逼,好像超出了我的认知范围,一下子没回复,又扔过来一堆数据。
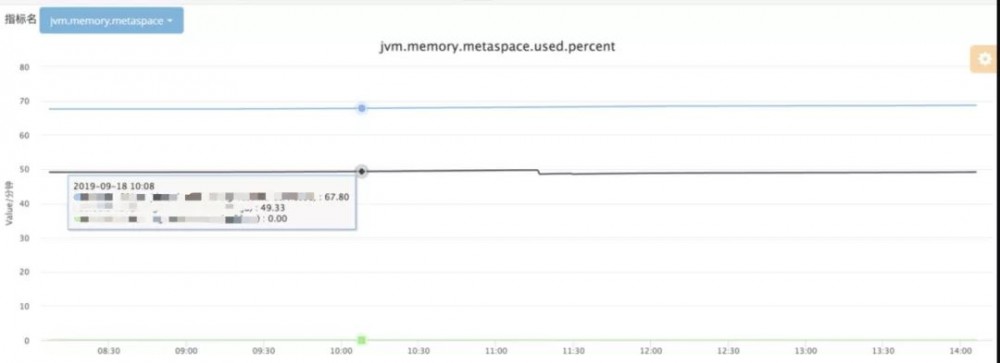
“看cat监控数据,Metaspace使用率在50%的时候就FGC了,GC 日志上的显示也只用了142M,可是我们明明设置了初始值是256M,最大值250M,这还没达到阈值 :tired_face:”
机智如我,赶紧回复 “等等,我空的时候再看看 :grimacing:”

等空闲下来,又想起了这个问题,决定好好研究下。
既然是Metadata GC Threshold引起的FGC,那么只可能是MetadataSpace使用完了,我又反复的看了下GC日志片段,盯着看了会
发生FGC之前,Metaspace的committed确实达到了256M,但是used却只有125M,难道某一次的类初始化需要大于256 - 125 = 131M?
这显然不合理,排除掉这种情况,那么只有一种解释了, Metaspace包含了太多了内存碎片,导致这256M中没有足够大的连续内存。
之前听过老年代因为CMS的标记清理会产生内存碎片导致FGC,为什么Metaspace也会有这样的问题?
让同事对有问题的机器dump了下,用mat打开之后,发现了新大陆,里面包含了大量的类加载器。
难道这个碎片问题是大量类加载器引起的?
本地验证
有了这个疑问,那就简单了,看看能不能在本地复现。
1、先定义一个自定义的类加载器,破坏双亲委派
2、然后在while循环中,不断的 load 已经编译好的class文件
3、最后,配置一下jvm启动参数
启动之后,不一会儿在控制台果然出现了日志
从日志可以看出来,发生FGC之前,used大概22M,committed已经达到100M,这时再加载class的时候,需要申请内存,就不够了,只能通过FGC对Metaspace的内存进行整理压缩。
到现在,我们已经验证了过多的类加载器确实可以引起FGC。
碎片是怎么产生的?
其实,JVM内部为了实现高效分配,在类加载器第一次加载类的时候,会在Metaspace分配一个独立的内存块,随后该类加载加载的类信息都保存在该内存块。但如果这个类加载器只加载了一个类或者少数类,那这块内存就被浪费了,如果类加载器又特别多,那内存碎片就产生了。

【相关阅读】
↓↓↓
PermSize&MetaspaceSize区别
【阿飞的博客】 公众号二维码
↓↓↓↓

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

