如何将 Redis 用于微服务通信的事件存储
来源:Redislabs
作者:Martin Forstner
翻译:Kevin (公众号:中间件小哥)
以我的经验,将某些应用拆分成更小的、松耦合的、可协同工作的独立逻辑业务服务会更易于构建和维护。这些服务(也被称为微服务)各自管理自己的技术栈,因此很容易独立于其他服务进行开发和部署。前人已经总结了很多关于使用这种架构设计的好处,在此我就不再赘述了。关于这种设计,有一个方面我一直在重点关注,因为如果没有它,将会导致一些有趣的挑战。虽然构建松耦合的微服务是一个非常轻量级和快速的开发过程,但是这些服务之间共享状态、事件以及数据的通信模型却不那么简单。我使用过的最简单的通信模型就是服务间直接通信,但是这种模型被 Fernando Dogio 明确地证明一旦服务规模扩大就会失效,会导致服务崩溃、重载逻辑以及负载增加等问题,从而可能引起的巨大麻烦,因此应该尽量避免使用这种模型。还有一些其他通信模型,比如通用的发布/订阅模型、复杂的 kafka 事件流模型等,但是最近我在使用 Redis 构建微服务间的通信模型。
拯救者 Redis!
微服务通过网络边界发布状态,为了跟踪这种状态,事件通常需要被保存在事件存储中。由于事件通常是一种异步写入操作的不可变流的记录(又被称为事务日志),因此适用于以下场景:
1. 顺序很重要(时间序列数据)
2. 丢失一个事件会导致错误状态
3. 回放状态在任何给定时间点都是已知的
4. 写操作简单且快捷
5. 读操作需要更多的时间,以至于需要缓存
6. 需要高可扩展性,服务之间都是解耦的,没有关联
使用 Redis,我始终可以轻松实现发布-订阅模式。但现在,Redis 5.0 提供了新的Streams 数据类型,我们可以以一种更加抽象的方式对日志数据结构进行建模-使之成为时间序列数据的理想用例(例如最多一次或最少一次传递语义的事务日志)。基于双主功能,轻松简单的部署以及内存中的超快速处理能力,Redis 流成为一种管理大规模微服务通信的必备工具。基本的模型被称为命令查询职责分离(CQRS),它将命令和查询分开执行,命令使用 HTTP 协议,而查询采用 RESP(Redis 序列化协议)。让我们使用一个例子来说明如何使用 Redis 作为事件存储。
OrderShop简单应用概述
我创建了一个简单但是通用的电子商务应用作为例子。当创建/删除客户、库存物品或订单时,使用 RESP 将事件异步传递到 CRM 服务,以管理 OrderShop 与当前和潜在客户的互动。像许多常见应用程序的需求一样,CRM 服务可以在运行时启动和停止,而不会影响其他微服务。这需要捕获在其停机期间发送给它的所有消息以进行后续处理。
下图展示了 9 个解耦的微服务的互连性,这些微服务使用由 Redis 流构建的事件存储进行服务间通信。他们通过侦听事件存储(即 Redis 实例)中特定事件流上的任何新创建的事件来执行此操作。
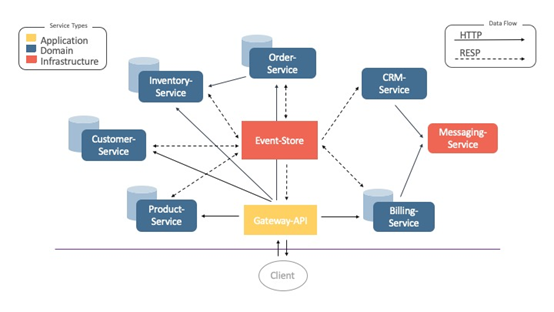
图1. OrderShop 架构
我们的 OrderShop 应用程序的域模型由以下 5 个实体组成:
- 顾客
- 产品
- 库存
- 订单
- 账单
通过侦听域事件并保持实体缓存为最新状态,事件存储的聚合功能仅需调用一次或在响应时调用。
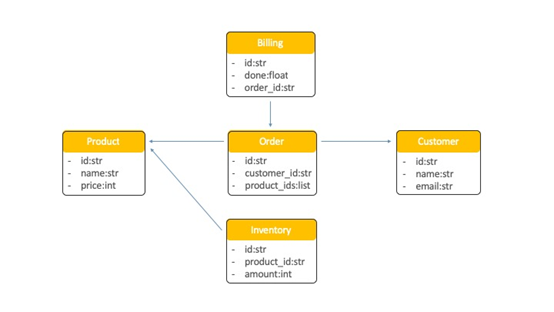
图2. OrderShop 域模型
安装并运行OrderShop
按照如下步骤安装并运行 OrderShop 应用:
1. 从这里下载代码仓库:
https://github.com/Redislabs-...
2. 确保已经安装了 Docker Engine和Docker Compose
3. 安装 Python3:
https://python-docs.readthedo...
4. 使用 docker-compose up启动应用程序
5. 使用 pip3 install -r client / requirements.txt 安装需求
6. 然后使用 python3 -m unittest client / client.py 执行客户端
7. 使用 docker-compose stop crm-service 停止 CRM 服务
8. 重新执行客户端,您会看到该应用程序正常运行,没有任何错误
深入了解
以下是来自 client.py 的一些简单测试用例,以及相应的 Redis 数据类型和键。
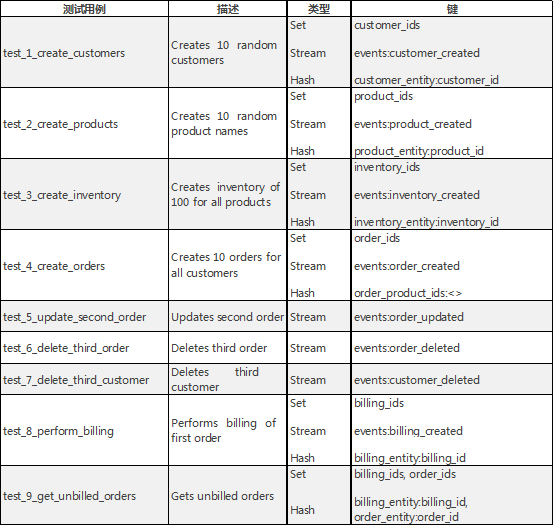
我选择流数据类型来保存这些事件,因为它们背后的抽象数据类型是事务日志,非常适合我们连续事件流的用例。我选择了不同的键来分配分区,并决定为每个流生成自己的条目 ID,ID 包含秒“-”微秒的时间戳(为了保持 ID 的唯一,并保留了键/分区之间事件的顺序)。我选择集合来存储 ID(UUID),并选择列表和哈希来对数据建模,因为它反映了它们的结构,并且实体缓存只是域模型的简单投影。
结论
Redis 提供的各种数据结构-包括集合,有序集合,哈希,列表,字符串,位数组,HyperLogLogs,地理空间索引以及现在的流-可以轻松适应任何数据模型。流包含的元素不仅是单个字符串,而且是由字段和值组成的对象。范围查询速度很快,并且流中的每个条目都有一个 ID,这是一个逻辑偏移量。流提供了针对时间序列等应用的解决方案,并可为其他应用提供流消息,例如,替换需要更高可靠性的通用发布/ 订阅应用程序,以及其他全新的应用。
您可以通过分片(聚集多个实例)来扩展 Redis 实例并提供容灾恢复的持久性选项,所以 Redis 可以作为企业级应用的选择。
更多优质中间件技术资讯/原创/翻译文章/资料/干货,请关注“中间件小哥”公众号!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

