JVM 虚拟机创建对象的过程分析(二)

JVM 虚拟机创建对象的过程分析(一)
 C1中的分配
C1中的分配
为了进一步挖掘了资源,让我们看看在快速,慢速和非常慢时如何分配TLAB。
已经有一个类不能执行,你需要研究operatornew正在编译什么。为此,我们有必要来看一下客户端编译器代码(C1):它比服务器编译器更简单,更易懂,而且由于Java中的新事物非常流行,其中有足够的优化。
我们对两种方法感兴趣:
C1_MacroAssembler :: allocate_object
, which describes the object allocation in TLAB and initialization and
Runtime1 :: generate_code_for
当无法快速分配内存时执行该命令,有趣的是,是否可以始终快速创建对象,并且“查找用法”链将我们引到instanceKlass.hpp中的此类注释:
// This bit is initialized in classFileParser.cpp.<br data-filtered="filtered">
// It is false under any of the following conditions:<br data-filtered="filtered">
// - the class is abstract (including any interface)<br data-filtered="filtered">
// - the class has a finalizer (if !RegisterFinalizersAtInit)<br data-filtered="filtered">
// - the class size is larger than FastAllocateSizeLimit<br data-filtered="filtered">
// - the class is java/lang/Class, which cannot be allocated directly<br data-filtered="filtered">
bool can_be_fastpath_allocated() const {<br data-filtered="filtered">
return !layout_helper_needs_slow_path(layout_helper());<br data-filtered="filtered">
}
很明显,非常大的对象(默认情况下超过128 KB)和可终结类始终在JVM中经过缓慢的调用。让我们把这个记下来,继续回到分配过程。
tlab_allocate是一种尝试快速分配对象的尝试,该对象正是我们查看PrintAssembly时看到的代码。如果结果是这样,那么我们就结束分配并进入对象的初始化。
tlab_refill尝试分配一个新的TLAB,使用一个有趣的测试,该方法会决定是分配新的TLAB(丢弃旧的TLAB)还是直接在伊甸园中分配对象,而保留旧的TLAB:
// Retain tlab and allocate object in shared space if<br data-filtered="filtered">
// the amount free in the tlab is too large to discard.<br data-filtered="filtered">
cmpptr(t1, Address(thread_reg, in_bytes(JavaThread::tlab_refill_waste_limit_offset())));<br data-filtered="filtered">
jcc(Assembler::lessEqual, discard_tlab);
tlab_refill_waste_limit
鉴于TLAB大小的原因,我们并没有为了分配一个对象而牺牲它。默认情况下,它的值是当前TLAB大小的1.5%。当然,有-TLABRefillWasteFraction参数,它的突然值为64,并且该值本身被认为是TLAB的当前大小除以该值此参数。在每次缓慢分配时都会提高此限制,以避免在失败情况下降级,并在每个GC周期结束时重置此限制。另一个问题更少。
eden_allocation尝试在伊甸园中分配内存(对象或TLAB)。这个位置与TLAB中的分配非常相似。首先,我们会检查是否存在一个位置,如果存在,则使用cmpxchg的lock子句自动地删除内存,如果不存在,则保留慢速路径。 伊甸园中的分配不是没有等待时间的:如果两个线程尝试同时在伊甸园中分配某些内容,那么它们中的一个很有可能无法正常工作,因此必须重新进行所有重复。
 JVM调用
JVM调用
如果你无法在伊甸园中分配内存,则会调用JVM,这将导致我们进入InstanceKlass :: allocate_instance方法。在调用之前,需要完成许多辅助工作。首先就是为GC建立特殊的结构,并创建必要的框架以适合调用约定,因此操作起来并不很快。
因为涉及有很多代码,我只会给出一个大概的调用方案:首先,JVM会尝试通过特定的接口为当前的垃圾收集器分配内存。上面发生了调用链在此也会同样发生:首先尝试从TLAB进行分配,然后尝试从堆和对象创建中分配TLAB。
如果失败,则调用垃圾收集。此外,还涉及超出错误GC开销限制、各种关于GC的通知、日志和其他与分配无关的检查。
如果垃圾收集无济于事,那么就尝试直接分配给过去的代(行为取决于所选择的GC算法),如果失败,则会进行另一次组装并尝试创建该对象,如果失败,不起作用,然后最终抛出OutOfMemoryError。
成功创建对象后,将检查它是否可终结,如果是,则将对其进行注册,这包括调用Finalizer#register方法。我们想你也一直想知道为什么该类在标准库中,但从来没有明确使用?因为该方法本身是在很久以前编写的,在全局(sic!)Lock将它添加到链表中,通过该方法,稍后将最终确定和收集对象。这完全证明JVM中的无条件调用是正确的,并且这完全证明了在JVM中进行无条件调用的合理性,并且即使你确实愿意,也不要使用Finalizer#register方法。
至此,我们现在几乎知道了所有关于分配的事情:对象分配迅速,TLAB快速填充,在某些情况下,对象在伊甸园中立即分配,并且在某些情况下,它们通过JVM中的非紧急调用。
 慢速分配
慢速分配
分配内存后,你有没有想过,如何处理此信息呢?
在上面的某个地方,我写道,所有统计信息(缓慢的分配,平均重新填充次数,分配流的数量,内部碎片的丢失)都记录在某处。
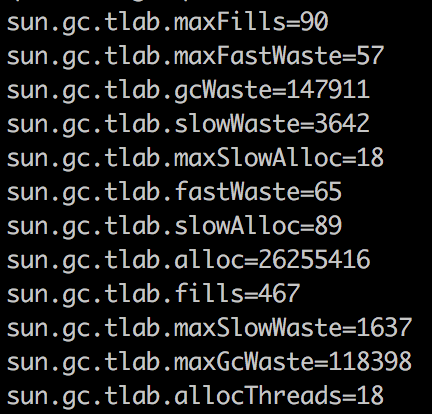
性能数据,最终会被存放在hsperfdata文件中,你可以使用jcmd或通过sun.jvmstat.monitor API进行编程来查看它。
没有其他方法可以获取此类信息,但是,如果你使用Oracle JDK,则JFR可以显示它(使用OpenJDK中不可用的私有API),并立即在堆栈跟踪部分中显示它。
这非常重要吗?在大多数情况下,很可能不是。但也有例外情况,例如,Twitter JVM团队提供了一份报告,在该报告中,缓慢的分配和扭曲必要的参数使他们能够将服务的响应时间减少百分之几。
 数据预取(Prefetch)
数据预取(Prefetch)
在我们遍历代码时,会定期弹出一些数据预取的检查,我人为地忽略了这些检查。Prefetch是预读取文件夹,用来存放系统已访问过的文件的预读信息,扩展名为PF。之所以自动创建Prefetch文件夹,是为了加快系统启动的进程。
数据预取是一种提高性能的技术,利用在这种技术中,我们可能很快就会将数据加载到处理器的缓存中。在hotspot中,数据预取是C2特定的优化,因此我们在C1代码中没有提到它。优化如下:在TLAB中进行分配时,将生成一条指令,该指令会将内存加载到高速缓存中,该高速缓存位于所分配的对象的后面。平均而言,Java应用程序会分配大量内存,因此,事先为后续分配加载内存似乎是个好主意。而下次创建对象时,我们不必等待,因为它已经存在缓存中了。
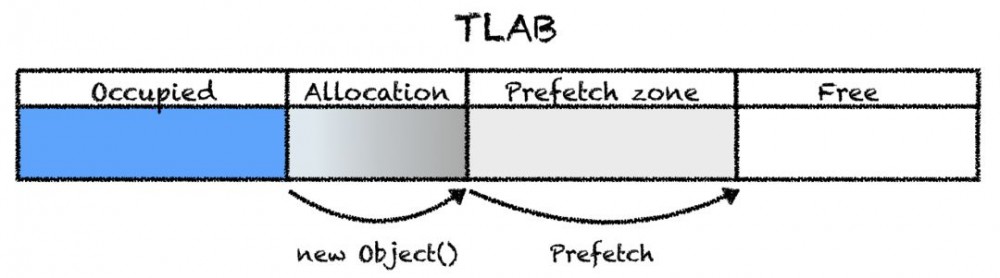
数据预取具有几种由AllocatePrefetchStyle标志控制的模式:你可以在每次分配后进行数据预取,有时可以在每次分配后进行多次。另外,AllocatePrefetchInstr标志允许你更改执行此数据预取的指令:你只能将数据加载到L1缓存中(例如,当你分配某些内容并立即丢弃它时),只能在L3中或一次全部加载:选项列表取决于处理器体系结构,并且标志和指令的对应值可以在中找到。所需架构的广告文件。
几乎总是不建议在生产中使用这些标志,除非你突然发现JVM工程师试图在SPECjbb基准上超越竞争对手,在Java上写出性能极高的东西,并且所有更改都通过可重复的测量得到证实(那么你可能不会读到这个地方,因为你已经了解了一切)。
 初始化
初始化
随着内存的分配,一切都被清除,剩下的只是在调用构造函数之前找出对象的初始化由什么组成。我们将在同一个C1编译器中看到所有内容,但是这次在ARM上有更简单的代码。
调用所需的方法称为C1_MacroAssembler :: initialize_object,而且不是很复杂:首先,该对象设置有标头,Mark Word(标记字)由两部分组成。其中包含有关锁,标识哈希码(或有偏锁)和垃圾收集的信息,以及指向对象类的klass指针,该对象类与元空间中的本机类表示相同,并且可以从中获取java.lang.Class。
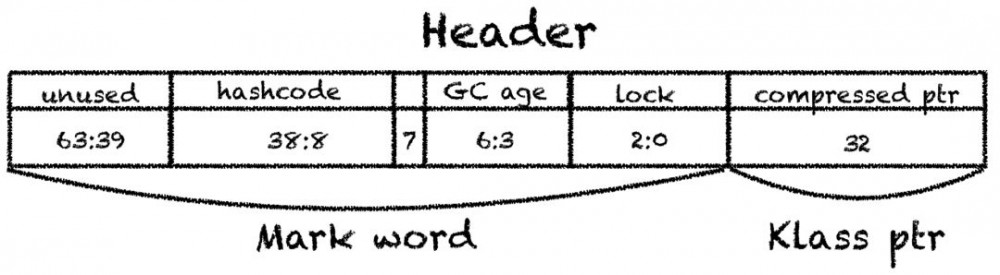
指向该类的指针通常经过压缩,占用32位而不是64位。事实证明,对象的最小可能大小是12字节(加上强制对齐,此数字将增加到16个)。
如果未启用ZeroTLAB标志,则清除所有内存。默认情况下,它始终处于关闭状态:
因为,将大内存区域归零会导致缓存的大量溢出,用很快就会被覆盖的小部件使内存无效更有效。此外,聪明的c2编译器不能做不必要的工作,也不会使内存无效。
最后,放置StoreStore屏障,该屏障会禁止处理器继续进入,直到当前处理器耗尽为止。
// StoreStore barrier required after complete initialization<br data-filtered="filtered">
// (headers + content zeroing), before the object may escape.<br data-filtered="filtered">
membar(MacroAssembler::StoreStore, tmp1);
这对于对象的不安全发布是必需的,如果代码中有错误,并且对象在某个位置发布,那么你仍然希望在其字段中看到默认值,但不是随机的值和虚拟机预计正确的标头。x86具有更强大的内存模型,并且那里不需要此指令,因此我们研究了ARM。
 实际测试
实际测试
当心上面代码中的错误,因为我只是从理论上证明它是正确的,并没有实际测试过。
到目前为止,一切看起来都不错:他们已经模拟了源代码,发现了一些有趣的时刻,但是实际上编译器所做的还不够,也许我们根本没有看过它,而且一切都徒劳。将其检回到toPrintAssembly,并完全查看生成的代码以调用新的Long(1023):
0x0000000105eb7b3e: mov 0x60(%r15),%rax<br data-filtered="filtered">
0x0000000105eb7b42: mov %rax,%r10<br data-filtered="filtered">
0x0000000105eb7b45: add $ 0x18,% r10; Allotsiruem 24 bytes: 8 byte header,<br data-filtered="filtered">
; 4 bytes pointer to a class,<br data-filtered="filtered">
; 4 bytes for alignment,<br data-filtered="filtered">
; 8 bytes on a long field<br data-filtered="filtered">
0x0000000105eb7b49: cmp 0x70(%r15),%r10<br data-filtered="filtered">
0x0000000105eb7b4d: jae 0x0000000105eb7bb5<br data-filtered="filtered">
0x0000000105eb7b4f: mov %r10,0x60(%r15) <br data-filtered="filtered">
0x0000000105eb7b53: prefetchnta 0xc0(%r10) ; prefetch<br data-filtered="filtered">
0x0000000105eb7b5b: movq $ 0x1, (% rax); Set the title<br data-filtered="filtered">
0x0000000105eb7b62: movl $ 0xf80022ab, 0x8 (% rax); We set the pointer to the Long class<br data-filtered="filtered">
0x0000000105eb7b69: mov %r12d,0xc(%rax) <br data-filtered="filtered">
0x0000000105eb7b6d: movq $ 0x3ff, 0x10 (% rax); We put 1023 in the object field
它看起来完全符合我们的预期,非常好。
总而言之,创建新对象的过程如下:尝试在TLAB中分配对象,如果TLAB中没有空间,则可以使用原子指令从伊甸园分配新的TLAB或直接在伊甸园中创建对象。如果伊甸园中没有地方,那么将进行垃圾收集。如果之后没有足够的空间,则尝试在以前的空间中进行分配。如果它不起作用,那么会出现OOM抛出,OOM为out of memory的简称,称之为内存溢出。
该对象设置有标头,然后调用构造函数。
至此,我们已经知道了如何创建对象以及可以控制该过程的标志,是时候在实践中进行检查了。让我们编写一个简单的基准测试,该基准测试仅在多个线程中创建java.lang.Object,并旋转JVM选项。
测试在Java 1.8.0_121,Debian 3.16,Intel Xeon X5675上运行,在横坐标轴上——沿着纵坐标的流的数量——一微秒内分配的数量。
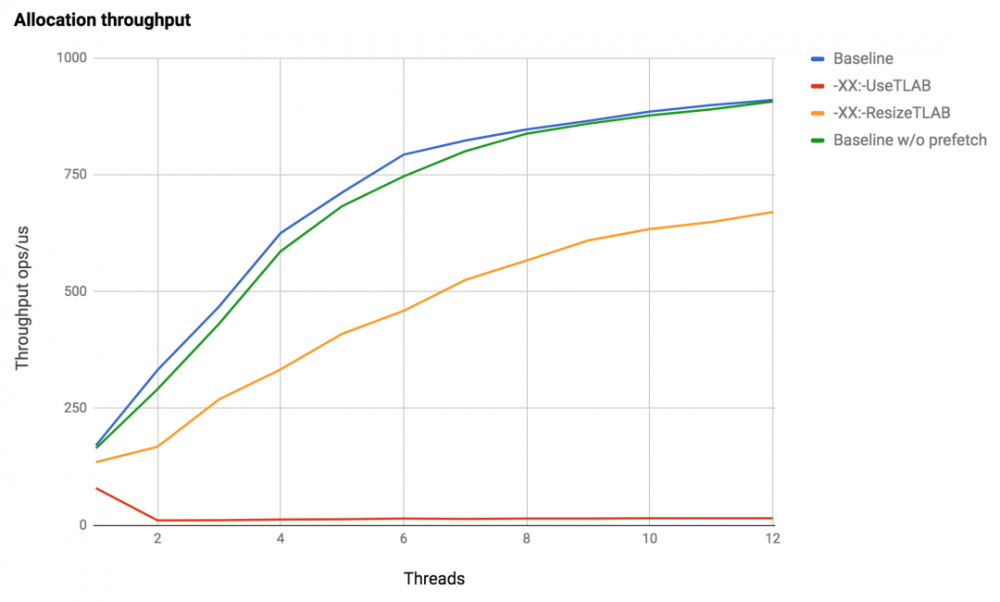
事实证明,这是非常令人期待的:默认情况下,分配的速度几乎是线性增长的,这取决于线程的数量,这正是我们对新线程的期望。随着线程数量的增加,情况会变得更糟,但这并不奇怪。如果在两次分配之间进行一些有用的工作(例如,使用Blakehole#消耗CPU),那么分配之间的重叠将会减少,并且增长率将恢复到线性。关闭数据预取会使分配速度变慢,在我们的基准测试中,我们只是使JVM重载了分配,而在实际应用程序中,一切都可能大不相同。因此,我们不会就此优化的好处得出任何结论。
关闭TLAB分配后,一切都会变得非常糟糕:一个线程相差两次半的调用JIT-> JVM的成本,并且随着线程数量的增加,对单个指针的竞争只会增加。
最后,关于finalize的好处,比较伊甸园的分配和finalizable-objects的分配。
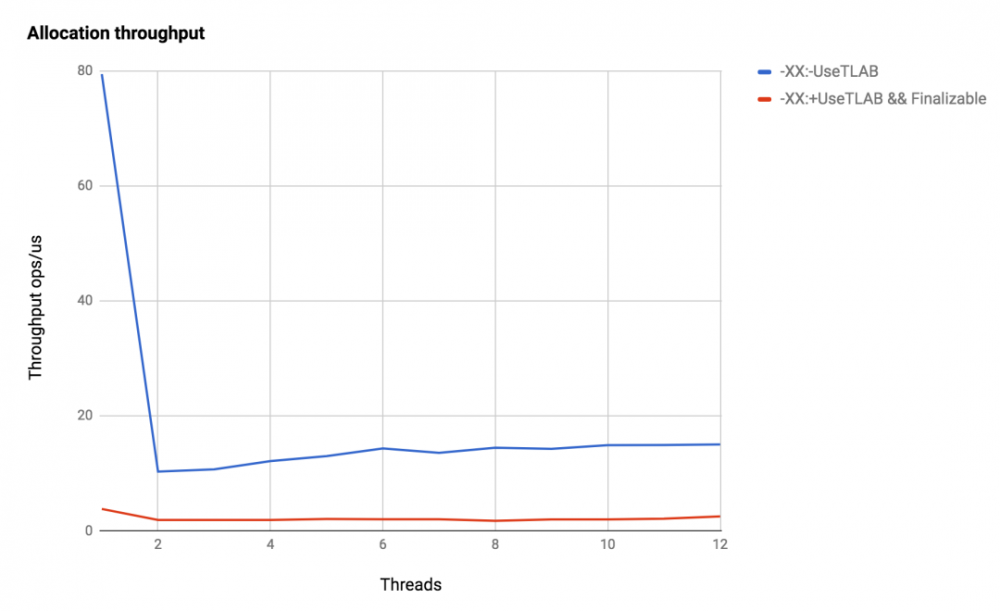
与快速分配相比,性能下降了一个到两个数量级!
 总结
总结
为了尽可能快速、轻松地创建新对象,JVM做了很多事情,而TLAB是它提供新对象的主要机制。 TLAB本身只有通过与垃圾收集器的密切合作才有可能,将释放内存的责任转移给它,分配几乎变得自由了。
参考来源: https://umumble.com/blogs/java/how-does-jvm-allocate-objects%3F/


正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

