让剁手更便捷,蘑菇街视觉搜索技术架构实践
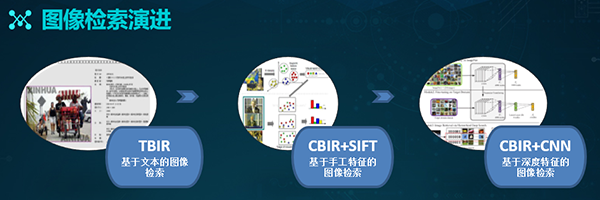
【51CTO.com原创稿件】众所周知,图像检索属于计算机视觉领域被研究得较早、且较为广泛的方向。按照描述图像内容方式的不同,一般可以分为两大类:基于文本的图像检索(TBIR)和基于内容的图像检索(CBIR)。
2018 年 11 月 30 日-12 月 1 日,由 51CTO 主办的 WOT 全球人工智能技术峰会在北京粤财 JW 万豪酒店隆重举行。
本次峰会以人工智能为主题,来自于美丽联合集团的宋宏亮给大家介绍《视觉搜索技术系统与业务应用》。
本次分享将从如下三个部分展开:
- 视觉分享的背景与现状
- 蘑菇街视觉搜索技术架构与研发
- 系统及业务应用
视觉分享的背景与现状
基于文本的图像检索方法始于上世纪70年代,它利用文本标注的方式对图像中的内容进行描述,从而为每张图像产生内容描述的关键词,包括图像中的物体和场景等。
这种方式既可以采用人工标注,也可以通过图像识别技术,来实现半自动化的标注。在检索时,系统可以根据用户所提供的查询关键字,找出那些与关键字相对应的图片,并返回给用户。
由于具有易于实现的优点,因此在一些中小型规模的图像搜索应用中,该方法仍在被继续使用着。
当然,该方式也存在着如下缺陷:
- 对于大规模的图像数据而言,由于在标注过程中需要有人工的介入,因此不但耗时耗力,而且持续涌入的新图像也会干扰到人工标注。
- 在需要精确查询时,用户可能很难用简短的关键字,来描述出自己真正想要获取的图像。
- 人工标注的过程,不可避免地会受到标注者的认知水平、言语使用、以及主观判断等方面的影响,因此会产生文字描述的差异性。
随着图像数据的快速增长,上述针对基于文本检索方法的问题日益凸现。因此,业界普遍认为:索引图像信息的最有效方式应该基于图像内容自身。
此类方式是将对于图像内容的表达和相似性,交给计算机自行处理,充分发挥其计算优势,并大幅提升检索的效率。
不过,基于内容检索方法也存在着一项主要缺点:特征描述与高层语义之间存在着难以填补的鸿沟。
由于受到环境的干扰较大,因此我们需要选择那些抗干扰性较强的、具有不变性局部特征的方法,如SIFT。同时,我们也要求此类方法应具有较高的特征维度。
近年来,以深度学习(尤其是卷积神经网络CNN)为主的自动化图像特征检索方法,得以广泛应用。
它能够极大地提高检索的精度。而且,我们可以使用PCA等降维手段,来构建出高效合理的快速检索机制,以适应大规模或海量图像的检索任务。
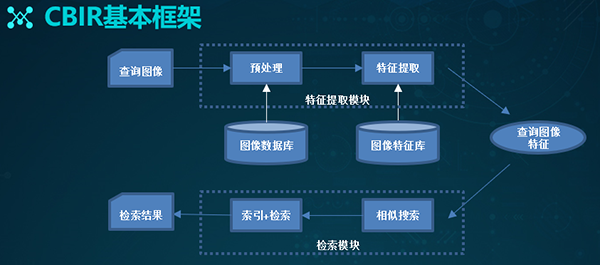
上图是基于内容图像检索的基本框架。我们可以事先建立好图像特征矢量的描述,并存入图像特征库中。
当用户输入一张待查询的图像时,它会使用相同的方法,提取待查询图像的特征,并得到查询的向量。
然后在某种相似性的度量准则下,计算查询向量与特征库中各个特征的相似性大小。最后按照相似性的大小进行排序,并顺次输出对应的图片。
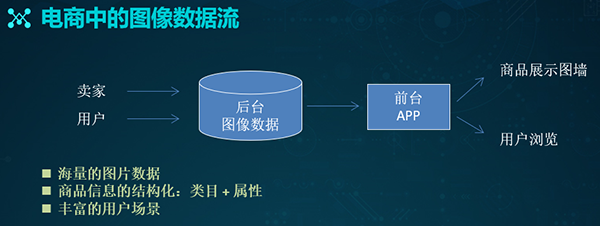
对于我们的电商场景而言,各种数据的来源一般分成两块:
- 卖家端:普通卖家,上传商品主图、附图、SKU图、以及各种详情图。主播,生产直播内容,包含商品截图和视频等。
- 用户端:普通用户,上传对应的UGC内容、以及买家秀图片等。达人,产生PGC之类的内容。
这些图像数据不但体量庞大,而且具有“天然”的结构化信息。商家在上传时,便能通过填写图片所对应的类目和属性,完成明晰的标注。
而有了基础的数据来源,我们就能通过构建后台图像数据库,来进行款式属性的识别,OCR文字的识别、以及图像特征的检索等操作。
在此基础上,结合各种运营活动与策略,我们就能够在前端将商品展现出去,对便用户进行浏览和购买。
众所周知,物体容易受拍摄环境的影响。比如:光照变化、尺度变化、视角变化、遮挡以及背景杂乱等因素,都会对检索结果造成较大的影响。
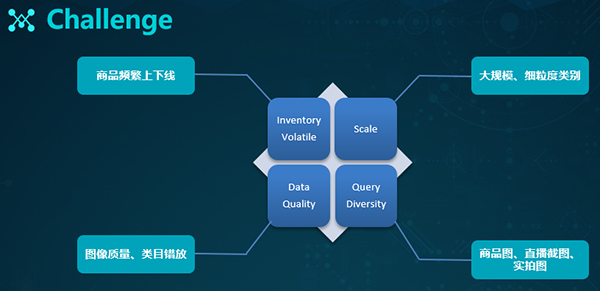
此外,电商还面临着来自如下方面的挑战:
- 电商平台每天都有频繁的上、下架商品,它们给索引的整体构建带来了巨大挑战。
- 规模是把双刃剑,虽然我们拥有了足够多的数据进行模型训练,但是庞大的数据也对整体搜索构成了巨大的压力。
- 数据质量无法保障,尤其是那些用户上传的各种买家show图片,以及商家打错类目标签的问题。
- 用户的查询也会存在着多样性,包括对于各种上传商品图、视频截图、以及实拍图的需求。
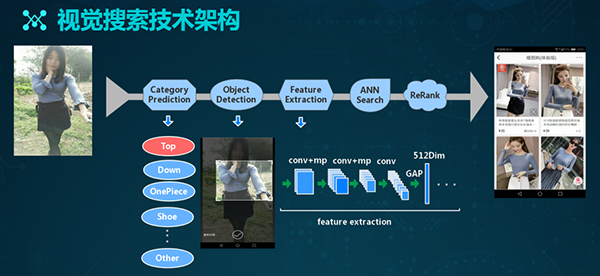
蘑菇街视觉搜索技术架构与研发
基于上面提到的数据特点与挑战,我们研发了自己的视觉搜索技术架构。如上图所示,其流程为:
- 在接到用户的查询请求之后,我们会对类目进行预测。
- 通过目标检测,我们得到所需的内容。
- 通过特征提取器,提取图像的特征表达。
- 基于ANN检索,得到充分的检索结果。
- 通过Rerank方式,得到检索的最终结果。
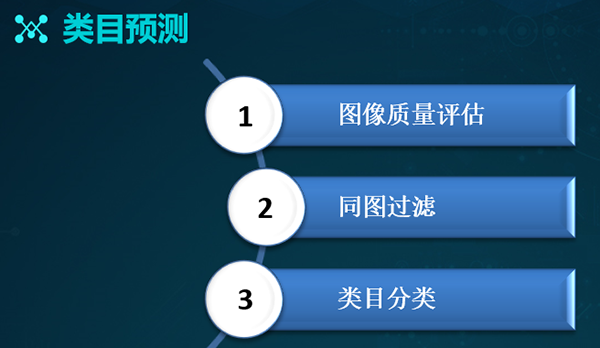
基于上述流程,我们来依次介绍其不同的环节。对于类目预测而言,我们分为三个方向:
- 由于输入数据较为杂乱,因此我们需要对图像进行质量评估,处理掉质量较差、或不宜于展示的图片,以提升用户的体验。
- 基于同图的过滤方式,处理掉数据库中的同图。
- 进行各种类目的分类工作。

图像质量评估
图像质量评估实际上是对图像美观度的识别。目前市面上的大部分图像质量分析,主要是在粗粒度层面上给出质量的分级,如:好的、中等的、差的。
因此,它们只是将问题归成了分类问题,并没有从细节上去模拟人类的审美,给出图像的优劣判定。
在此,我们借鉴了“Photo Aesthetics Ranking Network with Attributes and Content Adaptation”一文的思想,采用了文中提到的前两种网络结构。
首先,我们通过人工标注,从上图右侧所展示的多纬度属性方向去对数据进行打标,进而得出美观度的总体分值。接着,我们采用了单支和多分支两种回归网络。
单支回归网络训练的是一个回归模型的Reg,其lable为图片的总评分(score)。通过对某个图片上11个评分点的相加,构造出一个多分支,进而融合成一个得分制的回归网络Reg+Att。
在训练时,label的11个属性评分与最终的score,会将Reg所训练好的权重迁移到Reg+Att之中,并最终使用Reg+Att网络来进行预测。
有了该网络之后,我们便可以对于数据库中的图片数据进行美观度评分,进而过滤掉美观度分值较差的图片。
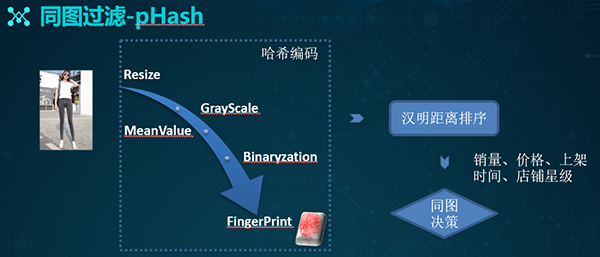
同图过滤
如果我们搜索出来的结果存在大量同图的话,势必会降低用户的体验度。因此,我们采用轻量化的pHash方式进行快速地同图过滤。
该方式的基本思想是:为每一张图片形成一个哈希值。整个计算过程为:
- 对一张图片进行resize,将其缩放成8×8的尺度,共有64个像素。
- 转成灰度图片,计算灰度平均值。
- 将每个像素的灰度值和平均值进行比较。如果是大于或者是等于该平均值,则记为1;若小于平均值,则记做0。
- 将这些0、1的结果进行串联,得到二进制的表达。
- 通过汉明距离进行距离计算,籍此判断是否为同一张图片。
- 结合包括销量、价格、上店时间、以及店铺星级在内的业务逻辑,进行同图的合并或过滤。
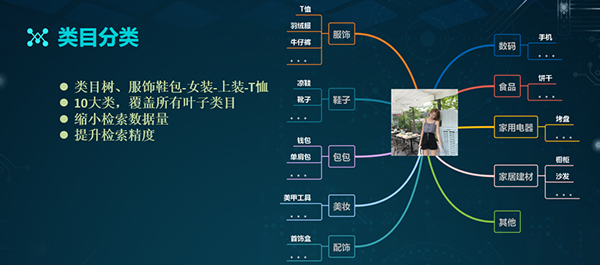
类目分类
类目分类的主要目的是缩小待检索的数据量,提升检索的精度。在电商的场景中,有着“类目数”的概念。例如:服饰鞋包、女装、上装、以及T恤,就构成了类目数的不同分支。
其中,服饰鞋包是一级类目,女装是二级类目,上装是三级类目,T恤则对应的是四级类目。如上图所示,我们针对于不同类目数的数据分布情况,以及用户对于类目的认知,整理出了上述十个大类,它们基本覆盖了我们系统中的所有叶子类目。
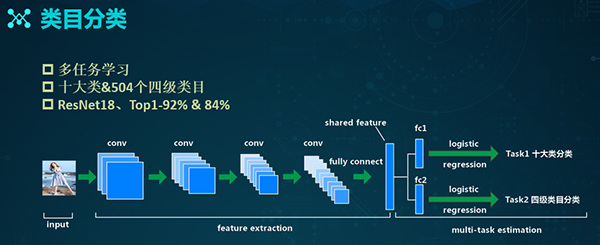
除了上述横向的十个大类,我们也结合了纵向的四级类目(共504个),以便在后续的结果召回上实现弥补。
同时,由于各个任务之间存在着相关性,因此我们采用的是基于多任务的学习方式,通过彼此之间的促进,让模型具有更好的泛化能力。
如上图所示,此处的底层网络是ResNet18,后面的两个FC分支分别对应着两个不同的具体任务。通过迭代,该模型的top1,在十大类层面上可达92%,而在四级类目上则为84%。
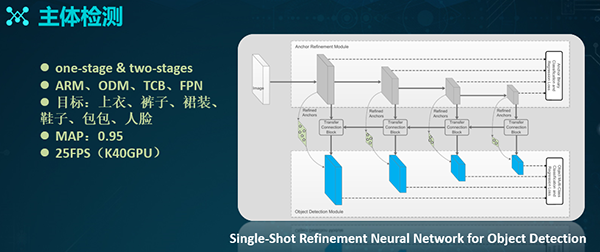
主体检测
对于一张图片,我们可以采用两种主流的目标检测方式:
- Faster R-CNN之类的two-stages的方式
- SSD之类的one-stage的方式
由于是基于RNN,因此two-stages方式的精度更高些;同时,由于是串联方式,所以其计算性能略差。而one-stage方式则恰恰与此相反。
鉴于两类方法的优缺点,最终我们采用了基于Refinement网络的模型训练。其中,Anchor refine module类似于Faster R-CNN中的RPN,而Object detect module则类似于SSD。中间通过TCB模块进行特征转换,将上层的ARM特征上传到某个检测模块中。
同时,TCB具有一个类似于FPN金字塔形式的向前传递过程。因此,该网络相当于将RPN与后面的检测模块并行处理,进而保证了检索的性能。
而且,由于接入了FPN的特定制,因此它对于一些小目标的检测来说,会有比较好的效果。
我们基于该网络也制定了一些检测目标,例如:我们会检测某张图片中出现的上服、裤子、裙装、鞋子、包包和人脸等区域部分。
通过迭代训练,我们最终可以达到0.95的MAP,而在K40上的检索性能则为25FPS,同时在P100上,会达到50多的FPS效果。

上面四张图展示的是我们在不同场景下目标检测的结果:第一张图来自商品搜索的结果;第二张图来自用户的实拍;第三张截图来自直播场景;最后一张图来自线下数据的实测情况。
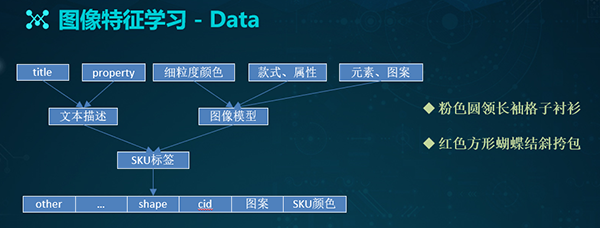
图像特征学习
针对在真实的电商场景中存在着图像特征提取的需求,我们整理出了一套多位的标签体系。其中包括:类目的CID、SKU的颜色、图像本身的图案信息、Shape信息、以及其他扩展信息。
虽然在制定标签时,我们难免要进行大量的数据清洗和整理工作,但是,由于商家在上传图片时,已经给商品打上了Title等属性信息,因此我们可以直接通过这些文本描述,来拿到一些“天然”的标签。
另外,我们也可以通过诸如:款式属性模型、元素图案模型、以及一些细粒度的颜色模型,来对这些数据进行重新打标或予以校验。
有了上述两方面的基础,我们再结合一些人工的审核方式,最后就能得出相对完善的标签。如上图的右侧两行文字所示,它们分别代表了标签的具体含义。
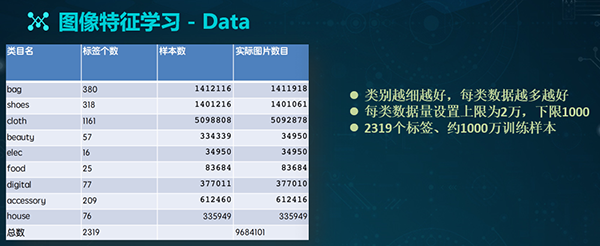
在标签体系建成之后,我们就可以开始整理数据了。一般而言,类别应当越细越好,每类的数据也是越多越好。
但是在实践中,我们需要将每一类数据的体量设置为:上限2万、下限1千,以避免出现样本不均衡的问题。因此,在整理完成后,我们最终得到了2319个标签、约1000万个训练样本。
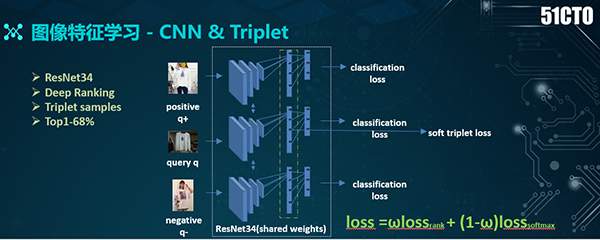
有了数据标签和可供训练的数据,下面我们便可以通过基于CNN网络的分类模型,来训练特征了。
为了得到更好的分类效果,我们引入了Triplet的网络结构。如上图所示,右侧图共有三个分支:中间为query、上面是positive、下面为negative。
而在最后,我们采用了两种loss:一种是分类的loss、另一种是基于Triplet的loss。通过此方式,我们既可以缩减类内距离,又能够拉大类间距离,进而增强特征学习的效果。可见,在基于Triplet loss的学习中,关键问题是对于上述三个分支的选择。
对于positive样本,我们会选择同一个标签的样本;而对于negative样本,则尽量选择那些移位不同所对应的标签图片。因此,通过迭代式训练,我们最终的分类效果(即top1)为68%。
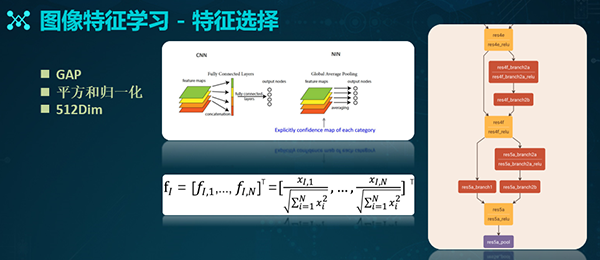
有了上述基本特征的提取网络,我们接着需要考虑具体应选用哪些特征。如上图所示,我们分别对于res所对应的5a、5b、5c、以及res4的一些层(如fc层)进行了特征提取。通过验证,我们最终认为:基于res 5a层所得到的结果最好。
在res 5a层上,我们会结合GAP(全局平均池化,Global Average Pooling)的方式,进行特征的聚合。GAP主要被用来解决全连接的问题。
如上图,通过基于res 5a的512×7×7 feature map的处理,我们能得到一个1×512的512个特征。接着,我们进行各种平方与归一化的操作,进而得到最终的检索特征。
近似最近邻检索
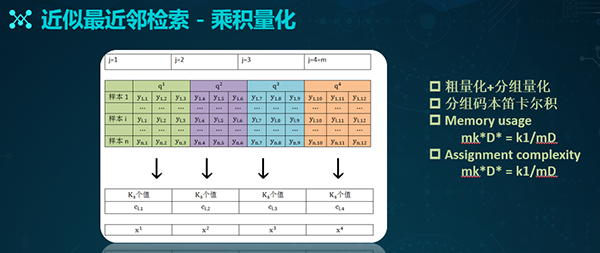
接着,我们需要通过乘积量化的方式来进行近邻检索。乘积量化是在内存和效率之间实现平衡的一种方式。它既能为图像的检索结构提供足够的内存,又能保证检索的质量与速度。
其核心思想是对特征进行分组量化,即:将某个特征分成M组,对每一组进行细致的量化,进而通过每一组量化中心的卡尔积,得到最终的码本。
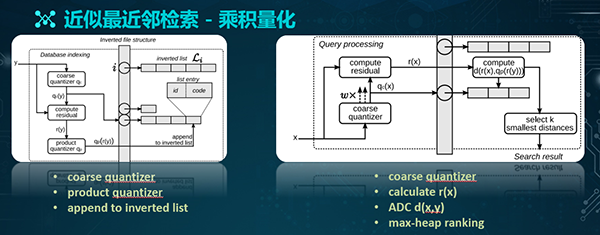
在检索过程中,我们需要构建索引的结构。上面左侧图是我们对于数据库采用的检索结构。输入Y对应的是数据库中某一张图片。
通过粗量化的中心计算,我们能够得到一个粗量化的QC,该QC即为对应的倒排文件入口。通过计算Y和QC之间的残差向量,我们便可得出一个RY。
RY再通过M分组,让每个分组对应一个细量化的中心。籍此,我们便可将该图片加入其对应的粗量化倒排链了。
如上面右侧图所示,在查询图像时,我们会先通过粗的量化,给X找到对应的检索入口,接着计算其残差,并根据既有的侯选查询集合,计算出该残差和集合的具体距离,最后再通过排序,以得到检索结果。
Reranking
为了得到更为全局的特征,我们需要采用Reranking,来挖掘图像的局部特征。此处,我们是通过结合RMAC特征,以及Attention方式来实现的。
RMAC方式是通过变窗口的方式来进行滑窗的。该滑窗过程不是在图像本身上进行的,而是在某个feature map上实现的。因此,它保障了特征提取的速度。
不过,虽然RMAC可以提取许多局部区域特征,但是它并未考虑到不同region之间的重要性。而且在某些情况下,由于某些图片包含了较多的背景区域,从而干扰了检索效果。因此,我们需要结合Regional attention来进行学习,以得出特征的重要性。
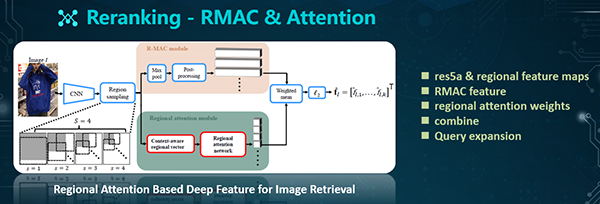
具体做法如上图所示:通过前面训练出来的网络结构,我们可以得出图像的Res维特征。接着,我们基于不同的scale,进行局部特征的提取。
通过该四个scale的特征选取,我们能够保证相邻窗口具有40%的overlap。之后,会配有两个分支:
- R-MAC模块。其中包含了Max spooling和后处理过程(Post-processing)。该后处理过程包括:L2-normalization和PCA-whitening。此后通过sum-pooling和L2-normalization得到Global feature vector的表达。
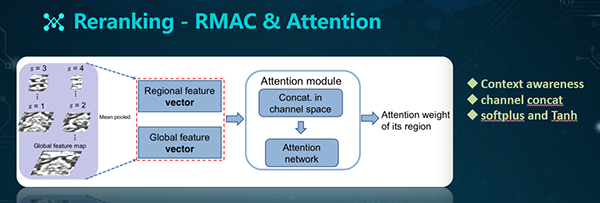
- Regional attention模块。鉴于这些局部特征的重要性,我们需要结合Regional attention模块,来学习不同的权重。具体过程是:我们将区域特征(Regional feature)和全局特征(Global feature)进行融合(Mean pooled),以实现对上下文的感知(Context-aware)。在Attention模块中,我们在Channel space中进行了Concat,之后进入Attention network(其中包括两个线性层和两个非线性层),以得到Attention的权重。
结合上述RMAC的特征,我们通过加权,以得到基于局部特征的表达。接着,我们会基于topN的结果执行Reranking。当然,我们也会结合扩展查询(Query expansion)的方式,以进一步提升检索的效果。
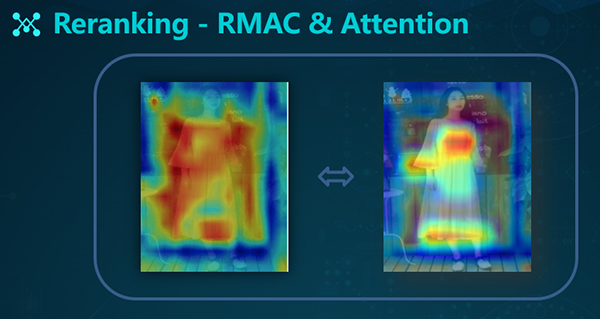
如上图所示,左侧是RNN网络提取的全局的特征,右侧是RMAC+Attention网络提取的局部特征。
评测集及指标
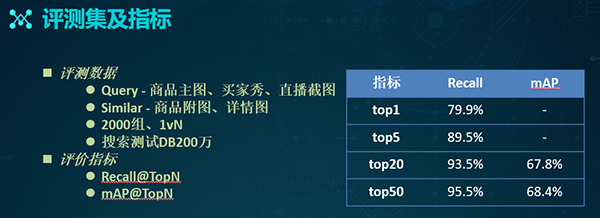
为了评测效果,我们准备了如下评测数据:
- Query图片,包括:商品主图、买家秀、以及直播截图。
- Similar图片,包括:商品附图和详情图。
- 共2000组、1对1形式(商品的主图对应着商品的详情图)和1对N形式(一张主图片对应N张详细图片)。
- 搜索测试DB:200万。
在结果上,我们分别设置了两个算法测试指标:TopN的召回结果和TopN的mAP结果。

上图展示了可视化搜索的效果。
系统及业务应用
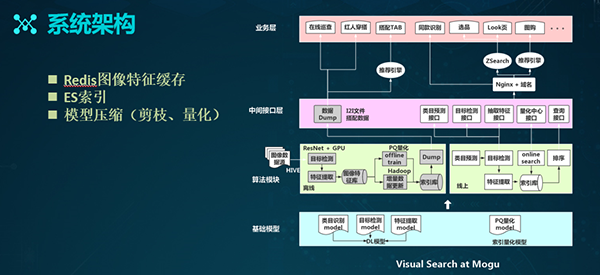
上面是蘑菇街视觉搜索的系统架构图。它分为四个层级:
- 基础网络模型,包括:类目的识别、目标的检测和特征提取的深度学习。同时它也包括基于PQ量化的模型。
- 算法模块,分为离线和线上两个部分:
- 离线数据的处理,包括:目标检测、特征提取、生成索引库、以及通过Dump过程生成一些echo文件和数据。
- 线上的搜索过程,对应了前面提到的那张表。
- 中间接口层,灰色为Dump数据的生成,右边白色在线部分是针对不同算法模块所给出接口。
- 业务应用层,此处罗列了各种业务。目前,除了http接口,我们还接入了ZSerach和推荐引擎,以丰富推送结果。
下面具体介绍几个业务应用:
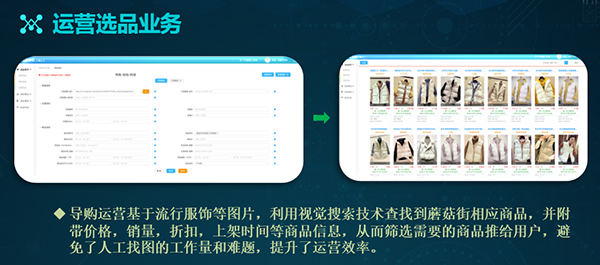
运营选品业务:导购运营基于流行服饰等图片,利用视觉搜索技术,查找到蘑菇街相应的商品。通过接入选品的后台,我们根据运营输入的图片,搜索出来各种相似的商品图片。
这些图片附带有价格、销量、折扣、上架时间等商品信息。运营筛选需要的商品,通过APP前端推给用户,从而避免了人工找图的工作量,同时提升了运营效率。
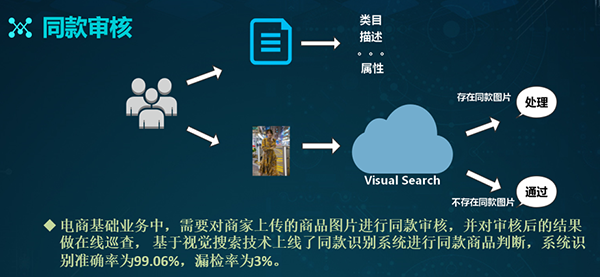
同款审核:电商的基础业务需要对商家上传的商品图片进行同款审核,并提供商家对于审核结果的在线查询。
因此,在接入了视觉搜索技术之后,我们通过识别系统来判断同款商品,并返回结果数据。在该算法上线之后,我们通过结合业务数据的实测,整体系统的准确率达到了99.06%,而漏检率仅有3%。
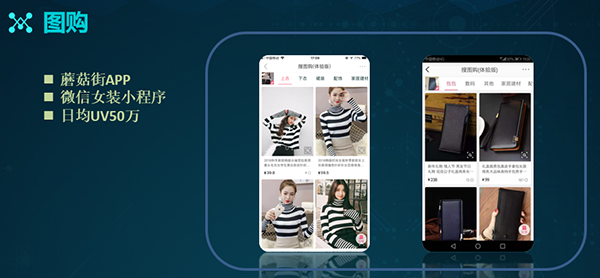
搜图购类产品:我们在2017年底上线了该产品的App端,而在2018年初上线了微信女装小程序。该产品的整体情况为:日均UV可达50万左右。
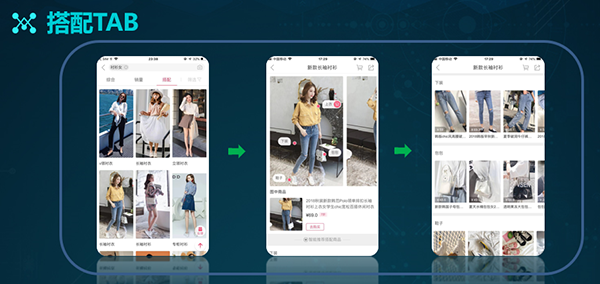
搭配TAB:为了给用户推荐各种搭配商品,我们基于现有图像数据库,结合目标检测算法,对全身图商品进行了检测。系统通过区分不同区块,以获取相似商品的搜索结果。
如上图所示,用户在点击了首页里的搭配图之后,便可获取详细的展示信息,进而在第三层的页面上,看到不同区块的相似性推荐结果。

Buy The Look:在内容分享场景中,达人们会晒出自己的服饰自拍图,我们根据这些图片进行目标检测,并通过每个区块实施相似搜索,最终给用户推送对应的相似商品。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】
【责任编辑:庞桂玉 TEL:(010)68476606】
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

