java-IO编程
IO流是一种顺序读写数据的模式:
- 单向流动
- 以byte为最小单位(字节流)
如果字符不是单子节表示的ASCLL码,Java还提供一下解决方案:
- java还提供了reader、writer表示字符流
- 字符流传输的最小单位是char
- 字符流输出byte取决于编码方式

reader、writer本质上是一个能自动编解码的InputStream/OutputStream: 使用reader虽然读入的数据源是子节,但是我们读入的数据都是char类型的字符

使用InputStream虽然读入的数据和源一样都是byte子节,但是我们可以根据编码将二进制byte数组转换成字符串达到和reader一样的效果

那么如何选择reader和InputStream?这取决于数据源,如果数据源不是文本就只能使用InputStream,如果是文本使用reader更加方便。
同步io与异步io
同步io:
- 读写io时代码等待数据返回后才继续执行后续代码
- 代码编写简单,cpu执行效率低
异步io:
- 读写io时仅发出请求,然后立刻执行后续代码
- 代码编写复杂,cpu执行效率高
JDK提供的java.io是同步io,java.nio是异步io

File对象
java.io.File表示文件系统的一个文件或者目录 创建方法:可以是相对路径或者绝对路径
// windows
File f=new File("c://win//note.exe");
// linux
File f=new File("/usr/bin/javac");
复制代码
获取路径/绝对路径/规范路径:getPath() / getAbsolutePath() / getCanonicalPath() 判断文件或目录:
- isFile():是否是文件
- isDirectory():是否是目录
需要注意的是构造一个File对象,即使我们传入的文件或目录不存在也不会报错,因为没有对磁盘进行任何操作,只有在调用某些方法的时候如果文件或目录不存在才会报错。
文件操作:
- canRead():是否允许读取该文件
- canWrite():是否允许写入该文件
- canExecute():是否允许运行该文件
- length():获取文件大小
- createNewFile():创建一个新文件
- static createTempFile():创建一个临时文件
- delete():删除该文件
- deleteOnExit():在JVM退出时删除该文件
目录操作:
- String[] list():列出目录下的文件和子目录名
- File[] listFiles():列出目录下的文件和子目录名
- File[] listFiles(FileFilter filter)
- File[] listFiles(FilenameFilter filter)
- mkdir():创建该目录
- mkdirs():创建该目录,并在必要时将不存在的父目录也创建出来
- delete():删除该目录
Input和Output
InputStream
java.io.InputStream是所有输入流的超类
- int read()从输入流中读取数据的下一个字节,返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回-1。在输入数据可用、检测到流末尾或者抛出异常前,此方法一直阻塞。
- int read(byte[])读取若干字节并填充到byte[]数组,返回读取的字节数
- read()方法是阻塞(blocking)的
完整的读取InputStream所有子节

改造后的代码,使用缓存加快读取的速度:
package com.feiyangedu.sample;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream input = new FileInputStream("readme.txt")) {
int n;
byte[] buffer = new byte[1000];
while ((n = input.read(buffer)) != -1) {
System.out.println(n);
}
}
}
}
复制代码
上面代码存在一个问题,如果在读取过程中发生io错误,InputStream就无法正确的关闭资源得不到释放。改造后的代码如下:

或者(JDK1.7以后的写法)

利用缓冲区一次读取多个子节,提高效率:

ByteArrayInputStream可以在内存中模拟一个InputStream:
他的作用是将一个数组变成一个InputStream,常常用于测试

OutputStream
OutputStream是所有输出流的超类:
- write(int b)写入一个字节
- write(byte[])写入byte[]数组的所有字节
- close():关闭输出流,使用try(resource)可以保证OutputStream正确关闭
- flush()方法将缓冲器内容输出,通常是自动调用不需要手动调用

package com.feiyangedu.sample;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream output = new FileOutputStream("output.txt")) {
byte[] b1 = "Hello".getBytes("UTF-8");
output.write(b1);
byte[] b2 = "你好".getBytes("UTF-8");
output.write(b2);
}
}
}
复制代码
输入流、输出流、字节数组缓冲区的综合实例
InputStream输入流、OutputStream输出流、ByteArrayInputStream输入缓冲区、ByteArrayOutStream输出缓冲区的协调使用。
输入流与输出流可以比喻成水管的两端,当水流通过入口(InputStream)流入通过出口(OutputStream)流出完成文件或者字符串从一个点到另一个点的移动或者转换,在这个过程中似乎不需要缓冲区的介入。那么什么时候会用到缓冲区呢?当你想在输入流和输出流中间有很多操作,或者将输入流“复制”一份去做另一个操作的时候就要用到缓冲区了。 比如我们上传图片,为了更加安全,通过文件的前四个字符串来判断文件的类型: (写一个实例)
// 创建输出流缓冲区
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = file.read(buffer)) > -1 ) {
baos.write(buffer, 0, len);
}
// 将缓冲区数据写入到数组中
baos.flush();
// 关闭文件
baos.close();
// 创建输出流缓冲区,将输入流缓冲区的数据写入到输入流缓冲区中,这样就实现了一次输入多次输出的效果
InputStream getType = new ByteArrayInputStream(baos.toByteArray()); // 拿去检测文件类型
InputStream fileImg = new ByteArrayInputStream(baos.toByteArray()); // 如果文件类型合法,拿去上传文件
复制代码
总结
- OutputStream是所有输出流的超类
- FileOutputStream实现了文件流输出
- ByteArrayOutStream在内存中模拟一个字节流输出
- 使用try(resource)可以保证OutputStream正确关闭
Filter模式
已FileInputStream()为例,他从文件中读取数据,是最终数据源。
在FileInputStream上增加功能的常规做法
如果我们要给FileInputStream添加缓冲功能: BufferedFileInputStream extends FileInputStream 派生一个BufferedFileInputStream 如果给FileInputStream添加计算签名的功能: DigestFileInputStream extends FileInputStream 派生一个DigestFileInputStream ..... 如果要添加更多的功能就需要更多的子类去扩展,这样的做的弊端是造成子类爆炸
JDK的Filter模式
JDK为了解决上面的问题把InputStream分为两类:
- 直接提供数据的的InputStream:(数据真正的来源)
- FileInputStream
- ByteArrayInputStream
- ServletInputStream
- ...
- 提供额外附加功能的InputStream:
- BufferedInputStream
- DigestInputStream
- CipherInputStream
- ...
如何使用
组合:将一个对象复制给另一个对象的变量,使其持有另一个的对象的特性和方法 当我们使用InputStream的时候我们要根据实际情况 组合 使用:

上图显示FileInputStream提供数据后经过两次包装后,具有了更多的功能,但是无论经过多少次包装他依然可以向上转型为InputStream然后进行操作。
Filter模式又称Decorator模式,通过少量的类实现了各种功能的组合。
InputStream继承树
FilterInputStream 的作用是用来“封装其它的输入流,并为它们提供额外的功能”。它的常用的子类有BufferedInputStream和DataInputStream。 一边是提供数据的实现类,一边是提供附加功能的实现类。通过两边实现类的组合实现更多的功能。
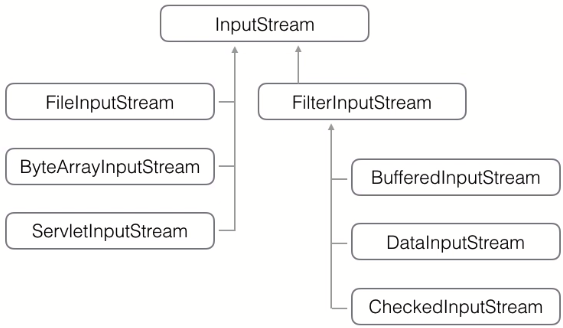
个人理解:提供数据的实现类不能进行同类包装,而功能类可以同类包装。
实例
package com.feiyangedu.sample;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.zip.GZIPInputStream;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream input = new GZIPInputStream(new BufferedInputStream(new FileInputStream("test.txt.gz")))) {
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int n;
while ((n = input.read(buffer)) != -1) {
output.write(buffer, 0, n);
}
byte[] data = output.toByteArray();
String text = new String(data, "UTF-8");
System.out.println(text);
}
}
}
复制代码
编写自定义工具类计算读取的字节数
import java.io.*;
import java.util.zip.GZIPInputStream;
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream input = new CountInputStream(new GZIPInputStream(new BufferedInputStream(new FileInputStream("test.txt.gz"))))) {
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int n;
while ((n = input.read(buffer)) != -1) {
output.write(buffer, 0, n);
}
byte[] data = output.toByteArray();
String text = new String(data, "UTF-8");
// 打印内容
//System.out.println(text);
//由于我们要使用count方法,因此要将InputStream类型向下转型为CountInputStream,因为我们明确的知道继承关系这里可以不判断是否可以安全的向下转型
System.out.println(InputStream.class.isAssignableFrom(CountInputStream.class));
System.out.println(((CountInputStream) input).count);
}
}
}
class CountInputStream extends FilterInputStream {
int count=0;
public CountInputStream(InputStream in) {
super(in);
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
//通过调用父类的read方法获取包装的inputStream的字节长度
int n = super.read(b, off, len);
count +=n;
return n;
}
}
复制代码
输出
true 11356 复制代码
关于字节(重要)
InputStream的read()与read(byte[] b)
在学习的过程中发现如果使用read()返回的值代表字节值(0-255),而使用read(byte[] b)则返回的是读取的字节长度,而字节值储存在 byte[] b 类型的b变量中为什么会产生这样的结果?
首先看JDK的解释:InputStream的read()的方法从输入流中读取数据的下一个字节,返回0到255范围内的int字节值。
那么问题来了0到255范围的字节值是什么?
简单解释: 00000000 一个字节包含8位二进制值,这8位二进制数相互变化,共有2^8 = 256种数字,0~255 那么InputStream的read()每次返回的就是0~255的值,这个int类型10进制的值可以转换成一个8位的二进制数 字符类型:char,因为java的char使用unicode编码,所以可直接赋值给int类型查看他的unicode编码 反过来就是一个int类型(char)int就可以直接转换成char字符
ab中国cdefj 复制代码
import java.io.*;
import java.util.zip.GZIPInputStream;
public class Main {
public static void main(String[] args) throws IOException {
InputStream in = null;
File f = new File("test.txt");
in = new FileInputStream(f);
int i = 0;
while ((i = in.read()) != -1) {
//String str = new String((char)i);
System.out.println((char)i);
}
}
}
复制代码
输出
a b ä ¸ å ½ c d e f j 复制代码
上面的程序演示了 read() 读取单个字节然后返回的int类型的值,通过 (char)i 强制转型为单个字符然后输出,由于中文是占3个字符的所以中文部分显示乱码
下面的代码演示byte[]读取数据
import java.io.*;
import java.util.zip.GZIPInputStream;
public class Main {
public static void main(String[] args) throws IOException {
InputStream in = null;
File f = new File("test.txt");
//当一次读取3个字节的时候如果凑巧全是中文,或者从第四个字节开始是中文,就不会出现乱码,如果不是就会出现乱码
byte[] b = new byte[3];
in = new FileInputStream(f);
int i = 0;
while ((i = in.read(b)) != -1) {
//String函数可以接收一个char数组或者byte数组然后转换成字符串
String str = new String(b);
System.out.println(str);
}
}
}
复制代码
下面是两种演示数据: 不会出现乱码,因为第三个字节后是中文,每次都三个字节正好读取一个中文字符
abc中国cdefj 复制代码
显示效果
abc 中 国 cde fje 复制代码
如果没有前面的c
ab中国cdefj 复制代码
就会输出乱码
ab� ��� ��c def jef 复制代码
操作Zip
ZipInputStream继承自FlaterInputStream实现了ZipConstants接口,虽然ZipInputStream是FlaterInputStream子类但是有些方法是ZipInputStream独有的,在使用这些方法的时候不能向上转型,因此使用ZipInputStream的时候直接创建一个他的实例而且无需向上转型,
ZipInputStream可以读取Zip流。 JarInputStream提供了额外读取jar包内容的能力。 ZipOutputStream可以写入Zip流。 配合FileInputStream和FileOutputStream就可以读写Zip文件。
package com.feiyangedu.sample;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class Main {
public static void main(String[] args) throws IOException {
try (ZipInputStream zip = new ZipInputStream(new BufferedInputStream(new FileInputStream("test.jar")))) {
ZipEntry entry = null;
while ((entry = zip.getNextEntry()) != null) {
if (entry.isDirectory()) {
System.out.println("D " + entry.getName());
} else {
System.out.println("F " + entry.getName() + " " + entry.getSize());
printFileContent(zip);
}
}
}
}
static void printFileContent(ZipInputStream zip) throws IOException {
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int n;
while ((n = zip.read(buffer)) != -1) {
output.write(buffer, 0, n);
}
byte[] data = output.toByteArray();
System.out.println(" size: " + data.length);
}
}
复制代码
classpath资源 (linux与win的路径有区别)
classpath中可以包含任意类型的文件。 从classpath读取文件可以避免不同环境下文件路径不一致的问题。 读取classpath资源:
try(InputStream input = getClass().getResourceAsStream("/default.properties")) {
if (input != null) {
// Read from classpath
}
}
复制代码
- 把资源存储在classpath中可以避免文件路径依赖
- class对象的getResourceAsStream()可以从classpath读取资源
- 需要检查返回的InputStream是否为null
package com.feiyangedu.sample;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Properties;
public class Main {
public static void main(String[] args) throws IOException {
// 从classpath读取配置文件:
try (InputStream input = Main.class.getResourceAsStream("/conf.properties")) {
if (input != null) {
System.out.println("Read /conf.properties...");
Properties props = new Properties();
props.load(input);
System.out.println("name=" + props.getProperty("name"));
}
}
// 从classpath读取txt文件:
String data = "/com/feiyangedu/sample/data.txt";
try (InputStream input = Main.class.getResourceAsStream(data)) {
if (input != null) {
System.out.println("Read " + data + "...");
BufferedReader reader = new BufferedReader(new InputStreamReader(input, "UTF-8"));
System.out.println(reader.readLine());
} else {
System.out.println("Resource not found: " + data);
}
}
}
}
复制代码
conf.properties
name=Java IO url=www.feiyangedu.com 复制代码
序列化
序列化是指把一个Java对象变成二进制内容(byte[]) Java对象实现序列化必须实现Serializable接口(空接口) 反序列化是指把一个二进制内容(byte[])变成Java对象 使用ObjectOutputStream和ObjectInputStream实现序列化和反序列化 readObject()可能抛出的异常:
- ClassNotFoundException:没有找到对应的Class
- InvalidClassException:Class不匹配
- 反序列化由JVM直接构造出Java对象,不调用构造方法
- 可设置serialVersionUID作为版本号(非必需)
Reader与InputStream
Reader与InputStream的区别:

Reader以字符为最小单位实现了字符流输入:
- int read() 读取下一个字符并返回字符int值(0-65535)
- int read(char[]) 读取若干字符并填充到char[]数组 常用Reader类:
- FileReader:从文件读取
- CharArrayReader:从char[]数组读取
完整读取文件实例

利用缓冲区读取文件

FileReader可以从文件中获取Reader: 但是要注意这里使用的是系统默认的编码

CharArrayReader可以在内存中模拟一个Reader:

Reader与InputStream的关系
Reader是基于InputStream构造的,任何InputStream都可指定编码并通过InputStreamReader转换为Reader:
Reader reader = new InputStreamReader(input, "UTF-8") 复制代码

FileInputStream
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (Reader reader = new InputStreamReader(new FileInputStream("readme.txt"),"UTF-8")) {
int n;
while ((n = reader.read()) != -1) {
System.out.println((char) n);
}
}
}
}
复制代码
Writer与OutputStream
Writer与OutputStream的区别
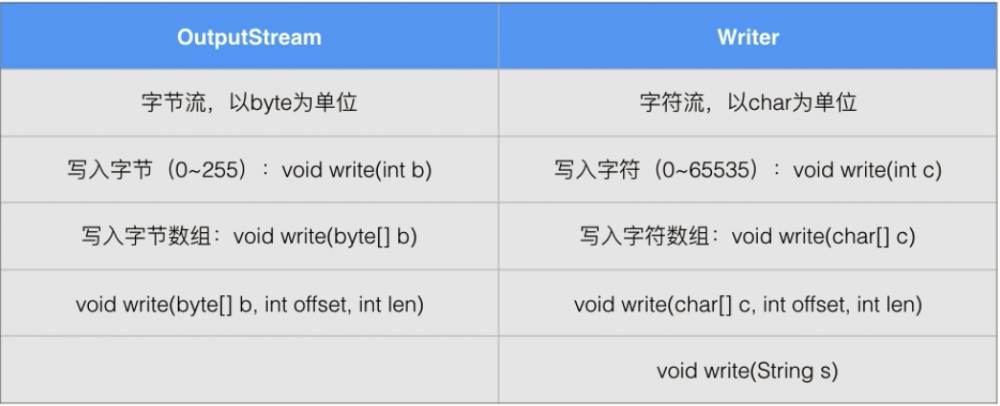
Writer以字符为最小单位实现了字符流输出:
- write(int c) 写入下一个字符(0-65535)
- write(char[]) 写入char[]数组的所有字符
- write(char[] c,int off,int len) 写入指定范围的字符
- write(String s)写入string表示的字符
常用Writer类:
- FileWriter:写入文件
- CharArrayWriter:写入char[]数组
向Writer写入字符:

FileWriter可以从文件中获取Writer:

CharArrayWriter可以在内存中模拟一个Writer:

Writer与OutputStream的关系
Writer是基于OutputStream构造的,任何OutputStream都可指定编码并通过OutputStreamWriter转换为Writer:
Writer writer = new OutputStreamWriter(output, "UTF-8") 复制代码
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

