Recap | Query Pulsar Streams using Apache Flink

:book: 背景
2019 年 10 月 7-9 日, Flink Forward Europe 2019 在德国柏林举行,大会主题涵盖了 ApacheFlink® 用例、内部知识、Flink 生态系统的增长以及有关流处理和实时分析的多种主题,多个大牛技术团队也参与了此次大会。
StreamNative 作为唯一一家 startup 赞助商也参与了此次大会,StreamNative CEO 郭斯杰发表了主题为 「Query Pulsar Streams using Apache Flink」 的演讲,分享了 Pulsar 与 Flink 1.9 进行集成的最新动态。
️ 前言
郭斯杰的主题演讲主要由两部分构成: Apache Pulsar 的特性、 为什么 Pulsar 是批流融合计算的最佳存储系统 ,和关于 Pulsar 与 Flink 集成的最新进展 ,对比了 1.6 和 1.9 集成,并进行了 Pulsar Catalog 的 demo 展示。
关于 Apache Pulsar 的介绍,我们已经整理了一份详细的 Apache Pulsar 介绍 ,点击就可以查看啦~
以下着重介绍 Pulsar 与 Flink 集成 的相关内容。
:mag_right: Pulsar + Flink
Pulsar 与 Flink 1.6 版本的集成比较简单。Pulsar 主要提供 Streaming Source、Streaming Sink 和 Table Sink 这三个 connectors。

而进化到 1.9 版本以后的 Flink 则有了更多出色的表现。StreamNative 基于 Flink 1.9.0 和 Pulsar 2.4.0 重新进行了 Pulsar 和 Flink 的集成工作。
新的集成工作主要围绕 Pulsar 的内置 Schema 开展,实现了 exactly-once 语义的 Source 和 at-least-once 语义的 Sink。
郭斯杰也在现场进行了 demo 展示,完整视频可点击下方查看。
总的来说,最新的 Pulsar Flink connector 有如下特点:
原生支持将 Pulsar 的 topic 作为有结构的表进行消费,支持 Flink 1.9 的最新 Table API,可以将 Pulsar 映射为 Flink 的一个 catalog,以及在 Table API 和 SQLClient 中使用。
:runner:♂️未来展望
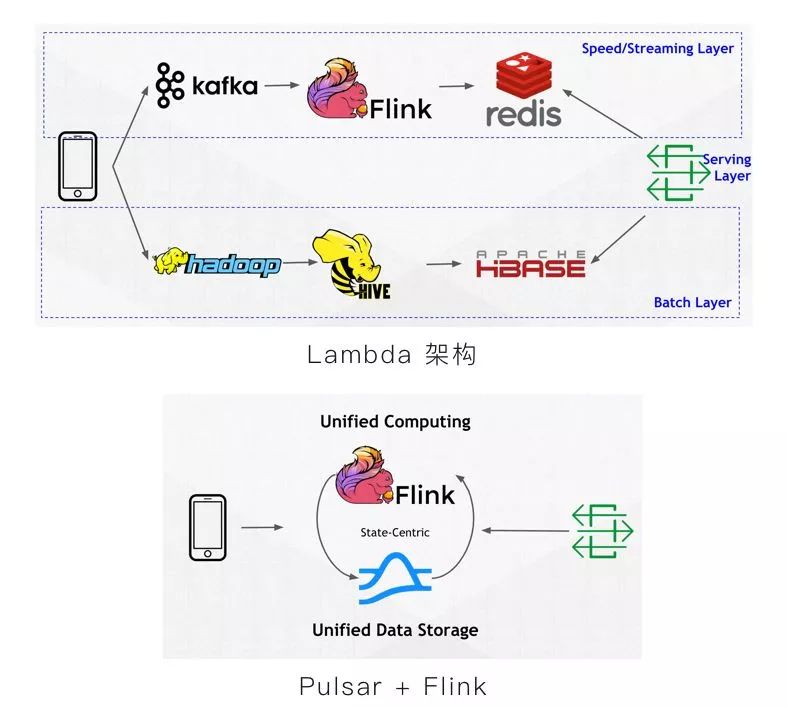
之前 Lambda 架构下,Flink 参与的过程较为复杂。现在将 Apache Pulsar 和 Flink 结合之后,简化了流程,并拥有了统一的数据表征,客户则无需关心数据究竟存储在何处。
当然,开源的过程是为了更好的前进。未来我们还需要去创新和完善的事情依然很多,比如:
-
基于新的 Source API (FLIP-27)的批、流统一的数据读取
-
横向扩展 Source 并行粒度
-
基于Pulsar 2.5.0 中的 Key_Shared 订阅和粘性消费者
-
实现端到端的 Exactly-once 语义
-
需要借助在 Pulsar 2.5.0 版本中的事务支持
-
将 Pulsar / BookKeeper 作为 Flink 的 State 存储
-
感知消息结构的分层存储

:raising_hand: 总结
-
Apache Pulsar 是云原生的流数据存储系统
-
拥有两级数据读取 API :基于发布/订阅的消费和直接基于分段的读
-
可通过 Pulsar Schema 进行结构化事件流解析消费
-
Pulsar 可作为 Flink 的统一数据存储
-
基于 Pulsar + Flink 构建批流一体的、统一的数据处理栈

点击「阅读原文」可下载此分享内容的 PPT 稿件
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

