Skywalking第七篇——Trace收集(一)

前文回顾
通过前面三篇文章,我们终于把 Skywalking Agent 初始化分析完拉。从这一小节开始,我们将开始介绍 Trace 格式、收集方式以及上报方式。

Trace基本概念
在开始介绍发送 Trace 的具体实现之前,先简单说一下 Trace 相关的基本概念,要是客官们已经了解了这些概念,可以跳过这部分。读者也可以参考一下《OpenTracing语义标准》(https://github.com/opentracing-contrib/opentracing-specification-zh/blob/master/specification.md) 。
OpenTracing中的一条 Trace (调用链)可以被认为是一个由多个 Span 组成的有向无环图(DAG图), Span 与 Span 的关系被命名为 References。Span 可以被理解为一次方法调用、一次 RPC 或是一次 DB 访问。下面的示例 Trace 就是由 8 个 Span 组成:
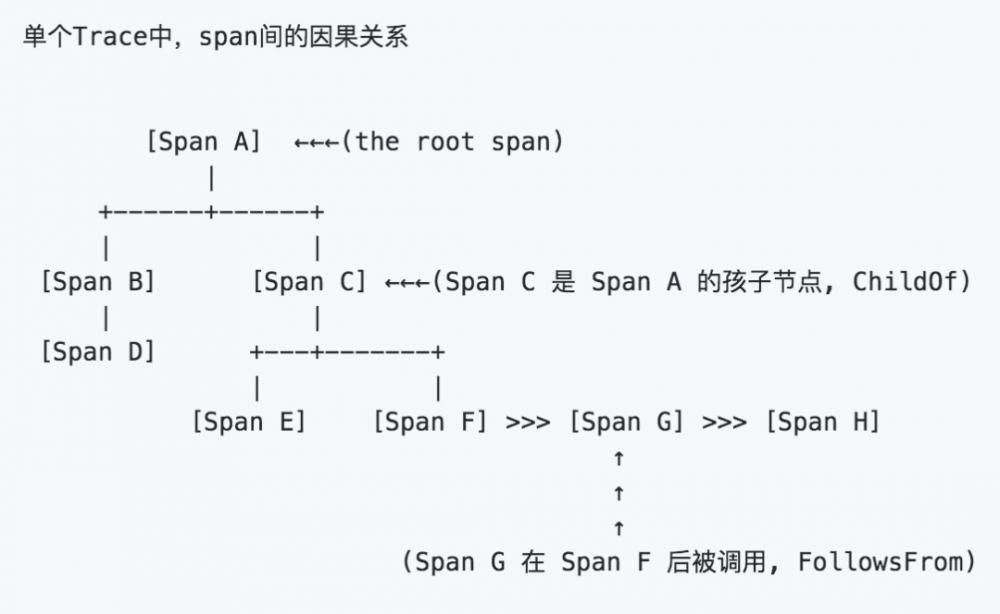
有些时候,使用下面这种,基于时间轴的时序图可以更好的展现 Trace (调用链):
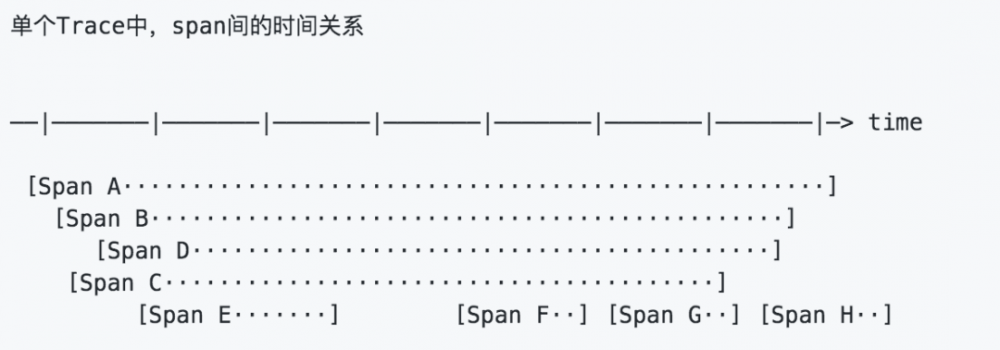
每个 Span 包含以下的状态:
-
An operation name,操作名称
-
A start timestamp,起始时间
-
A finish timestamp,结束时间
-
Span Tag,一组键值对构成的Span标签集合。键值对中,键必须为string,值可以是字符串,布尔,或者数字类型。
-
Span Log,一组span的日志集合。每次log操作包含一个键值对,以及一个时间戳。键值对中,键必须为string,值可以是任意类型。但是需要注意,不是所有的支持OpenTracing的Tracer,都需要支持所有的值类型。
-
SpanContext,Span上下文对象 (下面会详细说明)
-
References(Span间关系),相关的零个或者多个Span(Span间通过SpanContext建立这种关系)
每一个 SpanContext 包含以下状态:
-
任何一个 OpenTracing 的实现,都需要将当前调用链的状态(例如:trace id 和 span id),依赖一个独特的 Span 去跨进程边界传输
-
Baggage Items,Trace 的随行数据,是一个键值对集合,它存在于 Trace 中,也需要跨进程边界传输
Span间关系
一个 Span 可以与一个或者多个
SpanContexts
存在因果关系。OpenTracing 目前定义了两种关系:
ChildOf
(父子) 和
FollowsFrom
(跟随)。 这两种关系明确的给出了两个父子关系的Span的因果模型
。
ChildOf 引用:一个 Span 可能是一个父级 Span 的孩子,即"ChildOf"关系。在 ChildOf 引用关系下,父级 Span 某种程度上取决于子 Span。下面这些情况会构成 ChildOf 关系:
-
一个 RPC 调用的服务端的 Span,和RPC服务客户端的 Span 构成 ChildOf 关系。
-
一个 sql insert 操作的 Span,和 ORM 的 save 方法的 Span 构成 ChildOf 关系。
-
很多 Span 可以并行工作(或者分布式工作)都可能是一个父级的 Span 的子项,它会合并所有子 Span 的执行结果,并在指定期限内返回。
下面都是合理的表述一个 ChildOf 关系的父子节点关系的时序图:

FollowFrom 引用: 个人觉得不是很常见,不说了。
回到 Skywalking ,在 Skywalking 的设计中,在 Trace级别 和 Span 级别之间加了一个 Segment 的概念,用于表示一个 OS 里面的 Span 集合。
Skywalking 中的Span分为三类:
1、EntrySpan:表示服务端的入口,包括但不限于Http服务、RPC服务、MQ-Consumer等
2、LocalSpan:表示本地的方法调用
3、ExitSpan:表示 Client 或是MQ-producer
Skywalking 中具体的 Span 实现在后面分析收集 Trace 的小节中再详细分析,这里先不深入分析了。

TraceSegment
TraceSegment 是一条 Trace 的一段,TraceSegment 用于记录当前线程的 Trace 信息。分布式系统基本会涉及跨线程的操作,例如, RPC、MQ等,怎么也要有 DB 访问吧,╮(╯_╰)╭,所以一条 Trace 基本都是由多个 TraceSegment 构成的。
// TraceSegment的全局唯一标识
private ID traceSegmentId;
// 指向父 TraceSegment
private List<TraceSegmentRef> refs;
// 所在 Trace的 traceId
private DistributedTraceIds relatedGlobalTraces;
// 构成当前 TraceSegment的 Span集合
private List<AbstractTracingSpan> spans;
// 是否要收集当前 TraceSegment
private boolean ignore = false;
// 当前 TraceSegment中的 Span个数是否超过上限,超过上限之后,就不再添加 Span了
private boolean isSizeLimited = false;
我们常见的 RPC 调用啊、Http 调用啊之类的,每个 TraceSegment 只有一个 parent。但是当一个 Consumer 批量处理 MQ 消息的时候,其中的每条消息都来自不同的 Producer ,就会有多个 parent 了,同时这个 TraceSegment 也就属于多个 Trace 了。

ID
traceSegmentId 字段的类型是ID,它由三个long类型的字段(part1、part2、part3)构成,分别记录了 service_instance_id、线程Id、Context生成序列。
Context生成序列的格式是:
${时间戳} * 10000 + 线程自增序列([0, 9999])
TraceSegment Id 的最终格式是:
${service_instance_id}.${thread_id}.(${时间戳} * 10000 + 线程自增序列([0, 9999]))
再来是 GlobalIdGenerator,它是用来生成 ID 对象的 ,直接看它的 generate() 方法:
public static ID generate() {
// IDContext存在 ThreadLocal里面
IDContext context = THREAD_ID_SEQUENCE.get();
return new ID(
RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID, // service_intance_id
Thread.currentThread().getId(), // 当前线程ID
context.nextSeq() // 线程内生成的序列号
);
}

DistributedTraceId
DistributedTraceId 用于生成全局的 TraceId,其中封装了一个 ID 类型的字段。DistributedTraceId 是个抽象类,它有两个实现类,如下图所示:
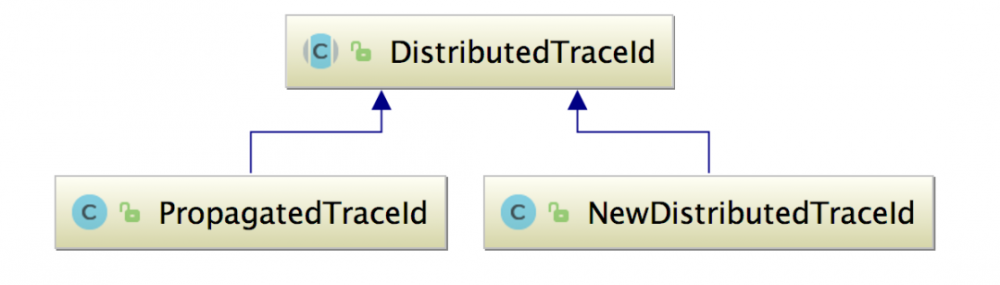
其中 NewDistirbutedTraceId 负责为新 Trace 生成 编号,在请求进入我们的系统、第一次创建 TraceSegment 对象的时候,会创建 NewDistirbutedTraceId 对象,在其构造方法内部会调用 GlobalIdGenerator.generate() 方法生成创建 ID 对象。
PropagatedTraceId 负责处理 Trace 传播过程中的 TraceId,PropagatedTraceId的构造方法接收一个 String 类型的 TraceId ,解析之后得到 ID 对象。
TraceSegment中的 relatedGlobalTraces 字段是 DistributedTraceIds 类型,它的底层封装了一个 LinkedList<DistributedTraceId> 集合,用于记录当前 TraceSegment 关联的 TraceId。为什么是一个集合呢?与上面提到的,一个 TraceSegment 可能有多个 parent 的情况一样。

Span
TraceSegment 是由多个 Span 构成的,下图是 Span 的继承关系:
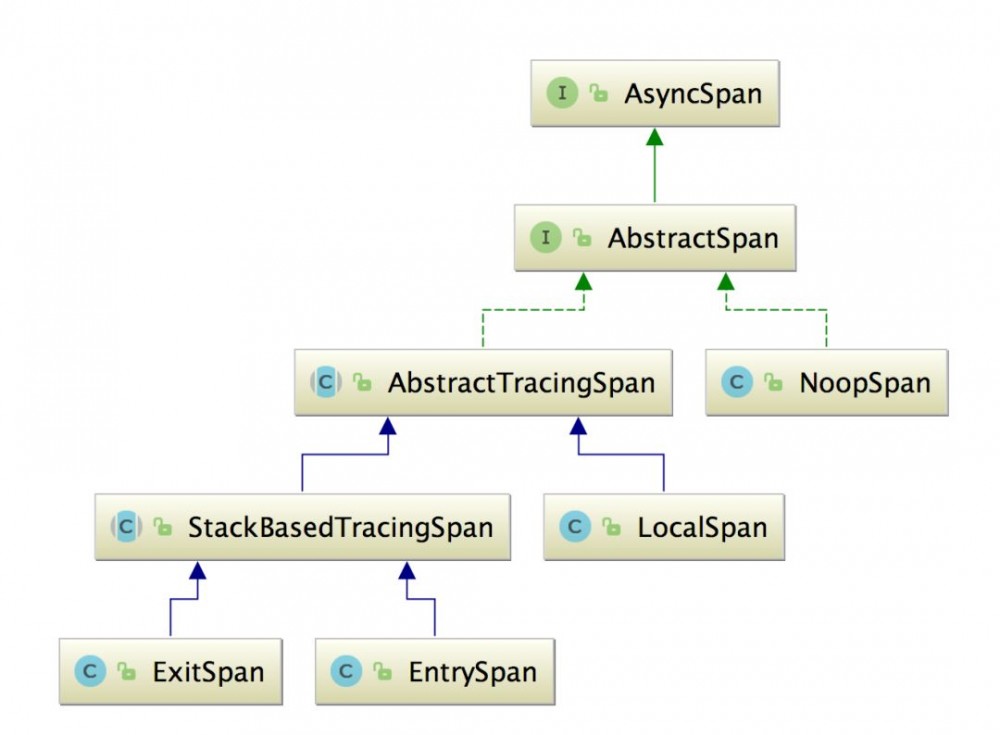
从顶层开始看呗,AsyncSpan 接口定义了一个异步 Span 的基本行为:
-
prepareForAsync()方法:当前 Span 在当前线程结束了,但是当前 Span 未被彻底关闭,依然是存活的。
-
asyncFinish()方法:当前Span 真正关闭。这与 prepareForAsync() 方法成对出现。
这两个方法在异步 RPC 中会见到。
AbstractSpan 也是一个接口,其中定义了 Span 的基本行为:
-
getSpanId() 方法:获得当前 Span 的编号,Span 编号是一个整数,在 TraceSegment 内唯一,从 0 开始自增,在创建 Span 对象时生成。
-
setOperationName()/setOperationId() 方法:设置操作名/操作编号。这两个方法是互斥的,在 AbstractTracingSpan 这个实现中,有 operationId 和 operationName 两个字段,只能有一个字段有值。
-
setComponent() 方法:设置组件。它有两个重载,在 AbstractTracingSpan 这个实现中,有 componentId 和 componentName 两个字段,两个重载分别用于设置这两个字段。在 ComponentsDefine 中可以找到 Skywalking目前支持的组件。
-
setLayer() 方法:设置 SpanLayer,也就是当前 Span 所处的层次。SpanLayer 是个枚举,可选项有 DB、RPC_FRAMEWORK、HTTP、MQ、CACHE。
-
tag(AbstractTag, String) 方法:为当前 Span 添加键值对的标签。一个 Span 可以投多个标签,AbstractTag 中就封装了 String 类型的 Key ,没啥可说的。
-
log() 方法:记录当前 Span 中发生的关键日志,一个 Span 可以包含多条日志。
-
start() 方法:开始 Span 。其实就是设置当前 Span 的开始时间以及调用层级等信息。
-
isEntry() 方法:当前是否是入口 Span。EntrySpan 后面详细介绍。
-
isExit() 方法:当前是否是出口 Span。ExitSpan 后面详细介绍。
-
ref() 方法:设置关联的 TraceSegment 。
AbstractTracingSpan 实现了 AbstractSpan 接口,其中定义了一些 Span 的基础字段,其中很多字段一眼看过去就知道是啥意思了,就不一一展开介绍了,其中有一个字段:
// 记录了当前 TraceContext
protected volatile AbstractTracerContext context;
AbstractTracingSpan 中的方法也比较简单,基本都是 getter/setter 方法,其中有一个 finish() 方法,会更新 endTime 字段并将当前 Span 记录到给定的 TraceSegment 中。
StackBasedTracingSpan 这种 Span 可以多次调用 start() 方法和 end() 方法,就类似一个栈。其中多了两个字段:
protected int stackDepth; // 记录栈的深度,初始化为0
protected String peer; // 记录远端的地址,与 peerId互斥
protected int peerId; // 记录远端信息,与 peer互斥
StackBasedTracingSpan.finish() 方法会在栈彻底退出的时候,才会将当前 Span 添加到 TraceSegment 中:
public boolean finish(TraceSegment owner) {
if (--stackDepth == 0) { // 整个栈退出了,才会记录到 TraceSegment中
if (this.operationId == DictionaryUtil.nullValue()) {
this.operationId = ... // 尝试更新 operationId,具体代码后面会提到
}
return super.finish(owner);
} else {
return false;
}
}
EntrySpan 表示的是一个服务的入口 Span,主要用在服务提供方的入口,例如,Dubbo Provider、Tomcat、Spring MVC 等等。 EntrySpan 是 TraceSegment 的第一个 Span ,这也是为什么称之为"入口" Span 的原因。 那么为什么 EntrySpan 继承 StackBasedTracingSpan? 从前面对 Skywalking Agent 的分析来看, Agent 只会根据插件在相应的位置
对方法进行增强,具体的增强逻辑就包含创建 EntrySpan 对象(后面在分析具体插件实现的时候,会看到具体的实现代码), 例如,Tomcat插件 和 Spring MVC 插件。 很多 Web 项目会同时使用这两个插件,难道一个 TraceSegment 要有两个 EntrySpan 吗?
显然不合适,所以 EntrySpan 继承了 StackBasedTracingSpan,当请求经过 Tomcat 插件的时候,会创建 EntrySpan, 当请求经过 Spring MVC 插件的时候,不会再创建新的 EntrySpan 了,只是 currentMaxDepth 字段加 1。
currentMaxDepth 字段是 EntrySpan 中用于记录当前 EntrySpan 的深度的,前面介绍 StackBasedTracingSpan.finish() 方法代码时看到,只有 stackDepth 为 1 的时候,才能结束当前 Span。
EntrySpan 要关注的是其 start() 方法:
public EntrySpan start() {
// 只有在第一次 start的时候,才会修改 startTime
if ((currentMaxDepth = ++stackDepth) == 1) {
super.start(); // 在 AbstractTracingSpan中修改了 startTime 字段
}
clearWhenRestart(); // 清空所有字段
return this;
}
private void clearWhenRestart() {
this.componentId = DictionaryUtil.nullValue();
this.componentName = null;
this.layer = null;
this.logs = null;
this.tags = null;
}
虽然 EntrySpan 是在第一个增强逻辑中创建的,但是后续每次 start()方法都会清空所有字段,所以 EntrySpan 除了 startTime 和 endTime 以外的字段都是以最后一次调用 start() 方法写入的为准。在 EntrySpan 中的 set* 方法会检测 currentMaxDepth 是否为最底层,如果不是,设置相关字段没有什么意义,例如 tag()方法:
public EntrySpan tag(String key, String value) {
if (stackDepth == currentMaxDepth) { // 最底层才能加tag
super.tag(key, value);
}
return this;
}
ExitSpan 表示的是出口 Span,主要用于服务的消费者,例如,Dubbo Consumer、HttPClient等等。如果在一个调用栈里面出现多个插件创建 ExitSpan,则只会在第一个插件中创建 ExitSpan,后续调用的 ExitSpan.start() 方法并不会更新 startTime,其他的 set*() 方法也会做判断,只有 stackDepth 为1的时候,才会写入相应字段,也就是说,ExitSpan 中记录的信息是创建 ExitSpan 时填入的,与 EntrySpan 正好相反。
举个栗子,假如有一次通过 Http 方式进行的 Dubbo 调用,Dubbo A --> HttpClient --> Dubbo B,此时在 Dubbo A 的出口处,Dubbo 的插件会创建 ExitSpan 并调用 start() 方法,在 HttpClient 的出口处则只是再次调用了 start() 方法,该 ExitSpan 中记录的信息都是Dubbo A 出口处记录的。
一个 TraceSegment 可以有多个 ExitSpan,例如,Dubbo A 服务在处理一个请求时,会调用 Dubbo B 服务得到相应之后,紧接着调用了 Dubbo C 服务,这样,该 TraceSegment 就有了两个完全独立的 ExitSpan。
LocalSpan 表示的是一个本地方法调用,继承了 AbstractTracingSpan,没啥可说的,也不能递归,╮(╯_╰)╭。
行吧,Span 核心的内容就说到这里,继续往下看。

TraceSegmentRef
TraceSegment 通过 refs 集合记录父 TraceSegment 中的一个 Span,TraceSegmentRef 中的核心字段如下:
// 父 TraceSegment编号
private ID traceSegmentId;
// 父 Span编号
private int spanId = -1;
// SegmentRefType是个枚举,可选值有:CROSS_PROCESS、CROSS_THREAD,分别表示跨进程调用和跨线程调用
private SegmentRefType type;
// 对端地址
private int peerId = DictionaryUtil.nullValue();
private String peerHost;
// 入口应用的service_instance_id
private int entryServiceInstanceId = DictionaryUtil.nullValue();
// 父应用的service_instance_id
private int parentServiceInstanceId = DictionaryUtil.nullValue();
// 入口操作信息
private String entryEndpointName;
private int entryEndpointId = DictionaryUtil.nullValue();
// 父操作信息
private String parentEndpointName;
private int parentEndpointId = DictionaryUtil.nullValue();
其中最重要的还是 traceSegmentId 字段和 spanId 字段。

总结
好了,Trace 的基本概念以及 Skywalking 中的基础组建类,都大概介绍完了,主要就是:TraceSegment、ID、 Distribu tedTraceId、Span、TraceSegmentRef。这些组建中的字段也并不复杂,都是为了确定从属关系( Span 属于 TraceSegment )以及父子关系( Span的父子关系、TraceSegment 的父子关系)。这些组建中的方法也都比较简单,基本都是getter/setter方法,没有超过10行的哈,easy,easy。
扫描下图二维码,关注【程序员吴小胖】
从底部 ”源码分析“菜单 即可获取
《Skywalking源码分析指北》全部文章哟~

看懂看不懂,都点个赞吧:+1:
正文到此结束
- 本文标签: volatile http GitHub Master value stream consumer remote Service cat App 分布式系统 REST src https IDE MQ key Agent provider 源码 producer 进程 Apple 分布式 插件 dist git IO 数据 解析 构造方法 dubbo web 文章 线程 时间 id 二维码 递归 client tomcat cache UI HTML LinkedList 总结 spring ACE tar 代码 服务端 list tag 详细分析 db ORM sql 程序员 模型
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

