SpringBoot+Dubbo集成ELK实战
一直以来,日志始终伴随着我们的开发和运维过程。当系统出现了Bug,往往就是通过Xshell连接到服务器,定位到日志文件,一点点排查问题来源。
随着互联网的快速发展,我们的系统越来越庞大。依赖肉眼分析日志文件来排查问题的方式渐渐凸显出一些问题:
- 分布式集群环境下,服务器数量可能达到成百上千,如何准确定位?
- 微服务架构中,如何根据异常信息,定位其他各服务的上下文信息?
- 随着日志文件的不断增大,可能面临在服务器上不能直接打开的尴尬。
- 文本搜索太慢、无法多维度查询等
面临这些问题,我们需要集中化的日志管理,将所有服务器节点上的日志统一收集,管理,访问。
而今天,我们的手段的就是使用 Elastic Stack 来解决它们。
一、什么是Elastic Stack ?
或许有人对Elastic感觉有一点点陌生,它的前生正是ELK ,Elastic Stack 是ELK Stack的更新换代产品。
Elastic Stack分别对应了四个开源项目。
- Beats
Beats 平台集合了多种单一用途数据采集器,它负责采集各种类型的数据。比如文件、系统监控、Windows事件日志等。
- Logstash
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据。没错,它既可以采集数据,也可以转换数据。采集到了非结构化的数据,通过过滤器把他格式化成友好的类型。
- Elasticsearch
Elasticsearch 是一个基于 JSON 的分布式搜索和分析引擎。作为 Elastic Stack 的核心,它负责集中存储数据。我们上面利用Beats采集数据,通过Logstash转换之后,就可以存储到Elasticsearch。
- Kibana
最后,就可以通过 Kibana,对自己的 Elasticsearch 中的数据进行可视化。
本文的实例是通过 SpringBoot+Dubbo 的微服务架构,结合 Elastic Stack 来整合日志的。架构如下:
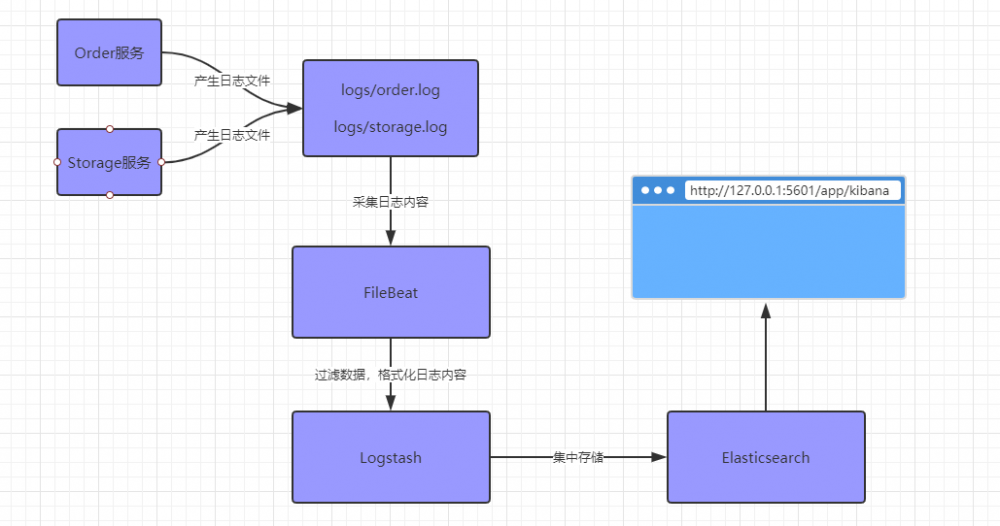
注意,阅读本文需要了解ELK组件的基本概念和安装。本文不涉及安装和基本配置过程,重点是如何与项目集成,达成上面的需求。
二、采集、转换
1、FileBeat
在SpringBoot项目中,我们首先配置Logback,确定日志文件的位置。
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${user.dir}/logs/order.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${user.dir}/logs/order.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern></pattern>
</encoder>
</appender>
复制代码
Filebeat 提供了一种轻量型方法,用于转发和汇总日志与文件。
所以,我们需要告诉 FileBeat 日志文件的位置、以及向何处转发内容。
如下所示,我们配置了 FileBeat 读取 usr/local/logs 路径下的所有日志文件。
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /usr/local/logs/*.log
复制代码
然后,告诉 FileBeat 将采集到的数据转发到 Logstash 。
#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["192.168.159.128:5044"] 复制代码
另外, FileBeat 采集文件数据时,是一行一行进行读取的。但是 FileBeat 收集的文件可能包含跨越多行文本的消息。
例如,在开源框架中有意的换行:
2019-10-29 20:36:04.427 INFO org.apache.dubbo.spring.boot.context.event.WelcomeLogoApplicationListener :: Dubbo Spring Boot (v2.7.1) : https://github.com/apache/incubator-dubbo-spring-boot-project :: Dubbo (v2.7.1) : https://github.com/apache/incubator-dubbo :: Discuss group : dev@dubbo.apache.org 复制代码
或者Java异常堆栈信息:
2019-10-29 21:30:59.849 INFO com.viewscenes.order.controller.OrderController http-nio-8011-exec-2 开始获取数组内容... java.lang.IndexOutOfBoundsException: Index: 3, Size: 0 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.get(ArrayList.java:433) 复制代码
所以,我们还需要配置 multiline ,以指定哪些行是单个事件的一部分。
multiline.pattern 指定要匹配的正则表达式模式。
multiline.negate 定义是否为否定模式。
multiline.match 如何将匹配的行组合到事件中,设置为after或before。
听起来可能比较饶口,我们来看一组配置:
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
multiline.pattern: '^/<|^[[:space:]]|^[[:space:]]+(at|/.{3})/b|^java.'
# Defines if the pattern set under pattern should be negated or not. Default is false.
multiline.negate: false
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
multiline.match: after
复制代码
上面配置文件说的是,如果文本内容是以 < 或 空格 或空格+at+包路径 或 java. 开头,那么就将此行内容当做上一行的后续,而不是当做新的行。
就上面的Java异常堆栈信息就符合这个正则。所以, FileBeat 会将
java.lang.IndexOutOfBoundsException: Index: 3, Size: 0 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.get(ArrayList.java:433) 复制代码
这些内容当做 开始获取数组内容... 的一部分。
2、Logstash
在 Logback 中,我们打印日志的时候,一般会带上日志等级、执行类路径、线程名称等信息。
有一个重要的信息是,我们在 ELK 查看日志的时候,是否希望将以上条件单独拿出来做统计或者精确查询?
如果是,那么就需要用到 Logstash 过滤器,它能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式。
那么,这时候就要先看我们在项目中,配置了日志以何种格式输出。
比如,我们最熟悉的JSON格式。先来看 Logback 配置:
<pattern>
{"log_time":"%d{yyyy-MM-dd HH:mm:ss.SSS}","level":"%level","logger":"%logger","thread":"%thread","msg":"%m"}
</pattern>
复制代码
没错, Logstash 过滤器中正好也有一个JSON解析插件。我们可以这样配置它:
input{
stdin{}
}
filter{
json {
source => "message"
}
}
output {
stdout {}
}
复制代码
这么一段配置就是说利用JSON解析器格式化数据。我们输入这样一行内容:
{
"log_time":"2019-10-29 21:45:12.821",
"level":"INFO",
"logger":"com.viewscenes.order.controller.OrderController",
"thread":"http-nio-8011-exec-1",
"msg":"接收到订单数据."
}
复制代码
Logstash 将会返回格式化后的内容:

但是JSON解析器并不太适用,因为我们打印的日志中msg字段本身可能就是JSON数据格式。
比如:
{
"log_time":"2019-10-29 21:57:38.008",
"level":"INFO",
"logger":"com.viewscenes.order.controller.OrderController",
"thread":"http-nio-8011-exec-1",
"msg":"接收到订单数据.{"amount":1000.0,"commodityCode":"MK66923","count":5,"id":1,"orderNo":"1001"}"
}
复制代码
这时候JSON解析器就会报错。那怎么办呢?
Logstash 拥有丰富的过滤器插件库,或者你对正则有信心,也可以写表达式去匹配。
正如我们在 Logback 中配置的那样,我们的日志内容格式是已经确定的,不管是JSON格式还是其他格式。
所以,笔者今天推荐另外一种:Dissect。
Dissect过滤器是一种拆分操作。与将一个定界符应用于整个字符串的常规拆分操作不同,此操作将一组定界符应用于字符串值。Dissect不使用正则表达式,并且速度非常快。
比如,笔者在这里以 | 当做定界符。
input{
stdin{}
}
filter{
dissect {
mapping => {
"message" => "%{log_time}|%{level}|%{logger}|%{thread}|%{msg}"
}
}
}
output {
stdout {}
}
复制代码
然后在 Logback 中这样去配置日志格式:
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS}|%level|%logger|%thread|%m%n
</pattern>
复制代码
最后同样可以得到正确的结果:

到此,关于数据采集和格式转换都已经完成。当然,上面的配置都是控制台输入、输出。
我们来看一个正儿八经的配置,它从 FileBeat 中采集数据,经由 dissect 转换格式,并将数据输出到 elasticsearch 。
input {
beats {
port => 5044
}
}
filter{
dissect {
mapping => {
"message" => "%{log_time}|%{level}|%{logger}|%{thread}|%{msg}"
}
}
date{
match => ["log_time", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["192.168.216.128:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
}
复制代码
不出意外的话,打开浏览器我们在Kibana中就可以对日志进行查看。比如我们查看日志等级为 DEBUG 的条目:

三、追踪
试想一下,我们在前端发送了一个订单请求。如果后端系统是微服务架构,可能会经由库存系统、优惠券系统、账户系统、订单系统等多个服务。如何追踪这一个请求的调用链路呢?
1、MDC机制
首先,我们要了解一下MDC机制。
MDC - Mapped Diagnostic Contexts ,实质上是由日志记录框架维护的映射。其中应用程序代码提供键值对,然后可以由日志记录框架将其插入到日志消息中。
简而言之,我们使用了 MDC.PUT(key,value) ,那么 Logback 就可以在日志中自动打印这个value。
在 SpringBoot 中,我们就可以先写一个 HandlerInterceptor ,拦截所有的请求,来生成一个 traceId 。
@Component
public class TraceIdInterceptor implements HandlerInterceptor {
Snowflake snowflake = new Snowflake(1,0);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler){
MDC.put("traceId",snowflake.nextIdStr());
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView){
MDC.remove("traceId");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex){}
}
复制代码
然后在 Logback 中配置一下,让这个 traceId 出现在日志消息中。
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS}|%level|%logger|%thread|%X{traceId}|%m%n
</pattern>
复制代码
2、Dubbo Filter
另外还有一个问题,就是在微服务架构下我们怎么让这个 traceId 来回透传。
熟悉 Dubbo 的朋友可能就会想到隐式参数。是的,我们就是利用它来完成 traceId 的传递。
@Activate(group = {Constants.PROVIDER, Constants.CONSUMER}, order = 99)
public class TraceIdFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String tid = MDC.get("traceId");
String rpcTid = RpcContext.getContext().getAttachment("traceId");
boolean bind = false;
if (tid != null) {
RpcContext.getContext().setAttachment("traceId", tid);
} else {
if (rpcTid != null) {
MDC.put("traceId",rpcTid);
bind = true;
}
}
try{
return invoker.invoke(invocation);
}finally {
if (bind){
MDC.remove("traceId");
}
}
}
}
复制代码
这样写完,我们就可以愉快的查看某一次请求所有的日志信息啦。比如下面的请求,订单服务和库存服务两个系统的日志。
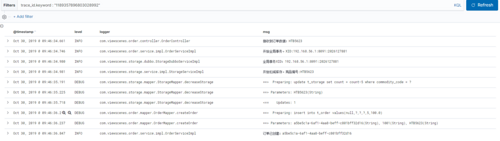
四、总结
本文介绍了 Elastic Stack 的基本概念。并通过一个 SpringBoot+Dubbo 项目,演示如何做到日志的集中化管理、追踪。
事实上, Kibana 具有更多的分析和统计功能。所以它的作用不仅限于记录日志。
另外 Elastic Stack 性能也很不错。笔者在一台虚拟机上,记录了100+万条用户数据,index大小为1.1G,查询和统计速度也不逊色。

正文到此结束
- 本文标签: 解析 参数 example NIO ELK 正则表达式 互联网 数据 App 快的 consumer constant Elasticsearch db 线程 UI 插件 provider message springboot 2019 windows tar 配置 需求 list dubbo ACE 分布式 Logback 服务器 js 安装 代码 value 开源 http Spring Boot 微服务 apache https map GitHub key 总结 统计 id ArrayList java git 集群 管理 json final core 希望 bug spring shell cat 开源项目 实例 开发 src IO Kibana logo servlet 产品 IDE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

