Java覆盖率 | Jacoco插桩的不同形式总结和踩坑记录

关于Jacoco的小结和踩坑记录
一、概述
测试覆盖率,老生常谈的话题。因为我测试理论基础不是很好,就不提什么需求覆盖率啦这样那样的主题了,直奔主题,咱主要指Java后端的测试覆盖率。
由于历史原因,公司基本不做UT,所以对测试来说,咱最关心的还是手工执行、接口执行(人工Postman之类的)、接口自动化、WebUI自动化对一个应用系统的覆盖度。
此文也是对另一篇文章关于Java端覆盖率探索的一个细化,当时主要是为了描述App端的踩坑,所以关于服务端一笔带过了,现得空详细补充一下。
小记 Java 服务端和 Android 端手工测试覆盖率统计的实现
二、站在巨人的肩膀上
本文提到的内容,多数还是得力与站在巨人的肩膀上。
国际惯例,感谢以下文章带来的灵感:
有赞测试 浅谈代码覆盖率
地址:https://testerhome.com/articles/16981
腾讯移动品质中心TMQ [腾讯 TMQ] JAVA 代码覆盖率工具 JaCoCo-踩坑篇
地址:https://testerhome.com/topics/5876
腾讯移动品质中心TMQ [腾讯 TMQ] JAVA 代码覆盖率工具 JaCoCo-实践篇
地址: https://testerhome.com/topics/5823
测试覆盖率 代码变更覆盖率平台-针对手工测试的代码变更覆盖率实现之路
地址: https://testerhome.com/topics/19077
以上等等,都是在覆盖率这个坑里蹲着的时候,给我递了绳子的,也让我顺利从坑里爬了出来!谢谢
三、写本文的初衷
本来Jacoco已经流行了很多年了,各种文档和帖子已经描述的很完美了,但是多数文章都是针对某一特定形式做了总结和使用。相信很多负责整个公司项目的覆盖率任务的人们来说,还是要一种一种去研究、去应对,入坑、出坑不厌其烦。
也得益于今年上半年一直负责整个公司不同类型的项目的覆盖率统计技术的适配,对不同形式的项目均有一定的了解,在此记录一下,也不让千疮百孔的自己浪费掉这半年的精力,如果说可以帮到别人一星半点,那这篇文章就算是造福了。
由于本人能力有限、表达能力有限,也难免在文中会有错别字、技术描述不到位、或者总结有误的地方,还请大家原谅则个,我也争取不误导大家。
四、 投入覆盖率之前的思路
因为之前了解过一部分Jacoco的机制,也知道它提供了很多强大的功能,以满足不同形式的项目。但归根结底,Jacoco提供了api,可以让大家屏蔽不同类型的项目带来的困扰。
Jacoco官方的Api示例
地址: https://www.jacoco.org/jacoco/trunk/doc/api.html
个人认为,以Api的方式来进行操作,可以有以下好处:
可以屏蔽不同方式的构建部署,如果你想把这个功能做成平台,那api想必是很好的一种方式。
也就是说,我只需要把jacoco插桩到测试服务器上,暴露tcp的ip和端口,剩余的提取代码执行数据、生成覆盖率报告,就可以用统一的方式进行就好了。
众所周知,jacoco官方提供了Maven插件方式、Ant的xml方式,均有对应的dump和report来进行覆盖率数据的dump和报告生成,如果有兴趣可以研究一下,我也不过于啰嗦。
五、对我司项目的梳理
我在另一篇关于覆盖率文章中有提到,我司是个老牌公司,项目杂乱无章,技术五花八门。截至2019年9月23日仍然有j泡在jdk6上的。所以我个人认为,影响jacoco使用过程的,可能存在于以下几点。
-
jdk版本。我司现有jdk6、7、8.但实际上jdk6是个分水岭,其他的都基本可以用jdk8来适配。
-
构建工具。我司现有Maven构建、ANT构建,想必有的公司还有用gradle的。
-
部署方式。Ant、Maven插件启动、java -jar启动、tomcat启动war包(打包方式就随便了)
稍后内容也都基于这几种不同实现方式做描述。如果接触项目多的,基本就知道,很多时候测试还是不介入测试环境的发布,这一方面源于开发的不信任,他们认为发布还是要抓在开发自己手里;另一方面也源于测试人员能力的跟不上,至少在我司很多测试人员确实不太懂如何发布(虽然现在慢慢有所缓解,越来越都的测试人员都从开发手中接了过来)。
线上部署、测试部署、开发部署,这几个不同场景,可能用的方式都不同,至少在我接触的项目大都是这样。开发喜欢用插件的方式启动部署,因为快嘛,而且IDE也支持,右键运行一下基本在ide就启动了,想想看如果你是开发,在你本地IDE里调试的时候,需要打个war包然后丢到tomcat里,再启动tomcat,你也不太乐意。
六、jacoco插桩的本质
废话不多说,步入正题。
在上面提到的几篇文章里,多数都提到了jacoco介入部署过程的本质,就是插桩,至于怎么插桩,那就跟接入阶段有关系了。可以是编译时插桩、也可以是运行时插桩,这就是所谓Offline模式和On-the-fly模式,我们也不过多于纠结,我们选择on-the-fly模式。
所以归结到本质,jacoco的on-the-fly模式的插桩过程,其实就是在测试环境部署的时候,让jacoco的相关工具,介入部署过程,也就是介入class文件的加载,在加载class的时候,动态改变字节码结构,插入jacoco的探针。
本质:jacoco以tcpserver方式进行插桩的本质,就是如果应用启动过程中,进行了jacoco插桩,且成功了。它会在你当前这个启动服务器中,在一个端口{$port}上,开启一个tcp服务,这个tcp服务,会一直接收jacoco的执行覆盖率信息并传到这个tcp服务上进行保存。他既然是个tcp服务,那jacoco也提供了一种以api的方式连接到这个tcp服务上,进行覆盖率数据的dump操作。
(细节可能描述的不是很精确,但差不多就是这么个过程。这个tcp服务,在你没有关闭应用的时候,是一直开着的,可以随时接受连接)
那最后再本质一点,就是介入下面这个命令的启动过程:
java -jar
那问题就好办了,一种一种来对应起来。
七、 不同形式的插桩配置
提到介入启动过程,那就免不了提一下一个jar包。
jacocoagent.jar
下载地址:https://www.eclemma.org/jacoco/
下载后解压文件夹里,目录如下:

这个jacocoagent.jar,就是启动应用时主要用来插桩的jar包。
请注意不要写错名称,里面有个很像的jacocoant.jar,这个jar包是用ant xml方式操作jacoco时使用的,不要混淆。
以测试环境部署在linux服务器上为例,如果想在windows上测试也可以,把对应的值改成windows上识别的即可。
假设jacocoagent.jar的存放路径为:/home/admin/jacoco/jacocoagent.jar
以下都以$jacocoJarPath来替代这个路径,请注意这个路径不是死的,你可以修改。
依然是基于上述的几种不同方式,那我们针对不同形式·做插桩,也就是改变这几种不同形式的底层启动原理,也就是改动不同方式的java的启动参数,这对每一种启动方式都不太一样。但是改动java启动参数本质也是一样的,就是在java -jar启动的时候,加入-javaagent参数
-javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1"
换成实际的信息为如下,请注意替换真实路径, 这一句是需要介入应用启动过程的主要代码,针对每种不同的部署方式,需要加到不同的地方
-javaagent:/home/admin/jacoco/jacocoagent.jar=includes=*,output=tcpserver,port=2014,address=192.168.110.1
7.1 这句话的解释
-
-javaagent
jdk5之后新增的参数,主要用来在运行jar包的时候,以一种方式介入字节码加载过程,如有兴趣自行百度。注意后面有个冒号:
-
/home/admin/jacoco/jacocoagent.jar
需要用来介入class文件加载过程的jar包,想深入了解的,百度“插桩”哈。
这是一个jar包的绝对路径。
-
includes=*
这个代表了,启动时需要进行字节码插桩的包过滤,*代表所有的class文件加载都需要进行插桩。
假如你们公司内部代码都有相同的包前缀:com.mycompany
你可以写成:
includes=com.mycompany.*
-
output=tcpserver
这个地方不用改动,代表以tcpserver方式启动应用并进行插桩
-
port=2014
这是jacoco开启的tcpserver的端口,请注意这个端口不能被占用
-
address=192.168.110.1
这是对外开发的tcpserver的访问地址。可以配置127.0.0.1,也可以配置为实际访问ip
配置为127.0.0.1的时候,dump数据只能在这台服务器上进行dump,就不能通过远程方式dump数据。
配置为实际的ip地址的时候,就可以在任意一台机器上(前提是ip要通,不通都白瞎),通过ant xml或者api方式dump数据。
举个栗子:
我如上配置了192.168.110.1:2014作为jacoco的tcpserver启动服务,
那我可以在任意一台机器上进行数据的dump,比如在我本机windows上用api或者xml方式调用dump。
如果我配置了127.0.0.1:2014作为启动服务器,那么我只能在这台测试机上进行dump,其他的机器都无法连接到这个tcpserver进行dump。
-
总结:
这句内容,如下,格式是固定的, 只有括号内的东西方可改变 ,其它尽量不要动,连空格都不要多:
-javaagent:(/home/admin/jacoco/jacocoagent.jar)=includes=(*),output=tcpserver,port=(2014),address=(192.168.110.1)
比如我可以改成其他的: ```shell -javaagent:/home/admin/jacoco_new/jacocoagent.jar=includes=com.company.*,output=tcpserver,port=2019,address=192.168.110.111
注意其他地方基本不用改动。
7.2 war包方式启动
tomcat的war包方式启动,假设tomcat路径为:$CATALINA_HOME= /usr/local/apache-tomcat-8.5.20,我们常用的命令存在于:$CATALINA_HOME/bin下,有startup.sh和shutdown.sh(windows请自觉改为bat,后续不再声明),其实这两个只是封装之后的脚本,底层调用的都是$CATALINA_HOME/bin/catalina.sh(或者bat),如图源码:
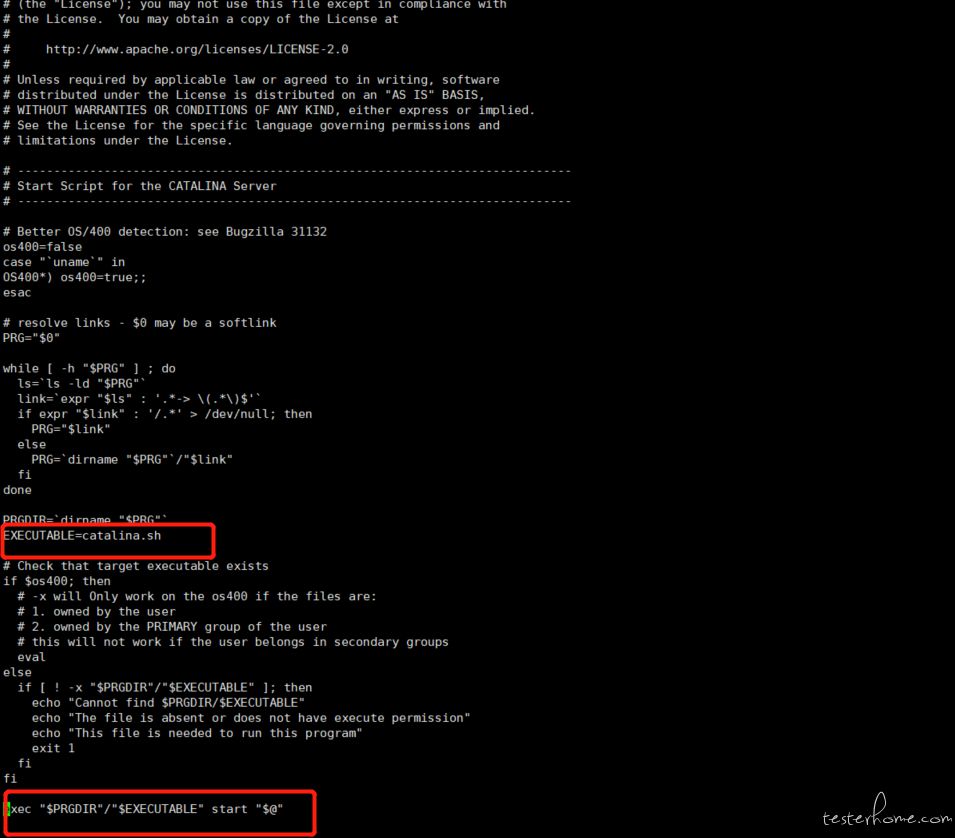
因此,只需要改动catalina.sh中的启动参数即可。
前面提到过,主要改动主要是改动java -jar, tomcat是通过一个JAVA_OPTS参数来控制额外的java启动参数的,我们只需要在合适的地方把上面的启动命令追加到JAVA_OPTS即可
打开catalina.sh,找到合适的地方修改JAVA_OPTS参数:
理论上,任何地方修改JAVA_OPTS参数均可,但我们实验过后,在以下位置加入,是一定可以启动成功的,当然您也可以尝试其他位置.
JAVA_OPTS="$JAVA_OPTS -Dorg.apache.catalina.security.SecurityListener.UMASK=`umask`"
源脚本中有这个注释掉的地方,我们在下方修改JAVA_OPTS:
在其下方,加一句:
JAVA_OPTS="$JAVA_OPTS -javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1"
改完之后如下所示:

改完之后,就可以进行startup.sh的启动了,应用启动成功之后,可以在服务器上进行调试,查看tcpserver是否真的起来了。
判别方式如下(该图中是现有的已经开启的服务,所以ip和端口跟前面的命令不一样,这点请注意,这里只是为了展示;后续几种方式判别方式相同,不再赘述了哈),这个端口在应用启动时被占用,在应用关闭时被释放,这个请注意检查:
如此,这个端口已经在监听了,证明这个测试环境已经把jacoco注入进去,那你对该测试环境的任何操作,代码执行信息都会被记录到这个ip:port开启的tcp服务中。
7.3 Maven命令的插件启动方式
在我司,有的开发会喜欢用插件方式启动,在代码pom文件层级中,运行如下命令:
mvn clean install mvn tomcat7:run -Dport=xxx
或者还有
mvn clean install mvn spring-boot:run -Dport=xxx
这两套命令,本质上没什么差别,只是运行插件不一样,具体用什么命令,如果不清楚,最好是跟开发请教一下。
他们的意思是,在当前代码的pom文件层级运行,意思是通过maven的tomcat插件启动这个服务,这个服务启动在端口xxx上,注意这个端口是应用的访问端口,和jacoco的那个端口不是一回事.
对这种方式注入jacoco,也是可以的。这种可以不用修改任何的配置文件,只需要在你启动的时候,临时修改变量就行了。
这种方式改变java的启动参数方式是这样:
export MAVEN_OPTS="-javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1"
这句命令加在哪里呢?就是run之前。为什么呢,因为这样一改,你的所有的mvn命令都会生效,但其实我们只想介入启动过程。
因此,前面提到的两套启动命令,就可以改成如下方式:
mvn clean install export MAVEN_OPTS="-javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1" mvn tomcat7:run -Dport=xxx export MAVEN_OPTS=""
和
mvn clean install export MAVEN_OPTS="-javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1" mvn spring-boot:run -Dport=xxx export MAVEN_OPTS=""
当然,你的run命令,也可能是其他变种,比如:nohup mvn .... & 这种后台启动的方式,也是可以的。
最后修改为""是因为担心对后续的mvn命令产生影响,其实如果你切换了terminal窗口,这个临时变量就会失效,不会对环境造成污染。
如果应用启动成功了,就可以按照前面的方式,netstat判别一下tcp服务是否真的启动。
如果你设置了这个变量的位置不对,那你用mvn命令的时候,可能会出现如下的异常:
java.net.BindException: Address already in use: bind
这时候,就需要去检查一些,你配置的jacoco端口是不是在启动应用服务时已经被占用。
或者你临时设置了MAVEN_OPTS这个变量,启动之后又没有改回来,然后接着运行了mvn命令,这时候也会出现这种错误。
这里请务必关注。
提一句题外话,ANT的方式是不是也可以通过临时修改ANT_OPTS参数进行启动(因为ANT和MAVEN本是一家子吗,我才底层可能差异不是很大),我不曾做尝试,有兴趣的可以尝试下
7.4 ANT构建,通过xml配置文件启动
这种方式可能实现启动应用的阶段不同,但大都配置在build.xml里,这里请根据不同的项目做不同的适配.
它的原理是,在ant的启动target中,有个标签,给它增加一个jvmarg参数的子标签,如下代码:
<jvmarg value=”-javaagent:$jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1” />
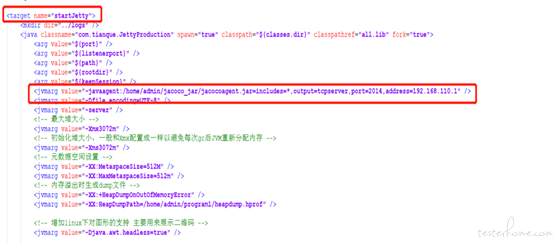
比如我们的启动命令是这样:
ant -f build.xml clean build startJetty
以此启动之后,将会注入jacoco的代理,最终可以按照上面的方式判断端口是否启动。
7.5 java -jar方式启动
这种最简单直接:
java -javaagent: $jacocoJarPath=includes=*,output=tcpserver,port=2014,address=192.168.110.1 -jar xxxxxxxxxx.jar
注意,javaagent参数,一定要在jar包路径之前,尽量在-jar之前,不然可能不会生效。
请注意java -jar命令的使用方式,在jar包前面传进去的是给jvm启动参数的,在jar包之后跟的是给main方法的。
启动后,依然按照前面的方式判断是否启动了监听端口。
八、关于启动之后
启动之后,就进行测试就可以了,跟平常不注入jacoco代理是无异的。
九、关于注意事项(可能前面有啰嗦重复的,但需要注意)
-
修改JAVA_OPTS参数时,如果位置不对,可能造成代理无法启动。
-
java -jar启动时,-javaagent参数,不能错误,否则可能造成代理不生效
-
Export MAVEN_OPTS参数时,后续的所有mvn命令,都会带上此参数,因此相当于每次执行mvn命令,都会尝试启动代理,因此可能会出现address bind already in use之类的异常抛出。因此,我们只有在mvn tomcat7:run启动服务器时才需要启动代理,其他如mvn的编译、install命令都不需要,所以在启动之后,把MAVEN_OPTS参数置空,或者重启一个terminal来执行命令
-
同一个ip地址上,部署多套服务器需要收集覆盖率时,端口自己规划好,不可重复。
-
测试执行信息的收集(在应用的测试服务器)
-
测试执行信息的获取、以及生成覆盖率报告(可在测试服务器上、也可在统一的服务器上)
-
5的收集在测试服务器上,6的操作可以在测试服务器是,也可以是统一的服务器(我们选择后者)。
-
关闭应用服务时,务必不要强杀,请使用kill -15 杀进程(当然有时候,会出现kill -15 杀不掉进程的时候,用kIll -9 也无妨,这一点并不是很确定),否则,很有可能会造成覆盖率数据来不及保存而丢失。
十、说给想做平台的你
按照原来的流程,如果想做增量的覆盖率,那么有如下的步骤需要涉及,我们需要做的事情:
-
部署测试服务器(加入jacoco的代理,按照上面的方式进行即可) 2 需要知道上述部署时的版本代码,需要知道待比较的基线版本代码,并下载两个代码到某个路径下,并编译最新的代码(至于需不需要编译,看你的需求,也可以用测试服务器上的,这样最准确。现编译的话,可能会编译机跟测试机的不同,造成生成的class文件不一致,这会导致覆盖率数据不准确)
-
Dump覆盖率执行数据
-
根据dump出来的执行数据exec文件,以及刚才对最新代码的编译出来的字节码class文件和src中的源代码进行报告生成
-
导出覆盖率数据报告(一般是在linux中执行,查看时需要到自己的windows或者mac上查看) 以上五个步骤,对获取覆盖率数据缺一不可,不然无法出增量覆盖率数据。
那么上述的步骤,其实可以都进行自动化配置。
-
部署。
如果有devops平台的话,可以集成进去,端口要规划好。
-
基线代码、和最新代码
可以用jgit和svnkit这两个工具进行代码下载和克隆。
-
dump.
用API去dump,可以屏蔽不同启动方式,只需要有tcp的serverip和端口即可。
-
report。
用jacoco的api做。
那唯一的差别,就是对项目层级的判定,比如多模块、比如可能项目的目录并不规范(有的maven项目并没有把所有的代码放到src/main/java下),这些需要自己对公司项目进行适配。
我司就是因为项目结构差别太大,所以适配的过程花了一番功夫。
5 导出报告。
提供下载,或者给出服务器存放的链接,都行,这个看个人实现就行了。
十一、一些坑
-
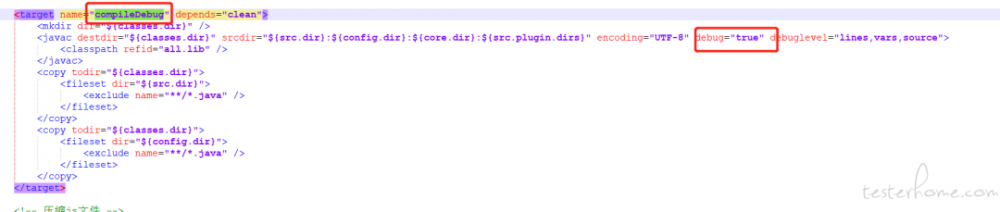
ant构建
build.xml中,有特定的compile阶段,这个自己去找。
请务必保证,有
debug="true"
这个配置,不然,jacoco是无法注入的,有的时候ant项目生成的数据为0,就可以去排查下这里。
如我司配置了两个,一个compileDebug,一个compile,在compileDebug阶段打开了debug的开关:
-
关于负载均衡
有时候可能一个服务会有负载均衡出现,那么可以配置不同端口,如果在不同服务器上,那么IP和端口都可以不同。
这时候,在dump数据的时候,只需要循环几个ip:port(至于你想怎么传,那就是代码层面事情了)去dump,保存到同一个文件中就行了。
-
做平台时-项目代码无法独立编译
这个看怎么解决了,如果非要自己编译,那就让开发适配到可以独立编译。
我这里是提供了sftp下载的方式,你告诉我你的代码在哪个服务器的那个路径,提供给我用户名密码,我用java的方式去sftp下载到平台部署的机器上。
这样可以解决现编译的不匹配问题,也可以解决无法独立编译的问题。
但是有几个遗留问题,你如何判定是不是要重新下载,你也会担心sftp下载下来的class和java代码跟测试机上的是否不一样。这个要看个人取舍,理论上tcp进行下载还是安全的。
-
如果注入jacoco的配置之后,端口确实没有起来或者dump的时候,tcpserver连接不上
可能原因有几种。
-
Tcp端口确实没起来,这个在部署测试服务器的文档里有说明,部署后需要查看下是否真的起来。
-
Tcp端口确实起来了,netstat查看的时候也是显示正确。这种还有两种可能。
-
确保javaagent参数中的address写的是真实ip地址,而不是127.0.0.1或者localhost。
-
防火墙。防火墙开启的时候,阻碍了外部ip连接的进入,请关闭防火墙,或者配置防火墙策略。
-
覆盖率数据会丢失或者不准确
举个栗子。
8:30的时候,执行了测试,生成了一次报告。此时8.30之前的数据,肯定是存在的。
9:00的时候,重新部署了,之前没有再次捞取执行信息,那重启之后,8.30-9.00之间的执行记录可能很大概率丢失。
所以,务必小心。
-
怎么确保报告准确,且尽量减少丢失?
及时保存,及时收集,可以采用定时任务的方式。
-
应用的突然重启和服务器的断电状况怎么处理?
天灾,没招。如果真的确实需要,可以在程序中加入定时收集,但是频率不一定好控制,而且当不再执行的时候,平白重复保存完全一模一样的执行信息,个人觉得意义不大,会对服务器磁盘造成巨大压力。具体解决方案还要看个人取舍。
-
造成覆盖率报告数据不准确的原因有哪些?
最最最最底层的原因。部署时的class文件和生成报告的时候,用的class文件不一致。有以下几种情况:
-
测试服务器(就是你的应用所在的那个环境)中的class文件和我管理平台上编译环境不一致,导致产生的class文件跟部署时的class文件有差异。这个可以通过不手动编译,而是从 测试服务器部署位置的目录来拷贝传输,来解决,但现阶段,没做。
-
测试服务器版本变更了,但是管理平台上的代码没变更(或者说新代码拉取下来了,但是没有重新编译。),导致class文件不一致
-
管理平台上的新版本代码的版本号没有填写,默认每次拉取最新代码,这会导致生成报告的时候,源码变了,class文件没变,覆盖率插桩收集的时候,用的还是老代码 所以,要想准确。需要保证,测试服务器部署时的代码版本和管理平台上写的版本号完全一致。
不知不觉,又写了这么多,哎,表达能力不行,又啰嗦了。不早了,先写到这里,稍后想到,再作补充吧~~~~~~
十二、补充一些API相关的代码
PS: 2019年9月24日 09:20追加一些用到的源码,昨天写完22:20了,着急赶末班车,就没来得及,今天补上一些。
覆盖率数据的获取
import org.jacoco.core.tools.ExecDumpClient;
import org.jacoco.core.tools.ExecFileLoader;
...
public void dumpExecDataToFile(String filePath) {
logger.debug("开始dump覆盖率信息:{},到:{}文件中", this.jacocoAgentTcpServer,
filePath);
ExecDumpClient dumpClient = new ExecDumpClient();
dumpClient.setDump(true);
ExecFileLoader execFileLoader = null;
try {
execFileLoader = dumpClient.dump(
this.jacocoAgentTcpServer.getJacocoAgentIp(),
this.jacocoAgentTcpServer.getJacocoAgentPort());
// 这个后面的true,代表如果这个文件已经存在,且以前已经保存过数据,那么是可以追加的,也相当于覆盖率数据文件的合并
//如果设置为false,则会重置该文件,这在多节点负载均衡的时候尤其有用,可以把多个节点的数据组合合并之后再进行统计
execFileLoader.save(new File(filePath), true);
} catch (IOException e2) {
logger.error("获取dump信息失败:{}", e2.getMessage());
throw new BusinessValidationException("tcp服务连接失败,请查看tcp配置");
}
}
另外可以根据自己的需要,看下是否把以前的覆盖率数据做备份(我们现在是做了备份、且做了定时dump,防止覆盖率数据突然丢失),需要的时候从备份数据里拿,再从tcpserver中dump,然后做合并,这个过程可能统计全量的时候尤其需要。
CodeCoverageDTO.java
该文件主要封装覆盖率数据生成报告的时候需要的一些属性,如数据文件、src源码、class文件、报告存放文件等等。
import java.io.File;
/**
* @author : Administrator
* @since : 2019年3月6日 下午7:53:02
* @see :
*/
public class CodeCoverageFilesAndFoldersDTO {
private File projectDir;
/**
* 覆盖率的exec文件地址
*/
private File executionDataFile;
/**
* 目录下必须包含源码编译过的class文件,用来统计覆盖率。所以这里用server打出的jar包地址即可
*/
private File classesDirectory;
/**
* 源码的/src/main/java,只有写了源码地址覆盖率报告才能打开到代码层。使用jar只有数据结果
*/
private File sourceDirectory;
private File reportDirectory;
private File incrementReportDirectory;
public File getProjectDir() {
return projectDir;
}
//省略了getter和setter
}
ReportGenerator.java
这里生成报告的时候,其实默认应该已经有源码、exec文件、class文件了,至于class文件什么时候编译出来的或者怎么出来的,那应该在生成报告的前置步骤已经做好了。
private static void createReportWithMultiProjects(File reportDir,
List<CodeCoverageFilesAndFoldersDTO> codeCoverageFilesAndFoldersDTOs)
throws IOException {
logger.debug("开始在:{}下生成覆盖率报告", reportDir);
File coverageFolderFile = reportDir;
if (coverageFolderFile.exists()) {
FileUtil.forceDeleteDirectory(coverageFolderFile);
}
HTMLFormatter htmlFormatter = new HTMLFormatter();
IReportVisitor iReportVisitor = null;
boolean everCreatedReport = false;
for (CodeCoverageFilesAndFoldersDTO codeCoverageFilesAndFoldersDTO : codeCoverageFilesAndFoldersDTOs) {
// class文件为空或者不存在
boolean classDirNotExists = (null == codeCoverageFilesAndFoldersDTO
.getClassesDirectory())
|| (!(codeCoverageFilesAndFoldersDTO.getClassesDirectory()
.exists()));
// class文件目录不存在
boolean needNotToCreateReport = classDirNotExists;
if (needNotToCreateReport) {
logger.debug("目录:{}没有class文件,不生成报告",
codeCoverageFilesAndFoldersDTO.getProjectDir()
.getAbsolutePath());
continue;
}
// 修改标志位
everCreatedReport = true;
logger.debug("正在为:{}生成报告", codeCoverageFilesAndFoldersDTO
.getProjectDir().getAbsolutePath());
IBundleCoverage bundleCoverage = analyzeStructureWithOutChangeMethods(
codeCoverageFilesAndFoldersDTO);
ExecFileLoader execFileLoader = getExecFileLoader(
codeCoverageFilesAndFoldersDTO);
iReportVisitor = htmlFormatter
.createVisitor(new FileMultiReportOutput(
new File(coverageFolderFile.getAbsolutePath(),
codeCoverageFilesAndFoldersDTO
.getProjectDir().getName())));
if (null != execFileLoader) {
iReportVisitor.visitInfo(
execFileLoader.getSessionInfoStore().getInfos(),
execFileLoader.getExecutionDataStore().getContents());
}
//这个地方之所以没有用一个固定的文件夹来指定,是因为我们的项目有的不标准,如果你们的项目是标准的,比如都在src/main/java下,那就可以直接用一个固定值
//我们这里为了防止src/java src/java/plugin src/plugin这种层级的源码出现,才做了适配
ISourceFileLocator iSourceFileLocator = getSourceFileLocatorsUnderThis(
codeCoverageFilesAndFoldersDTO.getSourceDirectory());
iReportVisitor.visitBundle(bundleCoverage, iSourceFileLocator);
iReportVisitor.visitEnd();
}
if (!everCreatedReport) {
throw new BusinessValidationException("从未生成报告,检查下工程是否未编译或者是否都是空工程");
}
}
private static ISourceFileLocator getSourceFileLocatorsUnderThis(
File topLevelSourceFileFolder) {
MultiSourceFileLocator iSourceFileLocator = new MultiSourceFileLocator(
4);
//这里是获取当前给出的目录以及其下面的子目录中所包含的所有java文件
//实现方式其实就是递归遍历文件夹,并过滤出来java文件,写法比较简单就不贴了,自行实现即可
List<File> sourceFileFolders = getSourceFileFoldersUnderThis(
topLevelSourceFileFolder);
for (File eachSourceFileFolder : sourceFileFolders) {
iSourceFileLocator
.add(new DirectorySourceFileLocator(eachSourceFileFolder,
GlobalDefination.CHAR_SET_DEFAULT, 4));
}
return iSourceFileLocator;
}
如果确实需要有些实现的源码,可以联系我或者从github上获取。
代码示例:https://github.com/yelanting/ManagerPlatformAdministrator.git
备注:
这里关于Jacoco的一部分代码直接引用了AngryTester(https://testerhome.com/AngryTester)的代码,如果涉及到侵权请联系我,不过当前是为了个人使用,并不涉及商业,还望见谅~~~
关于server部分的,则大部分是我自己练习的代码,可以随意拿去用~~~
这个小工具只是为了给测试内部使用,其实并不具备完整项目的实力,所以代码和性能不一定很好,但我尽量按照阿里的规范来编写的代码,使其规范。
AngryTesterJacoco的代码-org.jacoco.core.diff.DiffAST.java
这是代码比对源码,
public static List<MethodInfo> diffDir(final String ntag,
final String otag) {// src1是整个工程中有变更的文件,src2是历史版本全量文件,都是相对路径,例如在当前工作空间下生成tag1和tag2
final String pwd = new File(System.getProperty("user.dir"))
.getAbsolutePath();// 同级目录
final String parent = new File(System.getProperty("user.dir")).getParent();
final String tag1Path = pwd;
final String tag2Path = parent + SEPARATOR + otag;
final List<File> files1 = getFileList(tag1Path);
for (final File f : files1) {
// 非普通类不处理
if (!ASTGeneratror.isTypeDeclaration(f.getAbsolutePath())) {
continue;
}
//实现方法在这里,主要是做了路径的替换
final File f2 = new File(
tag2Path + f.getAbsolutePath().replace(tag1Path, ""));
diffFile(f.toString(), f2.toString());
}
return methodInfos;
}
/**
* @param baseDir 与当前项目空间同级的历史版本代码路径
* @return
*/
public static List<MethodInfo> diffBaseDir(final String baseDir) {
final String pwd = new File(System.getProperty("user.dir"))
.getAbsolutePath();// 同级目录
final String parent = new File(System.getProperty("user.dir")).getParent();
final String tag1Path = pwd;
final String tag2Path = parent + SEPARATOR + baseDir;
final List<File> files1 = getFileList(tag1Path);
for (final File f : files1) {
// 非普通类不处理
if (!ASTGeneratror.isTypeDeclaration(f.getAbsolutePath())) {
continue;
}
final File f2 = new File(
tag2Path + f.getAbsolutePath().replace(tag1Path, ""));
diffFile(f.toString(), f2.toString());
}
return methodInfos;
}
/**
* 对比文件
*
* @param nfile
* @param ofile
* @return
*/
public static List<MethodInfo> diffFile(final String nfile,
final String ofile) {
final MethodDeclaration[] methods1 = ASTGeneratror.getMethods(nfile);
if (!new File(ofile).exists()) {
for (final MethodDeclaration method : methods1) {
final MethodInfo methodInfo = methodToMethodInfo(nfile, method);
methodInfos.add(methodInfo);
}
} else {
final MethodDeclaration[] methods2 = ASTGeneratror
.getMethods(ofile);
final Map<String, MethodDeclaration> methodsMap = new HashMap<String, MethodDeclaration>();
for (int i = 0; i < methods2.length; i++) {
methodsMap.put(
methods2[i].getName().toString()
+ methods2[i].parameters().toString(),
methods2[i]);
}
for (final MethodDeclaration method : methods1) {
// 如果方法名是新增的,则直接将方法加入List
if (!isMethodExist(method, methodsMap)) {
final MethodInfo methodInfo = methodToMethodInfo(nfile,
method);
methodInfos.add(methodInfo);
} else {
// 如果两个版本都有这个方法,则根据MD5判断方法是否一致
if (!isMethodTheSame(method,
methodsMap.get(method.getName().toString()
+ method.parameters().toString()))) {
final MethodInfo methodInfo = methodToMethodInfo(nfile,
method);
methodInfos.add(methodInfo);
}
}
}
}
return methodInfos;
}
public static String MD5Encode(String s) {
String MD5String = "";
try {
MessageDigest md5 = MessageDigest.getInstance("MD5");
BASE64Encoder base64en = new BASE64Encoder();
MD5String = base64en.encode(md5.digest(s.getBytes("utf-8")));
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return MD5String;
}
/**
* 判斷方法是否一致
*
* @param method1
* @param method2
* @return
*/
public static boolean isMethodTheSame(final MethodDeclaration method1,
final MethodDeclaration method2) {
if (MD5Encode(method1.toString())
.equals(MD5Encode(method2.toString()))) {
return true;
}
return false;
}
上面最后一个方法就是拿方法的详细信息来做md5的比对,所以这也就有了评论区的那个方法误判变更的来由。
不过这属于历史遗留问题,并不能算大事,想办法规避即可。

↙↙↙阅读原文可查看相关链接,并与作者交流
正文到此结束
- 本文标签: http Property 本质 目录 Agent 服务器 2019 db shell 进程 调试 注释 XML 百度 Security bug linux 字节码 备份 部署 端口 SVN tar UI 需求 遍历 总结 ask message id JVM 探针 递归 windows tomcat 配置 代码 Android final 统计 maven构建 服务端 equals web UTC tab mina 负载均衡 map GitHub HTML 开发 core 下载 MQ session apache tag 源码 jetty https 安全 API App 参数 src 文章 IO HashMap java 代码覆盖率 启动过程 pom git 功夫 管理 CTO 插件 client ACE plugin bus spring 覆盖率 测试 maven struct cat IDE 空间 list build SFTP ORM javaagent rmi 测试环境 编译 自动化 ip 压力 数据 TCP value ftp
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

