秒级容灾,UCloud 内网高可用服务之三代架构演进 | U刻
技术分享
/
秒级容灾,UCloud 内网高可用服务之三代架构演进
<返回
-
秒级容灾,UCloud 内网高可用服务之三代架构演进
栏目:技术分享
快节奏的生活,任何的业务异常 / 中断都是不能容忍的。
在无人化超市选购完成进行结账时,结账页面突然卡住,无法完成购买操作。这时该选择放弃手中的商品 or 继续等待?
酒店办理入住时,管理系统突然崩溃,无法查询预订记录,导致办理入住受到影响,酒店前台排起了长队……
高可用与我们每个人都是息息相关的,在即将到来的双十一,更是对各个电商的业务可用性提出了更高的要求。对此,UCloud 提供基于内网 VIP 的高可用服务,内网 VIP 通过前后三代广播集群的设计演进,解决了复杂异构 Overlay 网络下的广播实现问题,获得秒级高可用切换能力,并能够很好的支持物理云。
下面,本文将对 UCloud 秒级切换的内网高可用服务进行详细介绍。
基于内网 VIP 的高可用服务
1、高可用的理念和要点
从业务角度看,当然要尽可能避免应用出现故障。但要完全不出故障是不可能的。
那如何解决这个问题呢?答案就是相信任何单一节点都不可靠,要为每个节点增加备份。当任一节点发生故障时,业务自动切换至正常节点,且整个切换过程用户均无感知,这就是高可用的基本理念。 而实现高可用的两个要点是备份节点和自动故障转移。
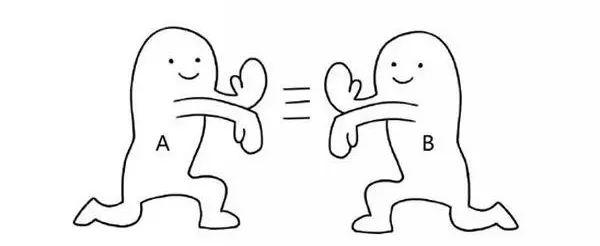
图:一旦 A 发生故障,便会迅速切换至 B
2、传统网络的高可用方案
在传统网络中,Keepalived + 虚拟 IP 是一个经典的高可用解决方案。
Keepalived 是基于 VRRP 协议的一款高可用软件,有一台主服务节点和多台备份节点,并部署相同的服务。主节点对外使用一个虚拟 IP 提供服务,当主节点出现故障时,Keepalived 发起基于 VRRP 的协商,选择备节点升级为主节点,虚拟 IP 地址会自动漂移至该节点,同时利用 GARP 宣告虚拟 IP 的位置信息更新,从而保证服务正常。
3、云计算 Overlay 网络下的高可用
云计算下的网络架构发生了巨大变化,传统的网络架构已经更新为 Overlay 网络,并出现了各类复杂的异构网络。那么在新的网络环境下,该如何解决高可用这个问题呢?
首先我们看一下云计算网络的基本原理:
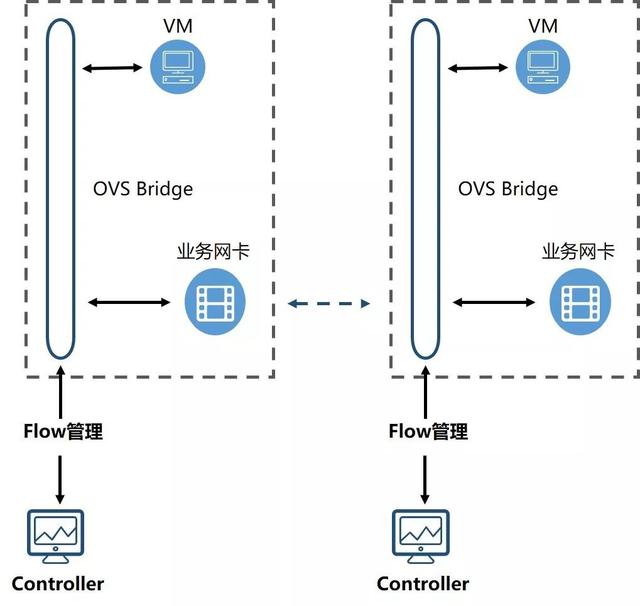
图:云计算网络的实现
如上图,云资源都桥接在 OVS 的网桥上,同时业务网卡也桥接在 OVS 的网桥上,Controller 为 UCloud 基于开源框架 Ryu 自研实现。Controller 通过与后台 Manager 的交互,拉取 ACL、路由表、VPC 联通、隔离等各类信息,并通过 OVS Message 将 Flow 固化在 OVS 的网桥上,达到 Flow 管理的目的,实现 ACL 的联通与阻断、三层转发的功能,进而完成 VPC 联通及租户隔离的能力。上层的实际业务报文,通过 GRE 封装,对下层网络保证透明。
鉴于用户在云计算网络中实现高可用的复杂性,UCloud 设计了内网 VIP 产品,为云平台上的云主机、物理云主机提供服务。 作为用户自定义高可用服务的可漂移内网入口,从发现故障到自动完成故障切换,无需额外的 API 调用和机器内部配置,即可完成秒级切换。
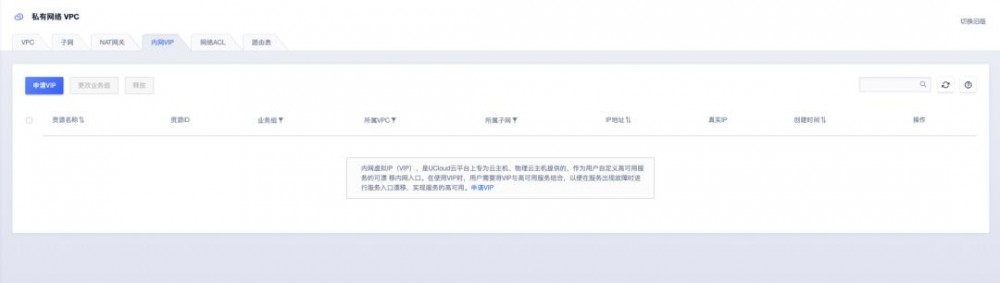
图:内网 VIP 控制台操作界面
内网 VIP 如何实现故障转移的秒级切换?
内网 VIP 的故障切换时长通常与以下两个步骤相关:
1、Master 发生故障后,备服务器需要选举出新的 Master;
2、需要在广播域内告知其他节点,该 IP 的位置发生了变化。
如上文所述,在 Overlay 网络中,上层业务报文的 ARP 协议解析、IP 寻址、单播、多播、广播都需要重新实现,会有不小难度。那么广播应当如何实现呢?
UCloud 基于广播的实现机制,演进出了如下的三个版本。
第一代:模拟广播

图:模拟广播
如上图所示,一个广播报文直接复制 N 份,送到其他广播域中的节点,即可完成广播的行为。由于 OVS 支持报文的复制和传输,只需要在 Flow 中指定多个 Output 动作即可实现。Flow 的模式如下:

图:模拟广播中 Flow 模式
这种实现确实可以满足需求,但是存在几个明显的缺点:
1、Flow 的更新。由于用户的广播域是变化的,一旦广播域发生变化,那么所有广播域中节点所在宿主机上的广播 Flow 全部需要推送更新。因此如果用户的广播域比较大,这种更新非常消耗性能。
2.、Flow 的长度数量有限制。OVS 对 Flow 的长度有要求:单条 Flow 的长度不能超过 64K bit,而广播域增加的时候,Flow 的长度一定随之增长。如果客户的子网比较大,导致超过了 Flow 的长度限制,那么就无法再进行更新,出现广播行为异常,进而影响高可用实现。
3、异构网络的广播需要单独实现。比如物理云主机底层不是基于 OVS 的架构,那么就必须重现一遍,开发和维护成本很高。
为解决上述问题,UCloud 开发出了第二代广播解决方案 —— 广播集群:
第二代:广播集群
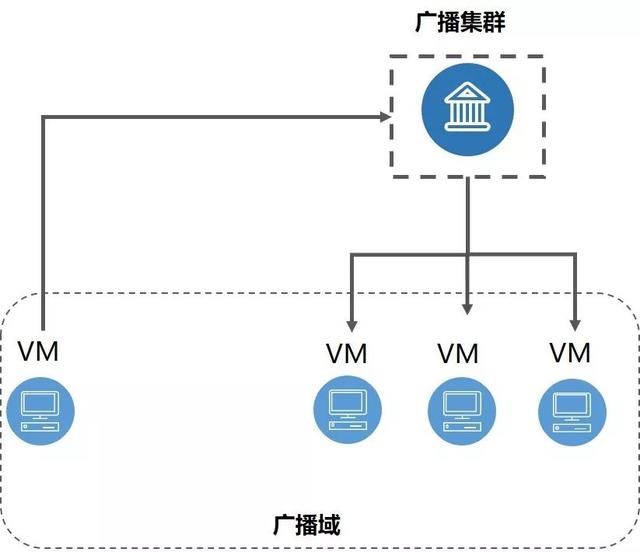
图:广播集群
如上图,所有的广播流量通过 Flow 指向自研的广播集群。广播集群从业务数据库中拉取广播的信息,对报文进行复制和分发。广播集群是 UCloud 基于 DPDK 自研的高可用集群,可以高性能地实现广播逻辑。
采用广播集群,我们很好的解决了第一代广播逻辑中存在的问题:
1、广播域的变化问题。广播域变化只需要通知广播集群即可,无需全网告知。
2、广播域的大小问题。广播集群通过 DPDK 来进行报文的复制和转发,理论上广播域无上限。
3、各种网络的适配问题。各类网络只需要将广播报文送到广播集群即可,无需进行额外的逻辑开发,很好的适配了各种网络场景。
随后,在第二代的基础上,UCloud 又提供了第三代的广播解决方案:
第三代:广播集群 + GARP 嗅探
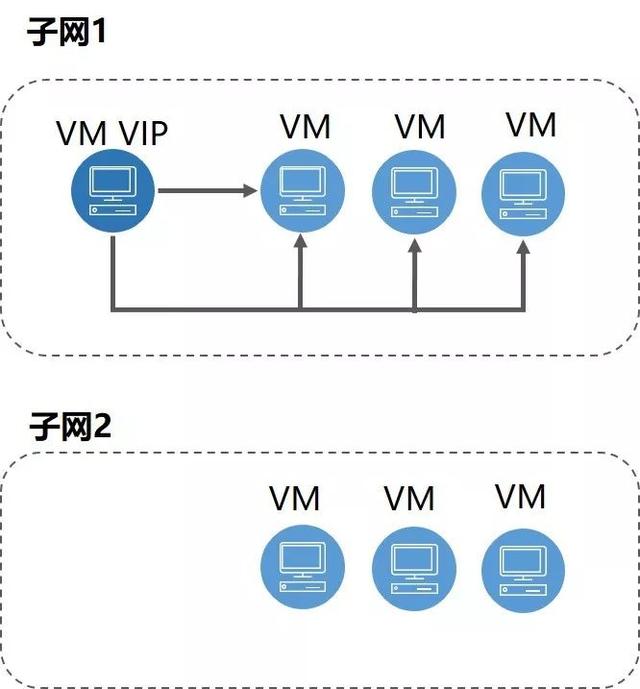
图:基于 GARP 嗅探的广播集群
在第二代广播集群已经可以很好的实现高可用服务的情况下,UCloud 为什么还要开发出第三代呢?
从前文我们可以知道,在 VIP 切换的过程中,GARP 将利用广播告知整个广播域,进而 VIP 发生漂移。但是广播域之外的服务器是没有能力获知相关信息的。这样就会出现下列问题: VIP 的切换会导致跨三层的访问失效。
而跨三层的访问则要求后台数据库必须通过某种方式获知 VIP 位置的变化。在内网 VIP 的切换过程中,GARP 报文会通知广播域内的节点 VIP 的位置信息变化,而广播集群可以获取到所有的广播流量。因此,广播集群利用 ARP_SPA=ARP_TPA 的特征过滤得到 GARP 流量,将相应的位置信息上报到后台,并更新 Flow 信息,从而保证三层的访问正常。
在第三代架构下,广播集群对公有云、物理云等多种异构网络均进行了支持,满足不同云计算高可用应用场景的需求。
应用实例解析
1、电商支付系统高可用实践
某电商在频繁的日常消费与各类促销活动中对支付系统可用性提出了很高的要求。消费者对支付系统的可用性是非常敏感的,一旦出现任何一点小小的故障,诸如 “付款失败、重新支付、支付超时” 等都会带来不好的使用体验,严重时甚至可能导致用户流失。
在不考虑外部依赖系统突发故障的前提下,如网络问题、第三方支付和银行的大面积不可用等情况,该电商希望通过提高自身支付系统的高可靠服务能力来保证消费者的可用性体验。
为了实现高可用,UCloud 基于 Keepalived + 内网 VIP 产品为该电商线上支付系统快速构建了高可靠服务,从而避免自身单点故障,大大提高系统的可用性。
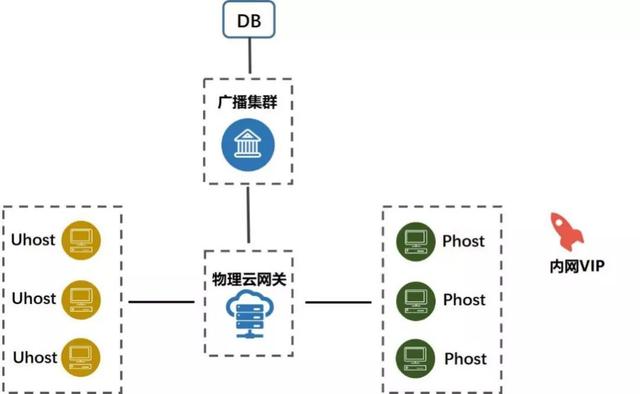
图:高可用服务构建实例
如上图,VIP 绑定在 UPHost(物理云主机)作为主节点存在,当 VIP 绑定的 Master 节点发生故障的时,便会发生 VIP 漂移。物理云网关收到 GARP 报文,并将 GARP 报文送至广播集群。广播集群分析 GARP 报文后,会将位置上报到后端,并更新物理云网关配置和公有云平台的 Flow。随后,广播集群复制 GARP 报文,并发送到广播域内的所有 UHost 和 UPHost。二层访问的信息和三层访问的信息都会在秒级内得到更新,保证业务的高可用。
2、UCloud 云数据 UDB 产品高可用技术实现
在 UCloud 云数据 UDB 产品的高可用技术实现中,也同样应用了内网 VIP 技术。如下图,UDB 产品采用双主架构,并通过 Semi-Sync 实现数据同步,由 UDB 可用性管理模块实时监控底层节点可用性,一旦监测到 Master DB 不可用,便会自动触发容灾切换机制,内网 VIP 无状态漂移至 Standby DB,保证用户 UDB 数据库服务的稳定可靠。
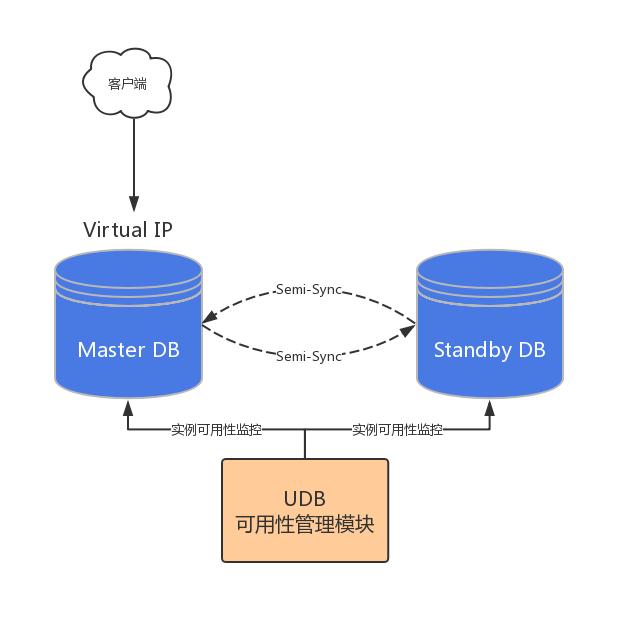
图:基于内网 VIP 的 UCloud 高可用 DB 技术实现
在 UDB 高可用实现的过程中,由于采用单一内网 VIP 接入,因此可以完成应用层的无缝切换,整个过程中无需用户进行任何人工干预和配置修改。依托内网 VIP,UDB 产品为用户提供了高可用的数据库服务,目前该产品已经服务于上万家企业并提供了数万份数据库实例。
结语
高可用是一个复杂的命题,除了应用内网 VIP 产品规避可能出现的单点故障外,还需要在服务维护方面做到严格规范操作,包括事前做好服务分割,事后做好服务监控等。
但仅止于此吗?墨菲定律告诉我们:凡是可能出错的事有很大几率会出错。每日三省吾身:业务架构是否足够稳定?异常处理是否足够完备?灾备方案是否足够充分?并据此不断优化业务系统,祝愿每个运维工程师都可以睡个好觉!
Post Views: 7
*本平台所发布文章信息,版权归UCloud所有,如需转载请注明出处!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

