带你一步一步手撕 Mybatis 源码加手绘流程图——执行部分
在上篇文章中,我向大家介绍了 Mybatis 是如何构建的,总的来说构建部分就是对于 配置文件的映射 ,而 Mybatis 中另一个很重要的部分就是 如何去通过这些配置文件封装成的 配置对象 去执行用户指定的 SQL 语句并且将结果集封装成用户需要的类型 。
写源码分析也写了好几篇文章了,个人觉得如果你真的想去弄懂源码原理的,必须要勤动手,光看文章是没有用的,你需要自己去尝试 debug,由于我写的一些源码分析篇幅都较长,如果刚兴趣最好收藏再看,如果觉得我写的还不错那么就不要吝啬自己的赞 (#^.^#)
从 DefaultSqlSession 开始
在上篇文章中,我们知道了我们需要创建一个 Sql会话 来执行 CRUD 操作,在 Mybatis 中就是指 SqlSession 接口,其中有一个默认的实现类 DefaultSqlSession ,一般我们使用的就是它。
我们可以看一看 DefaultSqlSession 中的一些方法定义,其中主要就是一些 CRUD 操作。
public class DefaultSqlSession implements SqlSession {
// 配置对象
private Configuration configuration;
// 执行器
private Executor executor;
// 是否自动提交
private boolean autoCommit;
private boolean dirty;
public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {}
public DefaultSqlSession(Configuration configuration, Executor executor) {}
@Override
public <T> T selectOne(String statement) {}
//核心selectOne
@Override
public <T> T selectOne(String statement, Object parameter) {}
@Override
public <K, V> Map<K, V> selectMap(String statement, String mapKey) {}
@Override
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey) {}
//核心selectMap
@Override
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey, RowBounds rowBounds) {}
@Override
public <E> List<E> selectList(String statement) {}
@Override
public <E> List<E> selectList(String statement, Object parameter) {}
//核心selectList
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {}
@Override
public void select(String statement, Object parameter, ResultHandler handler) {}
@Override
public void select(String statement, ResultHandler handler) {}
//核心select,带有ResultHandler,和selectList代码差不多的,区别就一个ResultHandler
@Override
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {}
@Override
public int insert(String statement) {}
@Override
public int insert(String statement, Object parameter) {}
@Override
public int update(String statement) {}
//核心update
@Override
public int update(String statement, Object parameter) {}
@Override
public int delete(String statement) {}
@Override
public int delete(String statement, Object parameter) {}
@Override
public void commit() {}
//核心commit
@Override
public void commit(boolean force) {}
@Override
public void rollback() {}
//核心rollback
@Override
public void rollback(boolean force) {}
//核心flushStatements
@Override
public List<BatchResult> flushStatements() {}
// 核心close
@Override
public void close() {}
@Override
public Configuration getConfiguration() {return configuration;}
//最后会去调用MapperRegistry.getMapper
@Override
public <T> T getMapper(Class<T> type) {}
@Override
public Connection getConnection() {}
//核心clearCache
@Override
public void clearCache() {}
//检查是否需要强制commit或rollback
private boolean isCommitOrRollbackRequired(boolean force) {}
//把参数包装成Collection
private Object wrapCollection(final Object object) {}
//严格的Map,如果找不到对应的key,直接抛BindingException例外,而不是返回null
public static class StrictMap<V> extends HashMap<String, V> {}
}
复制代码
其实主要的就是一些 CRUD 操作,今天我们就来分析一下—— 在 Mybatis 中 select 这样的操作是怎么执行的 。
Mybatis 执行 select操作的入口
上面的 DefaultSqlSession 源码我只是贴了一些方法的定义,如果你具体去看源码你会发现 很多 select 方法中都会调用相同的 selectList 方法 (包括 selectOne 其实也是调用的 selectList 只不过它只取了第一个元素),该方法具体源码如下。
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//根据statement id找到对应的MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//转而用执行器来查询结果,注意这里传入的ResultHandler是null
// rowBounds 不用管 是用来进行逻辑分页操作的
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
复制代码
处理流程很简单分为两步。
- 根据
statementId去Configuration中获取对应的MappedStatement对象。 - 传入获取到的
MappedStatement然后传入执行器Executor的查询query方法并调用返回结果。其中还做了对参数parameter的包装操作等等
在我做分析源码的时候其实还有一个疑问,就是 这个 Executor 是哪个具体的 Executor ? 因为 Executor 只是一个接口,并且在 DefaultSqlSession 中只是定义了这么一个字段并没有进行实例化,那么这个 Executor 到底是接口中的哪一个实现类呢?
这个问题的原因还需要在我们 初始化过程 中去寻找。从上一篇文章中我们知道,在 SqlSession 的构建过程中,Mybatis 使用了 工厂模式 和 构建者模式 ,最终构建的 DefaultSqlSession 是通过 DefaultSqlSessionFactory 创建的,而 DefaultSqlSessionFactory 又是通过 DefaultSqlSessionFactoryBuilder 构建的。
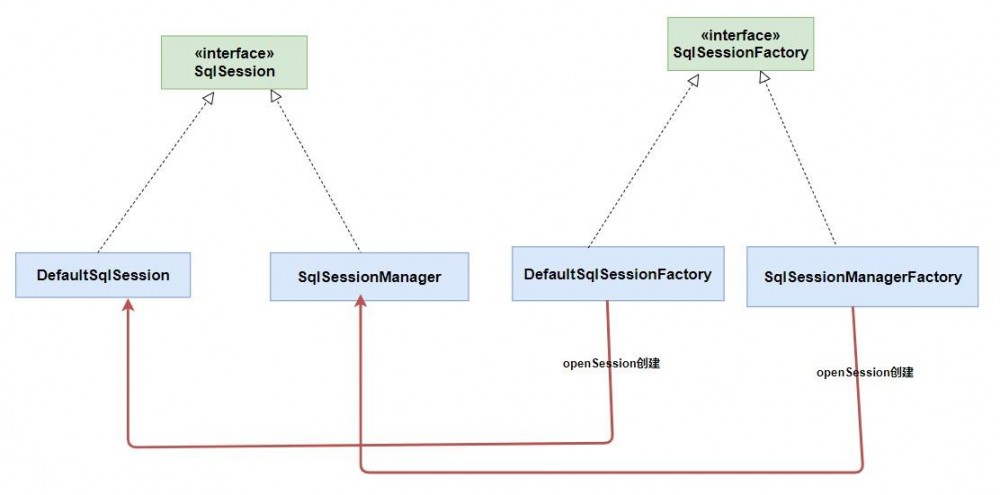
// 创建 DefaultSqlSessionFactory
// 这是在 DefaultSqlSessionFactoryBuilder 中的方法
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
复制代码
上面是通过 构建者模式 创建工厂,得到工厂之后我们还需要通过 工厂模式 创建 DefaultSqlSession 。
// 其中有很多 openSession 创建方法 最终还是会
// 调用openSessionFromDataSource
@Override
public SqlSession openSession() {
// 这里传入了一个 defaultExecutorType
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
// 对应着上面 返回的是 DefaultExecutorType
public ExecutorType getDefaultExecutorType() {
return defaultExecutorType;
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
//通过事务工厂来产生一个事务 不用管
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//生成一个执行器(事务包含在执行器里)
// 这里你会发现执行器还是在 Configuration 中创建的
// 我们知道上面传入的 type 是 default类型的
final Executor executor = configuration.newExecutor(tx, execType);
//然后产生一个DefaultSqlSession
// 这里传入了执行器
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
//如果打开事务出错,则关闭它
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
//最后清空错误上下文
ErrorContext.instance().reset();
}
}
复制代码
上面就是 DefaultSqlSession 的构建流程了,你会发现我们刚刚需要找的 Executor 就是在这里 实例化 了,而且最终是在 Configuration 中创建的。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
// 这句再做一下保护,囧,防止粗心大意的人将defaultExecutorType设成null
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 然后就是简单的3个分支,产生3种执行器BatchExecutor/ReuseExecutor/SimpleExecutor
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果要求缓存,生成另一种CachingExecutor(默认就是有缓存),装饰者模式,所以默认都是返回CachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
//此处调用插件,通过插件可以改变Executor行为
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
复制代码
通过上面的源代码,我们就能得出一个结论, 如果指定了执行器类型 Executor 那么就会创建对应类型的执行器,如果不指定那么就是默认的 DefaultExecutor 。 但是不管是什么类型,如果在 Configuartion 中指定了 cacheEnabled 为 true (即开启缓存),那么就会通过一个 CachingExecutor 再次包装原本的 Executor ,所以如果开启缓存那么返回的就是 CachingExecutor 。这里用到了 装饰器模式 ,我们可以看一下 执行器的 UML 图。
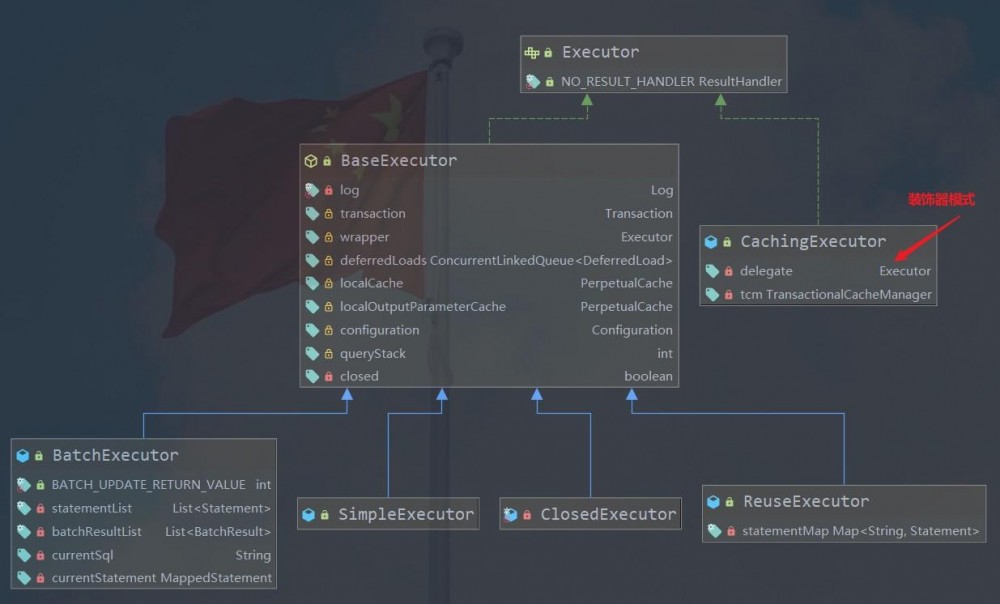
当然这个时候你肯定还会有一个问题,这个 cacheEnabled 又是啥时候初始化的?这里我就长话短说,还记得我们进行配置文件到配置对象是通过 XMLConfigBuilder 这个构造者吗?其实 这个 cachedEnabled 是 mybatis-config.xml 文件中的 <settings> 标签底下需要配置的,如果没有配置那么 Mybatis 会默认配置为 true 。下面我贴出了默认配置的源码,其中就有 cachedEnabled 和 默认的执行器类型 ExecutorType ,你可以搜寻一下找到答案(这个方法在 XMLConfigBuilder 中)。
private void settingsElement(XNode context) throws Exception {
if (context != null) {
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
//检查下是否在Configuration类里都有相应的setter方法(没有拼写错误)
MetaClass metaConfig = MetaClass.forClass(Configuration.class);
for (Object key : props.keySet()) {
if (!metaConfig.hasSetter(String.valueOf(key))) {
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
//下面非常简单,一个个设置属性
//如何自动映射列到字段/ 属性
configuration.setAutoMappingBehavior(AutoMappingBehavior.valueOf(props.getProperty("autoMappingBehavior", "PARTIAL")));
//缓存
configuration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));
//proxyFactory (CGLIB | JAVASSIST)
//延迟加载的核心技术就是用代理模式,CGLIB/JAVASSIST两者选一
configuration.setProxyFactory((ProxyFactory) createInstance(props.getProperty("proxyFactory")));
//延迟加载
configuration.setLazyLoadingEnabled(booleanValueOf(props.getProperty("lazyLoadingEnabled"), false));
//延迟加载时,每种属性是否还要按需加载
configuration.setAggressiveLazyLoading(booleanValueOf(props.getProperty("aggressiveLazyLoading"), true));
//允不允许多种结果集从一个单独 的语句中返回
configuration.setMultipleResultSetsEnabled(booleanValueOf(props.getProperty("multipleResultSetsEnabled"), true));
//使用列标签代替列名
configuration.setUseColumnLabel(booleanValueOf(props.getProperty("useColumnLabel"), true));
//允许 JDBC 支持生成的键
configuration.setUseGeneratedKeys(booleanValueOf(props.getProperty("useGeneratedKeys"), false));
//配置默认的执行器
configuration.setDefaultExecutorType(ExecutorType.valueOf(props.getProperty("defaultExecutorType", "SIMPLE")));
//超时时间
configuration.setDefaultStatementTimeout(integerValueOf(props.getProperty("defaultStatementTimeout"), null));
//是否将DB字段自动映射到驼峰式Java属性(A_COLUMN-->aColumn)
configuration.setMapUnderscoreToCamelCase(booleanValueOf(props.getProperty("mapUnderscoreToCamelCase"), false));
//嵌套语句上使用RowBounds
configuration.setSafeRowBoundsEnabled(booleanValueOf(props.getProperty("safeRowBoundsEnabled"), false));
//默认用session级别的缓存
configuration.setLocalCacheScope(LocalCacheScope.valueOf(props.getProperty("localCacheScope", "SESSION")));
//为null值设置jdbctype
configuration.setJdbcTypeForNull(JdbcType.valueOf(props.getProperty("jdbcTypeForNull", "OTHER")));
//Object的哪些方法将触发延迟加载
configuration.setLazyLoadTriggerMethods(stringSetValueOf(props.getProperty("lazyLoadTriggerMethods"), "equals,clone,hashCode,toString"));
//使用安全的ResultHandler
configuration.setSafeResultHandlerEnabled(booleanValueOf(props.getProperty("safeResultHandlerEnabled"), true));
//动态SQL生成语言所使用的脚本语言
configuration.setDefaultScriptingLanguage(resolveClass(props.getProperty("defaultScriptingLanguage")));
//当结果集中含有Null值时是否执行映射对象的setter或者Map对象的put方法。此设置对于原始类型如int,boolean等无效。
configuration.setCallSettersOnNulls(booleanValueOf(props.getProperty("callSettersOnNulls"), false));
//logger名字的前缀
configuration.setLogPrefix(props.getProperty("logPrefix"));
//显式定义用什么log框架,不定义则用默认的自动发现jar包机制
configuration.setLogImpl(resolveClass(props.getProperty("logImpl")));
//配置工厂
configuration.setConfigurationFactory(resolveClass(props.getProperty("configurationFactory")));
}
}
复制代码
我们在这里小结一下, 在执行 SqlSession 中的一些 select 操作的时候都会调用到一个 selectList 方法,这个方法会从 SqlSession 中的 Configuration 配置对象中获取用户想要的 MappedStatement (用户自己指定 MappedStatementId ),然后将这个获取到的 MappedStatement 对象传入 SqlSession 中的字段 Executor 执行器的查询方法中获取结果集并包装结果集返回列表 。在 Executor 初始化这条支线,使用了 装饰者模式 ,构建的是 CachingExecutor 并且里面还封装了指定的 Executor 。

Mybatis 是如何一步一步执行查询方法的?
获取结果集
我们上面知道了在 Executor 中使用到了 装饰者模式 ,也就是说我们上面的主线会先执行 CachingExecutor 中的 query 方法,这里面其实还会调用到里面它包装的真正的 Executor ,也就是说外面封装的一层 CachingExecutor 只是为了做一些缓存操作的,而真正执行的还是原本的执行器 。
我们来看一下在 CachingExecutor 进行的操作
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
//query时传入一个cachekey参数
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
//默认情况下是没有开启缓存的(二级缓存).要开启二级缓存,你需要在你的 SQL 映射文件中添加一行: <cache/>
//简单的说,就是先查CacheKey,查不到再委托给实际的执行器去查
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 最终还是调用的里面封装的委托对象的查询方法
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
复制代码
源码也验证了我上面的说法, CachingExecutor 只是做一些缓存处理的 。我们继续看看真正的执行方法。一般来说我们调用的是 SimpleExecutor (你可以去看刚刚的 setting 默认配置就是 SimpleExecutor),其中 SimpleExecutor 等执行器都继承了 BaseExecutor ,所以调用的是 BaseExecutor 中的 query 方法。为了方便你理解我再次把 UML 图放在这里。
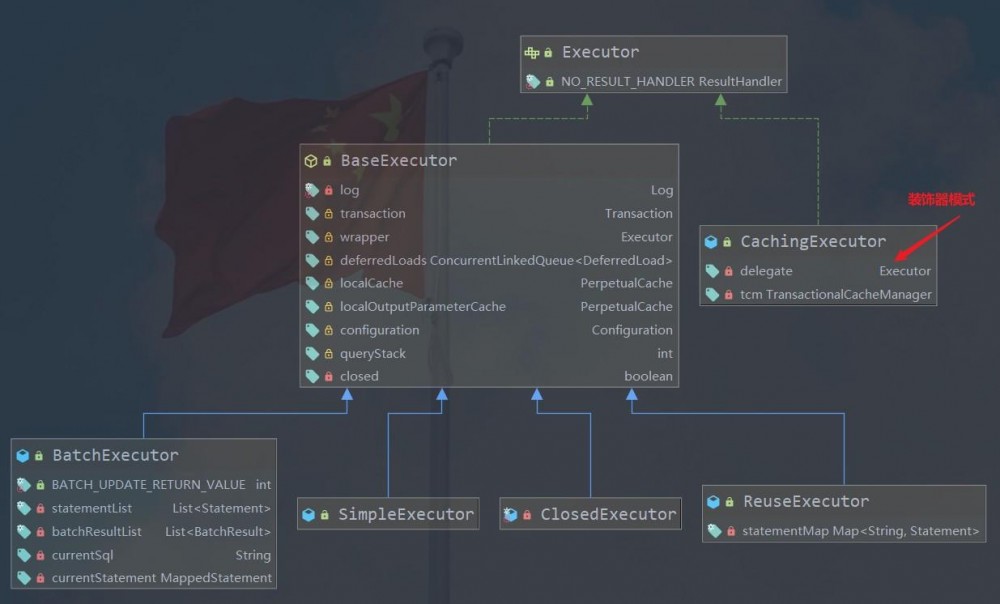
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
//如果已经关闭,报错
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//先清局部缓存,再查询.但仅查询堆栈为0,才清。为了处理递归调用
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
//加一,这样递归调用到上面的时候就不会再清局部缓存了
queryStack++;
//先根据cachekey从localCache去查
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//若查到localCache缓存,处理localOutputParameterCache
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据库查 主线在这里
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
//清空堆栈
queryStack--;
}
if (queryStack == 0) {
//延迟加载队列中所有元素
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
//清空延迟加载队列
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
//如果是STATEMENT,清本地缓存
clearLocalCache();
}
}
return list;
}
//从数据库查
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//先向缓存中放入占位符???
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 真正的执行方法在这!!!
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//最后删除占位符
localCache.removeObject(key);
}
//加入缓存
localCache.putObject(key, list);
//如果是存储过程,OUT参数也加入缓存
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
复制代码
这两个方法还是做了一些基础的处理,最终真正干活的还是在 doQuery 方法中。而这个方法是需要子类去实现的,我们这次就得深入到真正的子类 SimpleExecutor 中去了。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取配置对象
Configuration configuration = ms.getConfiguration();
// 新建一个StatementHandler
// 这里看到ResultHandler传入了
// 创建的其实是 RoutingStatementHandler 里面也用到了 装饰者模式
// 你可以自己去看这个源码
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 准备语句 这个里面其实就是 原生 JDBC 代码 你创建 Statement 的流程
stmt = prepareStatement(handler, ms.getStatementLog());
// StatementHandler.query
// 真正的主线在这里
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
复制代码
这里的主线是调用到了 StatementHandler 的 query 方法,因为 StatementHandler 是一个接口,所以真正调用到的是生成的 RoutingStatementHandler 的 query 方法。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 这里还是装饰者模式
return delegate.<E>query(statement, resultHandler);
}
复制代码
你会发现这里面又用到了 装饰者模式 (但是这里没做什么处理,而是直接调用了),最终调用的其实还是 PreparedStatementHandler 中的 query 方法。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 强制转换
PreparedStatement ps = (PreparedStatement) statement;
// 这里就是 JDBC 里面的执行方法
ps.execute();
// 这里已经能获取结果集 ResultSet 了 但是需要做 结果集的类型处理
// 最终返回的是列表
return resultSetHandler.<E> handleResultSets(ps);
}
复制代码
接下来调用的是 DefaultResultSetHandler 中的处理执行结果的方法。
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// <select>标签的resultMap属性,可以指定多个值,多个值之间用逗号(,)分割
// 这是上篇文章中我们提到过得
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 这里是获取第一个结果集,将传统JDBC的ResultSet包装成一个包含结果列元信息的ResultSetWrapper对象
// 这里获取了结果集并且包装成相应的包装类
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 这里是获取所有要映射的ResultMap(按照逗号分割出来的)
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
// 要映射的ResultMap的数量
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
// 循环处理每个ResultMap,一般只有一个
while (rsw != null && resultMapCount > resultSetCount) {
// 得到结果映射信息
ResultMap resultMap = resultMaps.get(resultSetCount);
// 处理结果集
// 从rsw结果集参数中获取查询结果,再根据resultMap映射信息,将查询结果映射到multipleResults中
// 这里是主线 处理结果集的 查询结果会变成列表存入 multipleResults 中去
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// 对应<select>标签的resultSets属性,一般不使用 不用管
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// 如果只有一个结果集合,则直接从多结果集中取出第一个
return collapseSingleResultList(multipleResults);
}
复制代码
现在我们就可以画出一个简单的获取结果集并返回的流程图了。
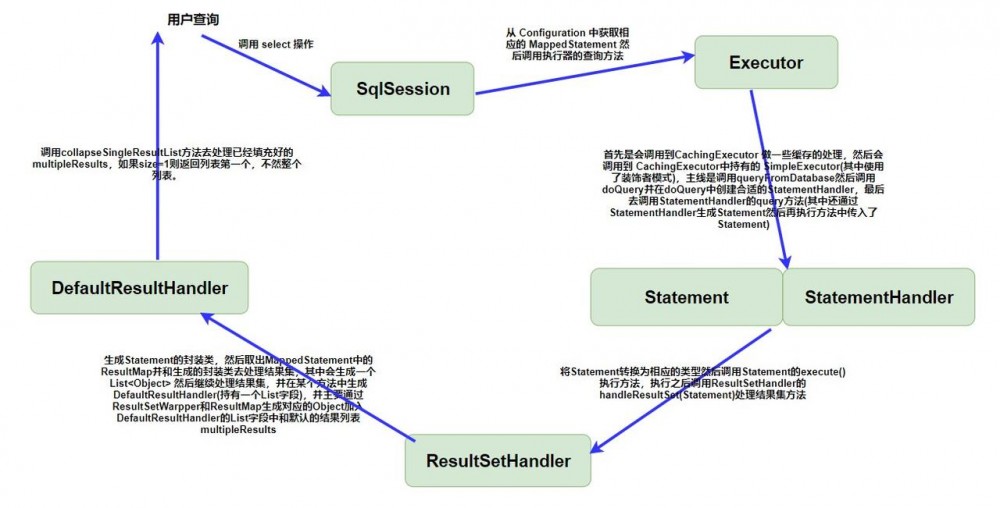
处理结果集
在上文中我们得知在 getFirstResultSet 方法中 通过 JDBC 原生代码获取了 ResultSet (结果集) 并且封装成包装类 ResultSetWrapper ,因为我们返回给 dao 层的肯定不能是原生的 ResultSet ,所以我们需要进一步处理结果集。
接下来还是在 DefaultResultSetHandler 中,只不过我们的主要任务变成了 如何去处理结果集?
//处理结果集
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
//如果没有resultHandler
//新建DefaultResultHandler
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
//调用自己的handleRowValues
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
//得到记录的list
multipleResults.add(defaultResultHandler.getResultList());
} else {
//如果有resultHandler
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
//最后别忘了关闭结果集
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
复制代码
上面的代码逻辑总结来说就是: 判断 resultHandler 是否为空,如果为空则生成一个默认的 DefaultResultHandler 不然则使用原本的, 最终都会去调用 handleRowValues 方法进行进一步的处理 。
当然我们最终应该去处理 multipleResults 这个列表变量,而在 Mybatis 中是在 ResultHandler 中持有了一个列表字段,最终是将数据赋值到 ResultHandler 中的列表字段里面,然后将这个列表字段加入 multipleResults 中去的。
从上面分析可知,最终都是调用的 handleRowValues 所以进行结果集的数据处理的主线还在这里。
private void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
//是否有内嵌 不用管先
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 继续处理
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
复制代码
因为不涉及到其他复杂的步骤我们这里是直接分析一般流程,这里会调用 handleRowValuesForSimpleResultMap 方法继续进行数据处理。
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap,
ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
// 获取结果集信息
ResultSet resultSet = rsw.getResultSet();
// 使用rowBounds的分页信息,进行逻辑分页(也就是在内存中分页)
// 分页先不用管
skipRows(resultSet, rowBounds);
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 通过<resultMap>标签的子标签<discriminator>对结果映射进行鉴别
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 将查询结果封装到POJO中
// rsw 是结果集的包装类,里面封装了返回结果的信息
// 通过结果集包装类创建 POJO
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
// 处理对象嵌套的映射关系
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
复制代码
上面的方法做的事情很简单,就是通过结果集包装类和一开始定义的类字段(比如这个 POJO 是 Admin类其中有 account 和 password 等字段) 封装成一个 Object 实体类。然后将这个实体类存入某个区域里。
我们先不管 getRowValue 方法是如何去处理的,我们先思考一下, 此时获取到的 Object 对象是如何载入到 multipleResults 中的,或者说是如何加入到 resultHandler 中的列表字段里的(因为这里最终也会加入 multipleResults ) 。
想必你也看出来了,答案肯定在 storeObject 中(因为其中 resultHandler 作为了参数传入了进去),这里我就做简单分析
private void storeObject(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
linkToParents(rs, parentMapping, rowValue);
} else {
// 一般处理这里
callResultHandler(resultHandler, resultContext, rowValue);
}
}
private void callResultHandler(ResultHandler resultHandler, DefaultResultContext resultContext, Object rowValue) {
resultContext.nextResultObject(rowValue);
// resultContext 封装了一些上下文信息 这里包括封装好的 Object
// 这里调用的是 resultHandler 对象呀!!!
resultHandler.handleResult(resultContext);
}
// 这里是在 DefaultResultHandler 中进行的 所以
// 是给里面的列表字段进行添加
@Override
public void handleResult(ResultContext context) {
// 处理很简单,就是把记录加入List
list.add(context.getResultObject());
}
复制代码
好了分析完之后我们就可以大胆地分析如何包装结果 POJO 对象的了,我们来进入 getRowValue 方法中。
//核心,取得一行的值
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {
//实例化ResultLoaderMap(延迟加载器)
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
//调用自己的createResultObject,内部就是new一个对象(如果是简单类型,new完也把值赋进去)
Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null);
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
//一般不是简单类型不会有typehandler,这个if会进来
// 重新有做了封装
// 这步之后 metaObject 就持有了 resultObject
// 这个得记住
final MetaObject metaObject = configuration.newMetaObject(resultObject);
boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty();
if (shouldApplyAutomaticMappings(resultMap, false)) {
// 自动映射咯 这里离是赋值操作
// 也就是说此时我们的 resultHandler 其中的值都是 null 或默认值
// 这里把每个列的值都赋到相应的字段里去了
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
// 执行完这个方法 resultObject 中的字段才有值
// 你会发现这里传入的其实是 metaObject
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
resultObject = foundValues ? resultObject : null;
return resultObject;
}
return resultObject;
}
复制代码
上面我们进行了一个操作就是:使用 resultObject 和其他一些东西 构造了 metaObject 实例 ,如果翻看源码你会发现这个 metaObject 里面是持有了 resultObject ,这里因为篇幅有限,我不做过多解释,感兴趣可以自己去查看源码。整个方法就是通过原先定义好的配置信息创建一个 POJO 对象的空壳,然后通过结果集中的数据给空壳赋值。
我们来具体看一下 Mybatis 是如何给空壳赋值的。
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 获取字段名称列表
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
// 循环赋值
for (ResultMapping propertyMapping : propertyMappings) {
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
// 重要 从结果集包装类里面获取每个字段的值
// 这里面还涉及到一个很重要的类 TypeHandler
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
// issue #541 make property optional
final String property = propertyMapping.getProperty();
// issue #377, call setter on nulls
if (value != NO_VALUE && property != null && (value != null || configuration.isCallSettersOnNulls())) {
if (value != null || !metaObject.getSetterType(property).isPrimitive()) {
// 在这里赋值了,其实这里面是给 metaObject 持有的
// resultObject中的字段赋值
metaObject.setValue(property, value);
}
foundValues = true;
}
}
}
return foundValues;
}
复制代码
上面整个流程就是 先获取 POJO类 中字段的一些名称,然后通过结果集包装类 ResultSetWarpper 获取结果集中对应字段的值并且赋值给 metaObject 中持有的 resultObject “空壳”对象中的相应字段,这么一来 resultObject 就不是空壳了 。在上面我标注了一个比较重要的地方就是这段代码。
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix); 复制代码
你有没有想过, 这其中是如何将字段原本的值包装成一个 Object 对象的?
我们进来找一下答案。
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping);
return NO_VALUE;
} else if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
return NO_VALUE;
} else {
// 前面的一些可以不用看 这里我们涉及到了一个 TypeHandler
// 其中获取到了 ResultMapping 原本的 TypeHandler
// 然后通过 TypeHandler 这个类型处理器去处理值
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
return typeHandler.getResult(rs, column);
}
}
复制代码
也就是说最终一些对象的类型转换是通过 TypeHandler 来实现的,这是 Mybatis 中做类型转换的主要工具类,在上一篇文章中我也提到过。
这样,整个 Mybatis 的基本的执行流程我们就分析完毕了,我在网上找到一张挺好的图,你可以参考着我上面的分析去理解(不过我还是建议你 debug 去看一下源码),图有点不清晰,目前没找到清晰版本的。
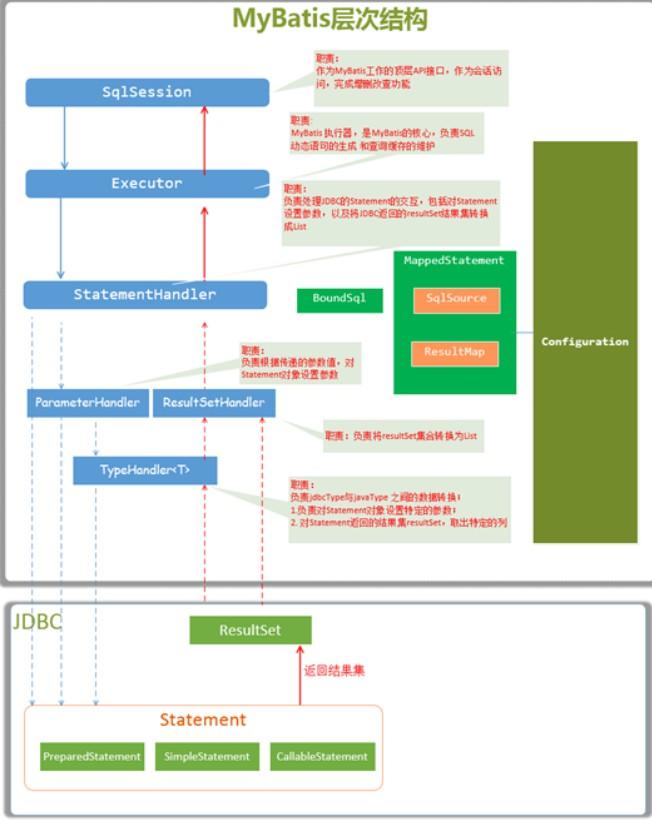
总结
总结来说呢,整个 Mybatis 的查询流程就是 封装了 JDBC 原生代码,并做了 JDBC 没有为我们做的 结果集的类型转换 。
正文到此结束
- 本文标签: Connection ACE SqlSessionFactory 二级缓存 equals 递归 ldap https 配置 CTO 插件 dataSource Word SqlSessionFactoryBuilder executor ArrayList tag update struct map 时间 list 总结 删除 Action cache session 缓存 java ip sql 代码 value final http Property StatementHandler HashMap cglib mina 安全 API key 参数 core 处理器 plugin bug Proxy db cat NSA XML 分页 src trigger sqlsession id ResultSet node 数据库 IDE 实例 mybatis lib autocommit 动态SQL Collection Statement tab tar 数据 Select build 文章 mapper IO JDBC 源码 UI App REST
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

