java lambda 深入浅出
 戳蓝字「TopCoder
」关注我们哦!
戳蓝字「TopCoder
」关注我们哦!

JDK8中包含了许多内建的Java中常用到函数接口,比如Comparator或者 Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上。
| name | type | description |
| Consumer | Consumer< T > | |
| Predicate | Predicate< T > | |
| Function | Function< T, R > | |
| Supplier | Supplier< T > | |
| UnaryOperator | UnaryOperator | |
| BinaryOperator | BinaryOperator |
标注为@FunctionalInterface的接口是函数式接口,该接口只有一个自定义方法。注意,只要接口只要包含一个抽象方法,编译器就默认该接口为函数式接口。
Collection中的新方法
List.forEach()该方法的签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,其中Consumer是个函数接口,里面只有一个待实现方法void accept(T t)。注意,这里的Consumer不重要,只需要知道它是一个函数式接口即可,一般使用不会看见Consumer的身影。
list.forEach(item -> System.out.println(item));
List.removeIf()该方法签名为boolean removeIf(Predicate<? super E> filter),作用是删除容器中所有满足filter指定条件的元素,其中Predicate是一个函数接口,里面只有一个待实现方法boolean test(T t),同样的这个方法的名字根本不重要,因为用的时候不需要书写这个名字。
// list中元素类型String
list.removeIf(item -> item.length() < 2);
List.replaceAll()该方法签名为void replaceAll(UnaryOperator
// list中元素类型String
list.replaceAll(item -> item.toUpperCase());
List.sort()该方法定义在List接口中,方法签名为void sort(Comparator<? super E> c),该方法根据c指定的比较规则对容器元素进行排序。Comparator接口我们并不陌生,其中有一个方法int compare(T o1, T o2)需要实现,显然该接口是个函数接口。
// List.sort()方法结合Lambda表达式
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.sort((str1, str2) -> str1.length()-str2.length());
Map.forEach()该方法签名为void forEach(BiConsumer<? super K,? super V> action),作用是对Map中的每个映射执行action指定的操作,其中BiConsumer是一个函数接口,里面有一个待实现方法void accept(T t, U u)。
map.forEach((key, value) -> System.out.println(key + ": " + value));
Stream API
认识了几个Java8 Collection新增的几个方法,在了解下Stream API,你会发现它在集合数据处理方面的强大作用。常见的Stream接口继承关系图如下:
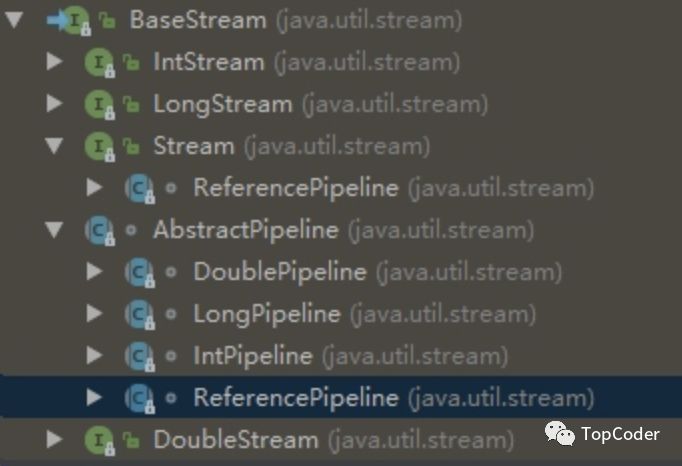
Stream是数据源的一种视图,这里的数据源可以是数组、集合类型等。得到一个stream一般不会手动创建,而是调用对应的工具方法:
• 调用Collection.stream()或者Collection.parallelStream()方法 • 调用Arrays.stream(T[] array)方法
Stream的特性
• 无存储 。stream不是一种数据结构,它只是某种数据源的一个视图。本质上stream只是存储数据源中元素引用的一种数据结构,注意stream中对元素的更新动作会反映到其数据源上的。(有点类似于MySQL中的视图概念) • 为函数式编程而生 。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。 • 惰式执行 。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。 • 可消费性 。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
对Stream的操作分为2种,中间操作与结束操作,二者的区别是,前者是惰性执行,调用中间操作只会生成一个标记了该操作的新的stream而已;后者会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
| 操作类型 | 接口方法 |
| 中间操作 | oncat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
stream方法
forEach()stream的遍历操作。
filter()函数原型为Stream
distinct()函数原型为Stream
sorted()排序函数有两个,一个是用自然顺序排序,一个是使用自定义比较器排序,函数原型分别为Stream
map()函数原型为
List<Integer> list = CollectionUtil.newArrayList(1, 2, 3, 4);
list.stream().map(item -> String.valueOf(item)).forEach(System.out::println);
reduce 和 collect
reduce的作用是从stream中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。
// 找出最长的单词
Stream<String> stream = Stream.of("I", "love", "you", "too");
Optional<String> longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
collect方法是stream中重要的方法,如果某个功能没有在Stream接口中找到,则可以通过collect方法实现。
// 将Stream转换成容器或Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList());
// Set<String> set = stream.collect(Collectors.toSet());
// Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length));
诸如String::length的语法形式称为方法引用,这种语法用来替代某些特定形式Lambda表达式。如果Lambda表达式的全部内容就是调用一个已有的方法,那么可以用方法引用来替代Lambda表达式。方法引用可以细分为四类。引用静态方法 Integer::sum,引用某个对象的方法 list::add,引用某个类的方法 String::length,引用构造方法 HashMap::new。
Stream Pipelines原理
ArrayList<String> list = CollectionUtil.newArrayList("I", "love", "you");
list.stream()
.filter(s -> s.length() > 1)
.map(String::toUpperCase)
.sorted()
.forEach(System.out::println);
上面的代码和下面的功能一样,不过下面的代码便于打断点调试。
ArrayList<String> list = CollectionUtil.newArrayList("I", "love", "you");
list.stream()
.filter(s -> {
return s.length() > 1;
})
.map(s -> {
return s.toUpperCase();
})
.sorted()
.forEach(s -> {
System.out.println(s);
});
首先filter方法了解一下:
// ReferencePipeline
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
// 生成state对应的Sink实现
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
filter方法返回一个StatelessOp实例,并实现了其opWrapSink方法,可以肯定的是opWrapSink方法在之后某个时间点会被调用,进行Sink实例的创建。从代码中可以看出,filter方法不会进行真正的filter动作(也就是遍历列表进行filter操作)。
filter方法中出现了2个新面孔,StatelessOp和Sink,既然是新面孔,那就先认识下。
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S>
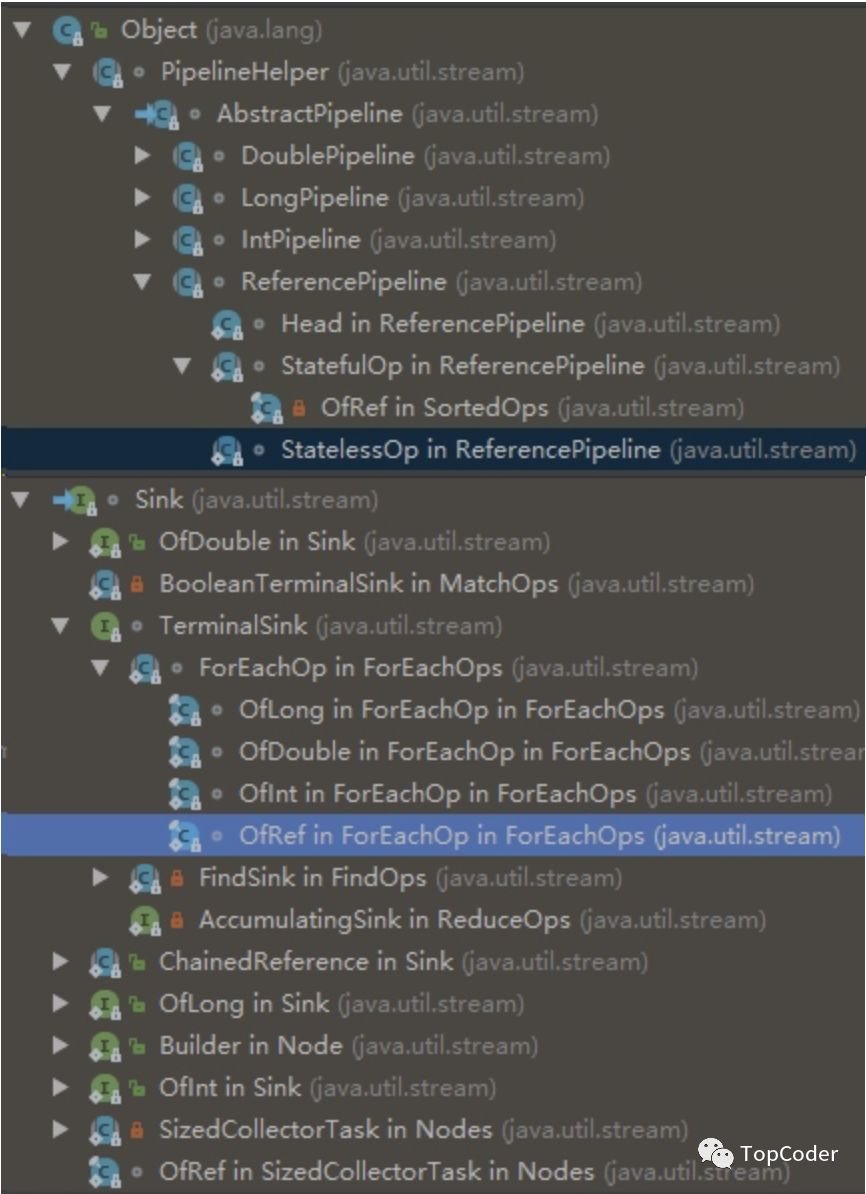
StatelessOp继承自AbstractPipeline,lambda的流处理可以分为多个stage,每个stage对应一个AbstractPileline和一个Sink。
Stream流水线组织结构示意图如下:
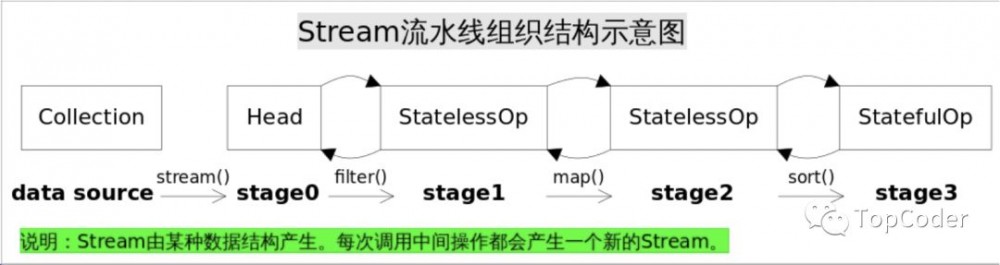
图中通过Collection.stream()方法得到Head也就是stage0,紧接着调用一系列的中间操作,不断产生新的Stream。 这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作 。这就是Stream记录操作的方式。
Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记,只有结束操作才会触发实际计算。中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果。
有了AbstractPileline,就可以把整个stream上的多个处理操作(filter/map/...)串起来,但是这只解决了多个处理操作记录的问题,还需要一种将所有操作叠加到一起的方案。你可能会觉得这很简单,只需要从流水线的head开始依次执行每一步的操作(包括回调函数)就行了。这听起来似乎是可行的,但是你忽略了前面的Stage并不知道后面Stage到底执行了哪种操作,以及回调函数是哪种形式。换句话说,只有当前Stage本身才知道该如何执行自己包含的动作。这就需要有某种协议来协调相邻Stage之间的调用关系。这就需要Sink接口了,Sink包含的方法如下:
| 方法名 | 作用 |
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
有了上面的协议,相邻Stage之间调用就很方便了,每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的accept()方法即可,并不需要知道其内部是如何处理的。当然对于有状态的操作,Sink的begin()和end()方法也是必须实现的。比如Stream.sorted()是一个有状态的中间操作,其对应的Sink.begin()方法可能创建一个存放结果的容器,而accept()方法负责将元素添加到该容器,最后end()负责对容器进行排序。Sink的四个接口方法常常相互协作,共同完成计算任务。实际上Stream API内部实现的的本质,就是如何重载Sink的这四个接口方法。
回到最开始地方的代码示例,map/sorted方法流程大致和filter类似,这些操作都是中间操作。重点关注下forEach方法:
// ReferencePipeline
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
// ... ->
// AbstractPipeline
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
@Override
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
// 各个pipeline的opWrapSink方法回调
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
// sink各个方法的回调
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
forEach()流程中会触发各个Sink的操作,也就是执行各个lambda表达式里的逻辑了。到这里整个lambda流程也就完成了。
参考资料:
1、https://github.com/CarpenterLee/JavaLambdaInternals
正文到此结束
- 本文标签: API 实例 lib mapper ArrayList 编译 description IDE 遍历 dist Action HashMap java find 数据 HTML consumer 函数式编程 集合类 mysql 调试 App final ACE Lua tag https UI CTO 组织 删除 本质 stream git map 时间 list http id lambda ip sql 代码 value entity Collection 构造方法 tab GitHub key src IO 静态方法 协议 cat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

