基于微服务的企业应用架构设计
| 编辑推荐: |
|
文章介绍了微服务架构实践的数据一致性、stateless service、和出现异常后的错误排查,元数据驱动的微服务定义和同步模式异步化的一些问题。 本文来自于EAII企业架构创新研究院,由火龙果软件Alice编辑、推荐。 |
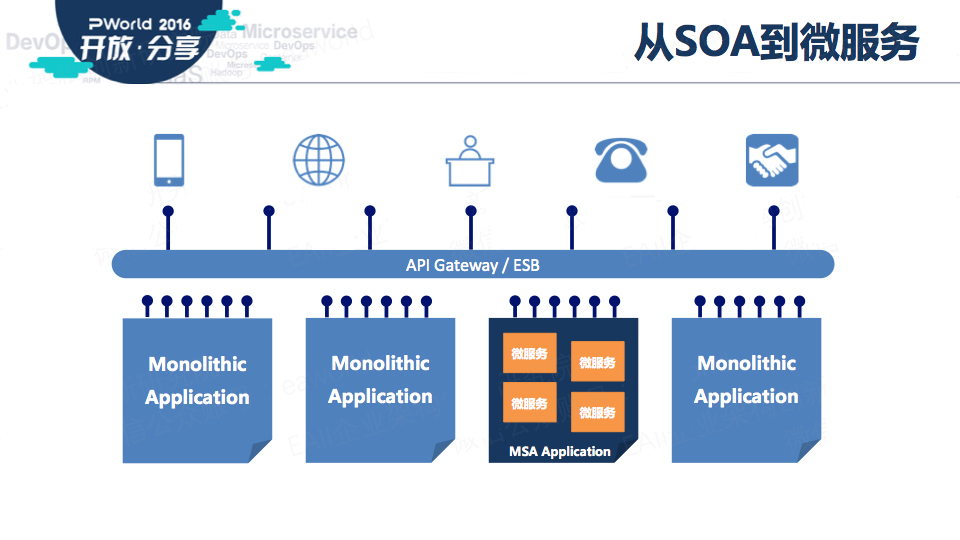
微服务好像是这两年突然火起来的,其实和很多其他架构风格一样,微服务架构也是我们在用软件改变世界的过程中,为了适应内外部环境的变化,而逐渐演化出的一种当前的最佳实践。
比如SOA,比如J2EE,比如传统分布式;微服务架构和它们都有千丝万缕的联系。
前几天我们的CTO焦总发表了一篇文章:《从前世看今生,从JavaEE到微服务》,推荐大家看看,对微服务的来龙去脉讲得非常清楚。
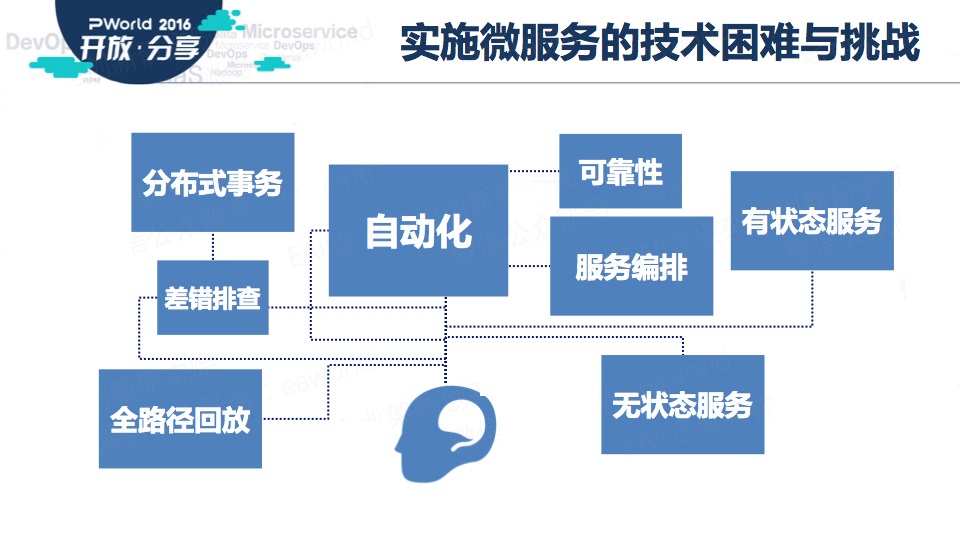
这些年来,我们帮助一些客户在分布式/微服务架构方面进行了一些尝试与实践,在这个过程中碰到了以前在单体应用下很少需要特意关注的问题。
比如数据一致性、比如stateless service、比如出现异常后的错误排查等等

在这个过程中,积累了一些经验,我把这些经验总结成范式(或者叫最佳实践),一共八个,如上图。
一、采用同步方式记录业务流水
首先我们来看看第一范式:采用同步方式记录业务流水
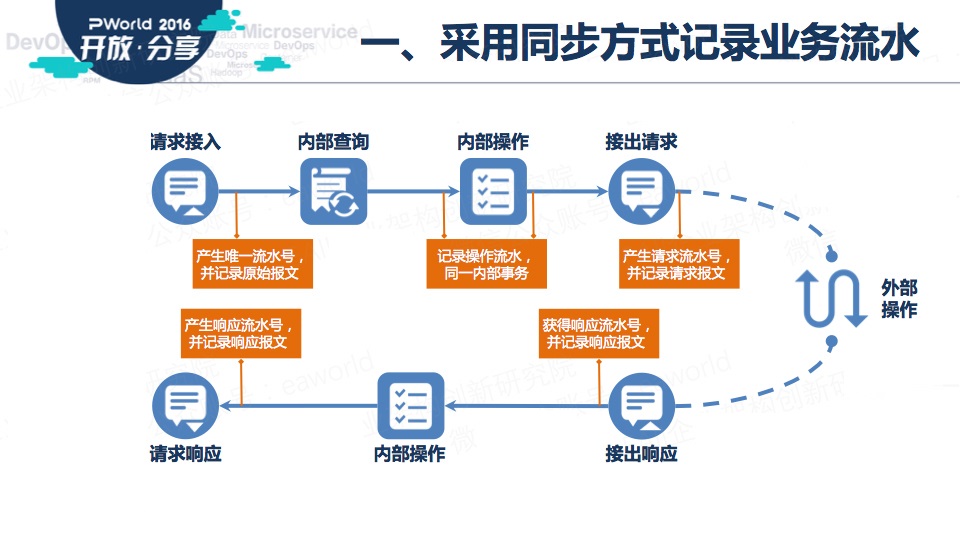
流水记录了业务状态最终确定前的整个过程,是给业务参与各方看的,这个参与各方包括了客户(比如大家拿到的信用卡刷卡记录)、第三方系统(比如对账文件)、内部用户(比如我们给客服打电话,客服可以知道你的交易历史)等等。
由于流水的作用和系统日志非常像,因此有些系统在设计时会把这两者混淆起来,基于性能的考虑,会像记录日志那样,用异步方式来记录流水。其实这是非常大的误区。就像上面所说,流水有业务含义,是给业务参与各方看的,它所记录的数据应该是和业务数据有一致性要求,而日志是给我们程序员看的,偶尔丢个一两条是可接受的。
因此我们需要用同步的方式来记录业务流水,也就是说记录流水应该和正常的业务操作在同一个事务中。
上图中,第一个“内部操作”更改了业务数据状态,因此需要同步记录业务流水,其他几个环节只记录日志即可。
二、流水号设计的GAIR模式
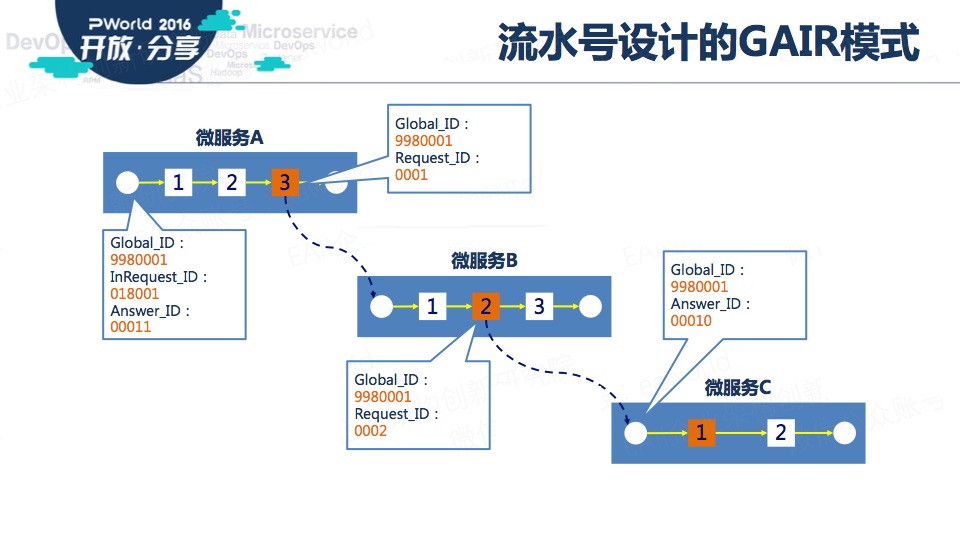
在记录流水和日志的过程中,我们需要唯一标识一笔服务调用。站在IT全局的视角来看,我们需要记录并能在适当的时候还原整个调用链。出现数据不一致时,我们要进行补偿操作,又需要能够定位错误发生时的数据状态……
这些都需要以“流水号”为基础,这就带来了微服务架构的第二个范式——流水号的GAIR(盖尔)模式。

G、A、I、R分别代表:Global_ID(全局流水号)、Answer_ID(响应流水号)、InRequest_ID(外部请求流水号)、Request_ID(内部请求流水号)
这四个流水号的产生方、产生时机各不相同,下图展示了它们之间的区别和联系。
三、元数据驱动的微服务定义
第三个范式是“元数据驱动的微服务定义”
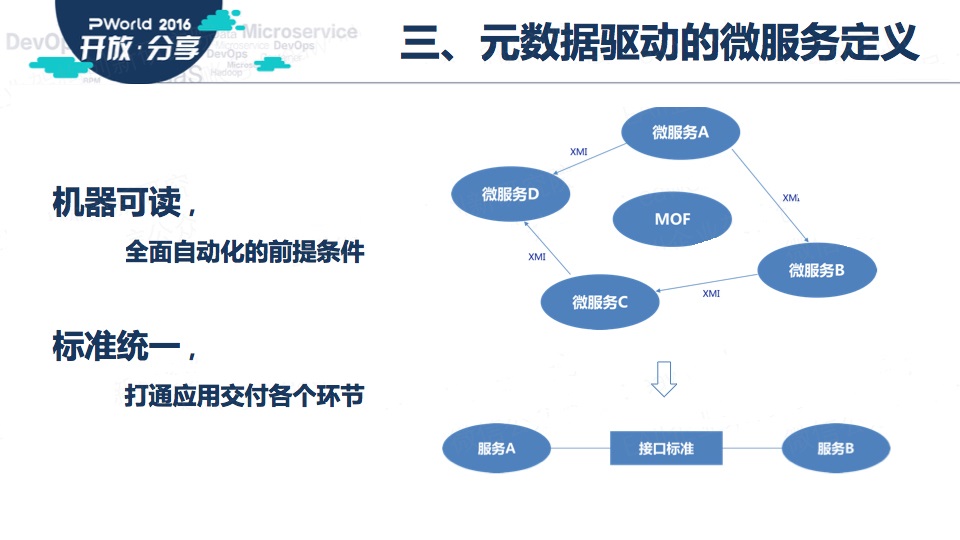
以元数据的方式定义微服务带来两个好处。
一、机器可读,这给未来全面自动化提供了前提条件。
二、标准统一,这给服务在整个交付环节中的横向打通提供了支撑。
我们在实践中,以元数据方式,定义了服务接口数据的结构、每个数据项所遵循的数据标准、每个服务接收请求数据时的校验规则和值转换规则等等。

这些元数据提供给专门的服务治理系统、数据治理系统、DevOps平台,从而构建出数字化IT。
四、同步模式异步化
在移动互联的外部环境中,微服务化的IT系统如何应对不确定的并发请求、超量请求?同时还要兼顾我们所连接的外部系统的网络中断、宕机等服务不可用、超时等一系列问题。
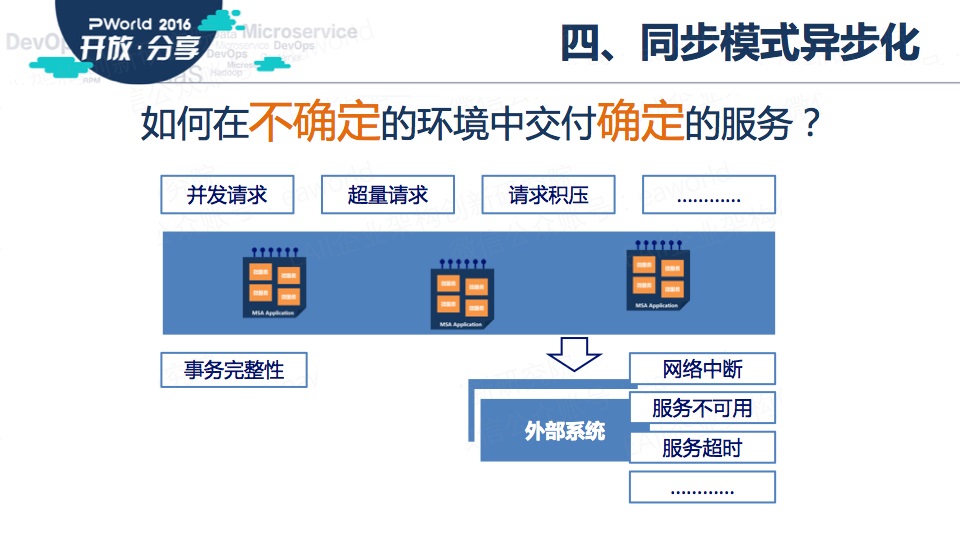
要解决这些问题,需要运用我们的第四个范式:以异步的方式处理同步调用。
在实践中,我们所使用的异步方式和传统异步不太一样。
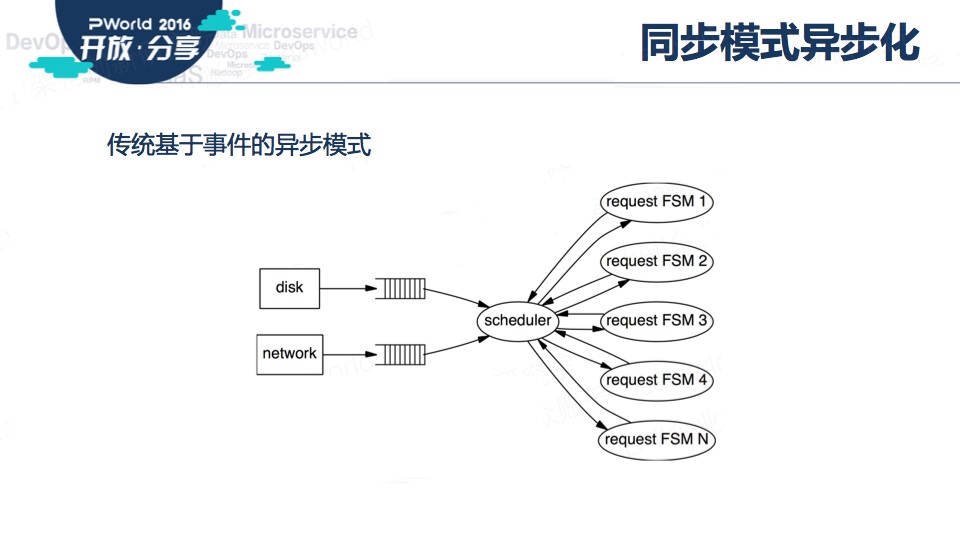
传统基于事件的异步,每个并发流作为一个有限状态机,应用直接控制并发,随着负载的增加,吞吐量会饱和,响应时间也会线性增长。
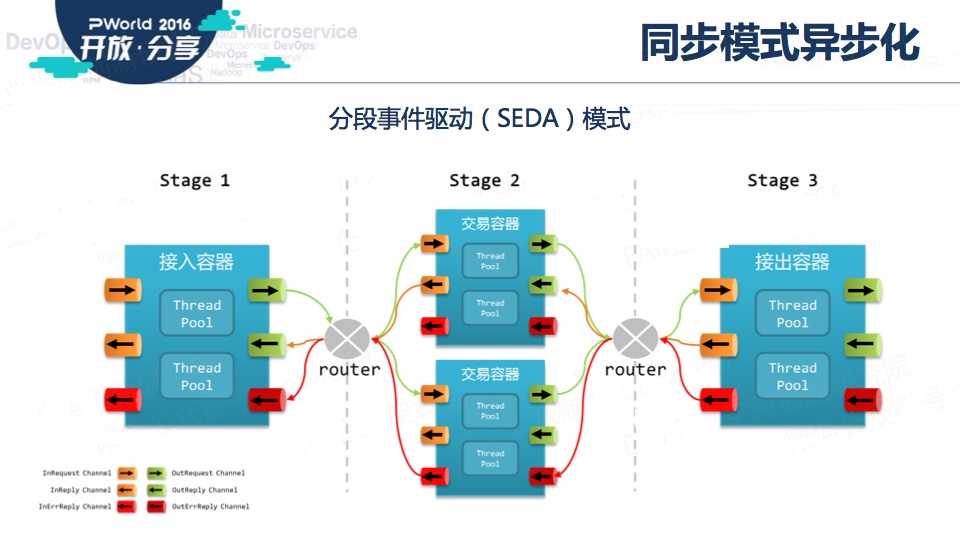
我们使用SEDA(Staged Event Driven Architecture),将接入、接出与逻辑处理相隔离,根据不同的业务操作类型合理分组,分别对待。
关于SEDA的详细介绍,请大家参看以前在群里的分享《为什么选择SEDA作为云平台的基础消息处理架构》
五、进程间服务无状态
接下来是第五个范式:进程间服务无状态。
什么是状态?首先,我们这里所说的状态是一种数据。如果一个数据需要在多个服务之间共享才能完成一笔交易,那么这个数据就被称为状态。
依赖这个状态的服务,就是有状态服务。否则,就是无状态服务。
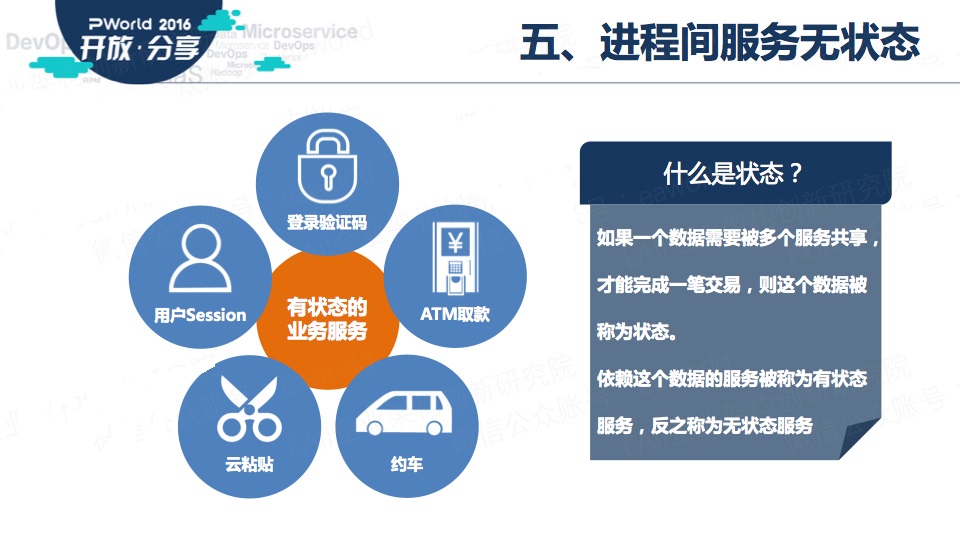
在业务上,状态的共享是不可避免的。典型的用户Session、现在新出现的云粘贴、网约车都是需要状态在不同服务间共享的场景。
但在技术实现上,考虑到系统的可伸缩性,我们又需要做到无状态化处理。
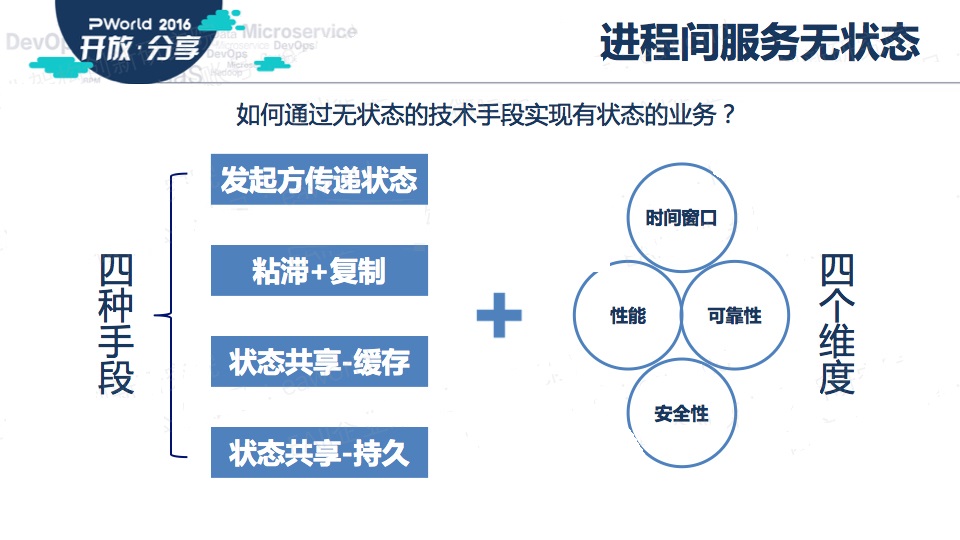
具体有四种手段:
一、请求方持有状态,每次调用时传递给服务提供方
二、粘滞+复制,这种技术并不新鲜,传统的JavaEE应用服务器集群就采用这种方式。这种方式对应用来说简单有效,但需要中间件支持。
后面两种手段类似,都可以称为状态共享
一种是,把状态保存在分布式缓存中
另一种,把状态保存在持久化数据库中
区别也显而易见,在此不做赘述。
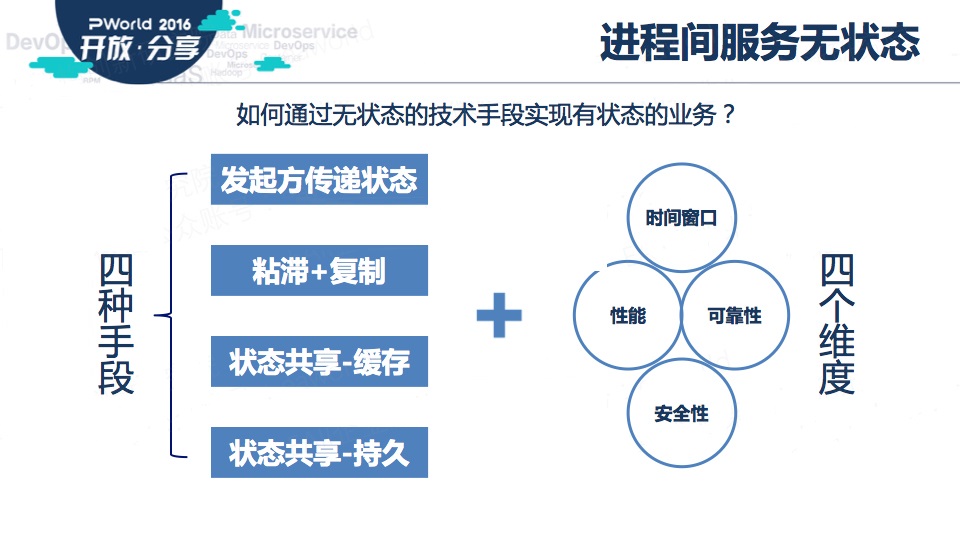
具体使用哪种方式,要从多个维度综合考量,这里列出了我们经常考量的几个维度:时间窗口、性能、可靠性、安全性。
六、保证最终数据一致性
接下来是微服务架构下的数据一致性问题。这是一个大课题,概括的讲,我们可能需要转变思路,考虑采用柔性事务,使得数据达到最终一致。
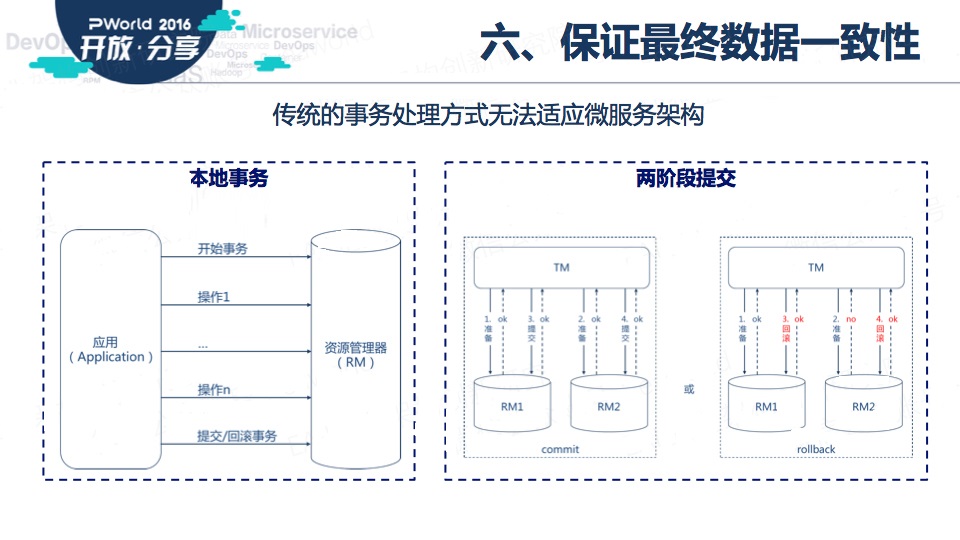
当然,有些场景是必须要追求强一致性的,那么我们可能要在设计服务时就要考虑,是不是可以不分布。毕竟,“低耦合”是美好的,但同时还要有“高内聚”。
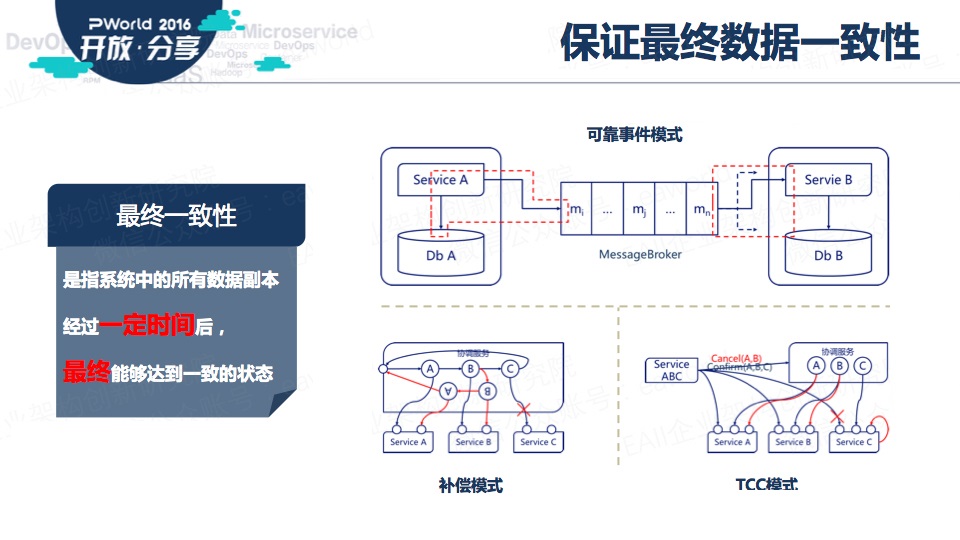
保证数据最终一致性有三种模式:
1、可靠事件模式
2、补偿模式
3、TCC模式
关于这三种模式的详细资料,以前在群里也做过分享《微服务架构下的数据一致性保证(一)》、《微服务架构下的数据一致性保证(二)》、《微服务架构下的数据一致性保证(三)》
七、用编排实现微服务组合
前面讲了这些模式,从架构角度来看挺清楚,确实也应该这么做。但是从工程角度来看,实施起来难度其实也不小。微服务之间的调用超时、事务、异步、状态等等,要做到代码写好,不出错,恐怕也是一个门槛比较高的事情。
所以,我们强调:用编排方式实现微服务的组合。

无论是配置式的编排,还是图形式的编排,都可以大大降低编程复杂度,使得一些很好的架构思想不会因为工程实现上的复杂和高门槛,而难以落地,最终成为空谈。
如果大家对编排方式实现微服务的组合没有直观的感觉,推荐大家访问:ifttt.com,一试便知。
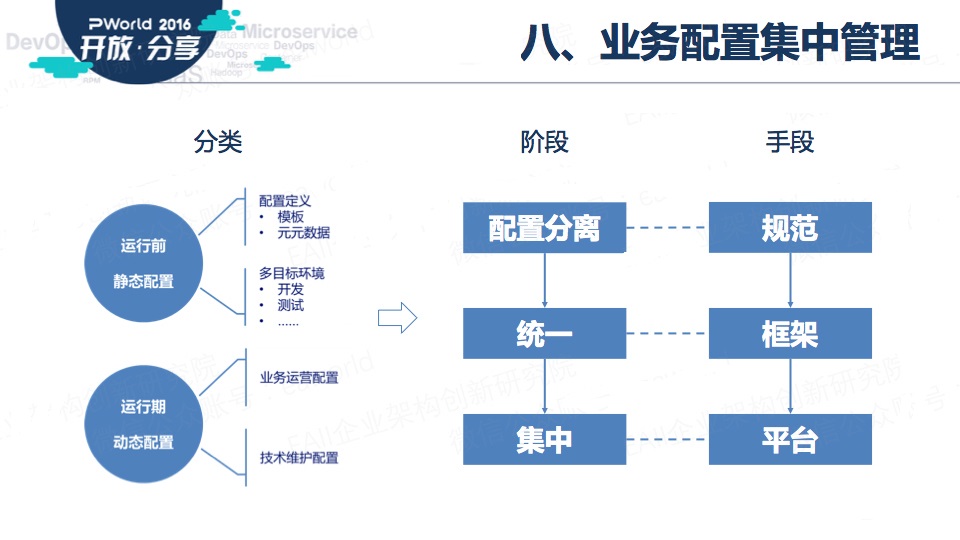
八、业务配置集中管理
最后一个范式是:业务配置集中管理
记得前两天有位群友问我,docker启动时,如何根据不同的参数动态加载面向测试、生产环境的配置。
这个问题的答案就是业务配置集中管理。
其实技术上,业务配置集中管理没有什么太多的难点。我们需要做的是有一个切实可行的步骤来逐步实现。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

