深入native层死抠Handler
Handler算是面试里面最大几率被问到的问题了,很多同学也能回答上来一些东西,像什么Looper、MessagerQueue啊(看这里),但是如果想知道一个人是否有专研精神的话,其实handler可以一直往下问。例如postDelayed是怎么实现的?(看这里)
问到了这里其实对于绝大多数面试其实已经够了,但是如果你面的公司比较看重基础或者面试官想看看你是否有专研精神,他可能会继续问MessageQueue.nativePollOnce
- 如何做到等待一段时间?
- 在有消息到来的时候是如何被唤醒的?
这部分其实已经到了native层的知识了,但是作为一个高级安卓工程师,这部分的知识其实多了解一点也是好的。
MessageQueue.nativePollOnce的c层实现在/frameworks/base/core/jni/android_os_MessageQueue.cpp,我们从这里开始往下挖:
// /frameworks/base/core/jni/android_os_MessageQueue.cpp
static void android_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj,
jlong ptr, jint timeoutMillis) {
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->pollOnce(env, obj, timeoutMillis);
}
...
// /frameworks/base/core/jni/android_os_MessageQueue.cpp
void NativeMessageQueue::pollOnce(JNIEnv* env, jobject pollObj, int timeoutMillis) {
mPollEnv = env;
mPollObj = pollObj;
mLooper->pollOnce(timeoutMillis);
mPollObj = NULL;
mPollEnv = NULL;
if (mExceptionObj) {
env->Throw(mExceptionObj);
env->DeleteLocalRef(mExceptionObj);
mExceptionObj = NULL;
}
}
...
// /system/core/libutils/Looper.cpp
int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) {
...
result = pollInner(timeoutMillis);
...
}
// /system/core/libutils/Looper.cpp
int Looper::pollInner(int timeoutMillis) {
...
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
...
}
中间我省略了很多代码,感兴趣的可以自行查看,这里最重要的是最后它使用了一个叫做epoll_wait的方法。如果有做过Linux下的c/c++开发的话可能会对它比较熟悉。它是epoll模型的方法,是Linux提供的一种IO多路复用的机制。一般情况下会和其他两种模型select和poll进行比较。
io多路复用
io多路复用可能做过服务器的同学会比较熟悉,在java里面提供的NIO模型也是干这活的。
我来稍微解释一下什么叫做io多路复用。我们普通的io流都是阻塞的,当io流里面数据还没有准备好的时候就会阻塞在那。所以当需要处理多个io例如服务器与多个客户端连接的时候,如果用普通的io那就只能有多少个客户端连接就创建多少个线程:
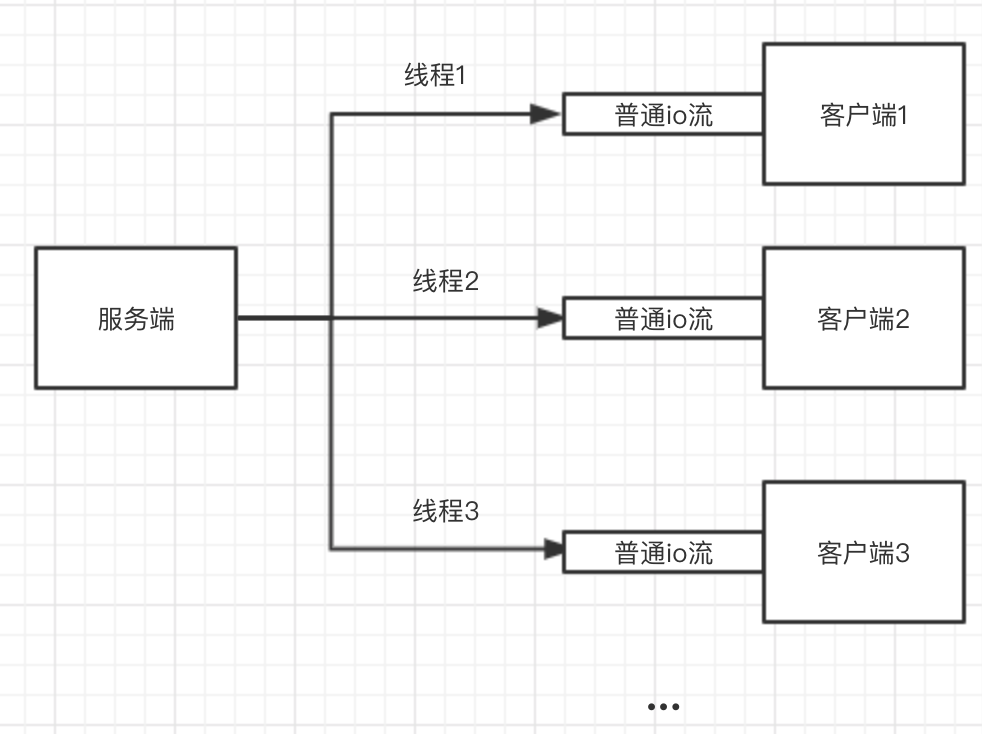
这样的架构有几个问题:
- 服务器数量是有限的
- 可能有很多的连接一直处于空闲状态
而io多路复用则只需要一条线程去检测多个io流,如果所有io流都没有消息的时候就会阻塞,当任意一条或者多条io流有消息的时候,就会返回:
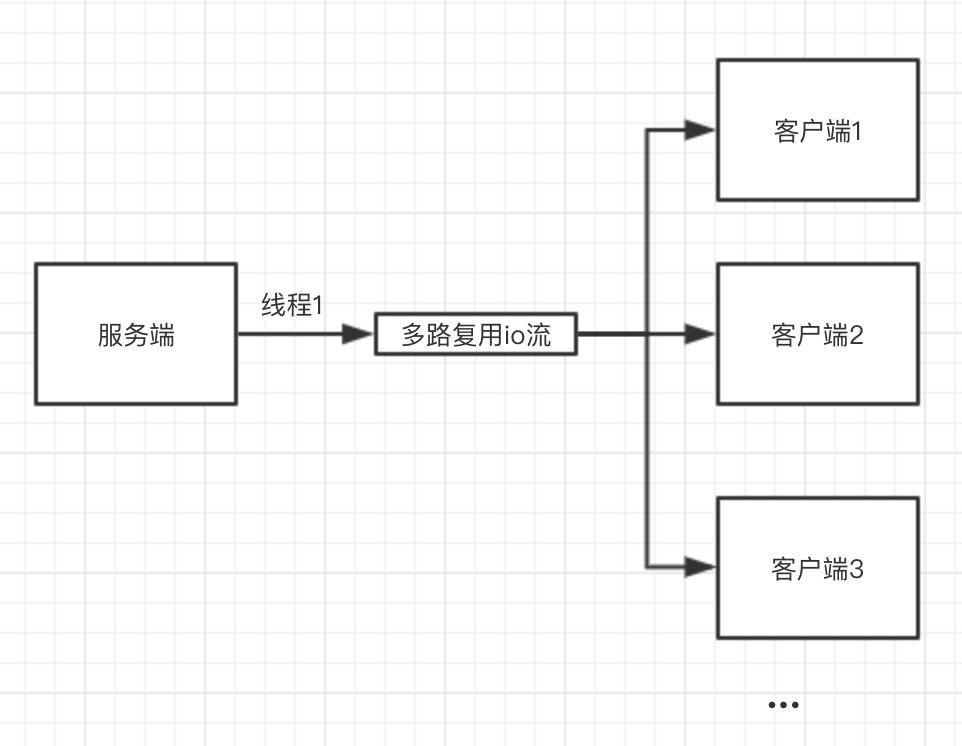
例如多人聊天室就是一种非常适合io多路复用的例子,可能会同时有很多个用户登录,但是不会同时在同一个时刻发言。如果用普通io模型,则需要开很多的线程,大部分线程是空闲的,而且在处理多个客户的消息的时候需要切换线程,对系统来讲也是比较重的。而使用io多路复用则可以重复使用一条线程,减少线程空闲和切换的情况。
当然大多数情况下,io多路复用和多线程也是配合起来使用的,这样也能重复发挥主机的多核性能。
Handler是如何使用epoll模型的
前面讲到的是io多路复用的概念,但是看起来和我们的handler好像没有什么关系是吗?毕竟handler看起来并不需要使用到io流。
但是io流的一些特性让它经常被用在各种消息框架中。
例如,当没有io流没有数据的时候epoll_wait会阻塞,而当消息到来的时候它会返回。这个特性可以用来实现MessageQueue的阻塞等待消息。
又例如epoll_wait的最后一个参数可以设置超时,等待一段确定的时间时候就算io流中没有消息也会返回。这个特性可以用来实现postDelay。
那io流的意思是不是说handler底层是通过读写文件实现的呢?性能会不会很低?
Linux早就对这个场景有所考量。所以这里epoll_wait监听的不是普通的文件读写,而是专门为事件通知优化过的文件描述符,它实际上并没有做文件的读写:
mWakeEventFd = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);
它使用起来和一般的文件很像,有三个主要方法:
- write 往描述符中写入一个n,内部的计算器会+n
- read 从描述符中读取一个整数,如果内部计数器为0则会阻塞,如果不为0则分两种情况,1是创建的时候设置了EFD_SEMAPHORE,就会返回1,且计数器减一,否则返回计数器的值,且计数器归零
- close 关闭描述符
所以当有消息到来的时候我们会最终调到write方法往描述符里+1:
// Handler.java
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
...
return enqueueMessage(queue, msg, uptimeMillis);
}
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
...
return queue.enqueueMessage(msg, uptimeMillis);
}
// MessageQueue.java
boolean enqueueMessage(Message msg, long when) {
...
if (needWake) {
nativeWake(mPtr);
}
}
// /frameworks/base/core/jni/android_os_MessageQueue.cpp
static void android_os_MessageQueue_nativeWake(JNIEnv* env, jclass clazz, jlong ptr) {
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->wake();
}
// /frameworks/base/core/jni/android_os_MessageQueue.cpp
void NativeMessageQueue::wake() {
mLooper->wake();
}
// /system/core/libutils/Looper.cpp
void Looper::wake() {
...
uint64_t inc = 1;
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
...
}
写入成功之后前面看到的epoll_wait就会被唤醒,然后读取数据将计数器归零:
// /system/core/libutils/Looper.cpp
int Looper::pollInner(int timeoutMillis) {
...
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
...
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
if (fd == mWakeEventFd) {
if (epollEvents & EPOLLIN) {
awoken();
} else {
ALOGW("Ignoring unexpected epoll events 0x%x on wake event fd.", epollEvents);
}
}
...
}
...
}
void Looper::awoken() {
...
uint64_t counter;
TEMP_FAILURE_RETRY(read(mWakeEventFd, &counter, sizeof(uint64_t)));
}
epoll模型的使用简介
epoll模型实际上有三个重要方法:
epoll_create
创建一个epoll专用的文件描述符,它就是那个多路复用的io,可以用来监听其他多个文件描述符
// /system/core/libutils/Looper.cpp static const int EPOLL_SIZE_HINT = 8; ... mEpollFd = epoll_create(EPOLL_SIZE_HINT);
它的参数是一个整数设置它最多可以监听多少个文件描述符,而且从Linux 2.6.8开始这个参数可以省略只要传大于0的值就好,数量不需要指定上限。
我们看到这里安卓设置了个8,其实它不仅可以监听默认的mWakeEventFd,我们还可以添加自己定义的描述符给它去监听
epoll_ctl
那我们怎样添加文件描述符监听呢?就靠这个方法了:
// /system/core/libutils/Looper.cpp int result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);
这样就能将mWakeEventFd给add进去让mEpollFd监听
epoll_wait
这个方法其实介绍了蛮多了,它的功能就是阻塞监听add进来的描述符,只要其中任意一个或多个描述符可用或者超时时间到达就会返回。
而可用的描述符会被放到第二个参数传入的数组中
// /system/core/libutils/Looper.cpp struct epoll_event eventItems[EPOLL_MAX_EVENTS]; int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
select/poll
其实到了这里Handler的底层已经差不多了,但是一般select/poll/epoll三者都会被摆在一起讨论,所以我这里也简单介绍一下另外两者。
它们其实都是linux提供的io多路复用模型,区别在于
select底层使用了一个固定大小的set保存监听的描述符,所以对监听的数量有限制,最多是1024个。为什么是1024呢?因为默认情况下单个进程的文件描述符的个数最多是1024,可以用下面命令查看:
ulimit -n
但是由于这个set的存放原理是开辟了1024比特位的内存,然后直接将文件描述符这个整数对应的比特位置1,所以实际上它是对文件描述符的最大值有限制,也就是说就算你使用”ulimit -HSn 2048”命令将最大的描述符个数改成2048,也不能用两个select去监听所有的描述符。
poll就算为了解决这个问题存在的,它接收一个描述符数组去监听,没有限制描述符的最大个数。
但是select/和poll都有一个缺点,就是它们都需要遍历整个描述符集合或者数组才能知道哪个描述符是可用的,所以它时间实际复杂度是O(n)
而epoll直接将可用的描述符放在一起告诉用户所以它的时间复杂度是O(1),当然系统底层肯定是增加了复杂度才能让用户用起来方便的,不过不用担心,底层也是使用了红黑树这种高效的数据结构,所以epoll模型的整体时间复杂度还是比较select/poll高的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

