Skywalking第十篇——Trace收集(四)

前情提要
上一节介绍了 DictionaryManager 组件的具体实现以及它们与服务端同步的 RPC 定义 ,整体来看还是比较简单的。本节通过分析几个插件的实现,深入了解一下 ContextManager、TracingContext、TraceSegment 这些组建是怎么玩的,了解一下 skywalking-agent 中的数据流向是什么啥样的。首先是 Tomcat 插件,Skywalking 提供的 Tomcat 插件本身比较简单,但是要看懂这个插件的原理,需要对 Tomcat 本身的结构有一些了解。
Tomcat 架构简析


哎,先来简单看一下的 Tomcat 的架构,如下图所示(没自己手画,图片来自网络,侵删):
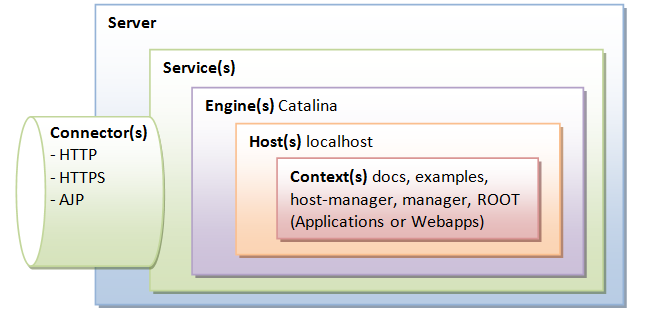
Connector 组件是 Tomcat 中两个核心组件之一,它的主要任务是负责接收客户端发起的 TCP 连接请求(其实就是创建相应的 Request 和 Response 对象),而请求的处理则是由 Container 来负责的。
Container 是容器的父接口,所有子容器都必须实现这个接口,Container 容器的设计用的是典型的责任链模式,它有四个子容器组件构成,分别是:Engine、Host、Context、Wrapper,这四个组件不是平行的,而是父子关系,Engine 包含 Host,Host 包含 Context,Context 包含 Wrapper。通常一个 Servlet class 对应一个 Wrapper,如果有多个 Servlet 就可以定义多个 Wrapper,如果有多个 Wrapper 就要定义一个更高的 Container 了,如 Context。 Context 还可以定义在父容器 Host 中,Host 不是必须的,但是要运行 war 程序,就必须要 Host,因为 war 中必有 web.xml 文件,这个文件的解析就需要 Host 了。如果要有多个 Host 就要定义一个顶级容器 Engine 了。而 Engine 没有父容器了,一个 Engine 代表一个完整的 Servlet 引擎。 这些组件在 Tomcat 的 server.xml 文件中都能找到相应的配置,用过 Tomcat 的童鞋都知道,不解释了。
下面这张图大致展示了从 Connector 开始接收请求,然后请求一步步经过 Engine、Host、Context、Wrapper,最终 Servlet 的流程 (图片来自网络,侵删) :
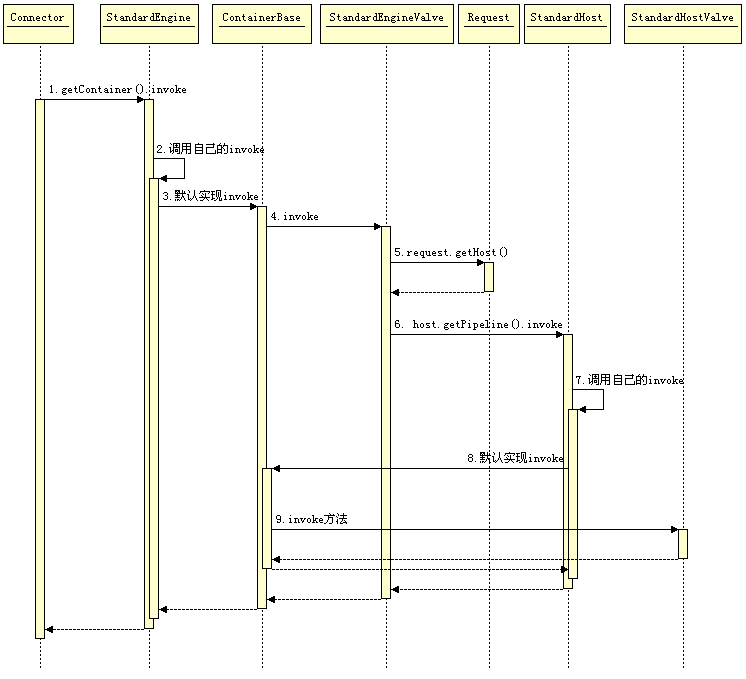
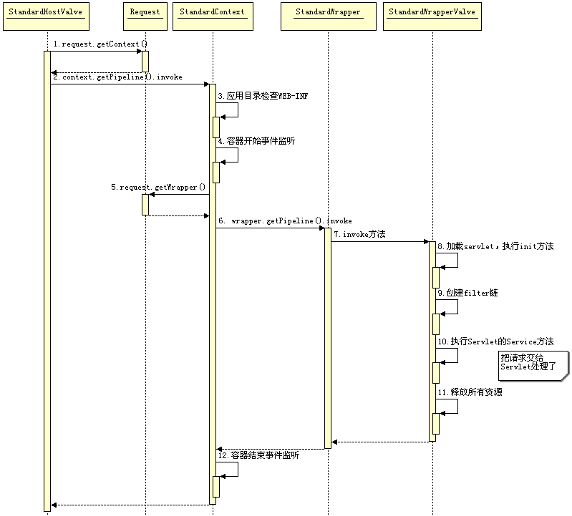
其实容器的本质是一个 Pipeline,我们可以在这个Pipeline 上增加任意的 Valve,处理请求 Tomcat 线程会挨个执行这些 Valve 最终完成请求的处理,而且四个组件都会有自己的一套 Valve 集合,例如上图中的 StandEngineValve、 StandHostValve 、 StandContextValve 、 StandWrapperValve,我们也可以在 Tomcat 的 server.xml 文件中自定义Valve(实际工作中只会撸业务代码,很少有人这么玩)。这些标准的 Valve 都是当前 Container 中最后一个 Valve,它们会负责将请求传给它们的子容器,以保证处理逻辑能继续向下执行。看下面这张图就比较明确了哈(图片来自于网络,侵删):
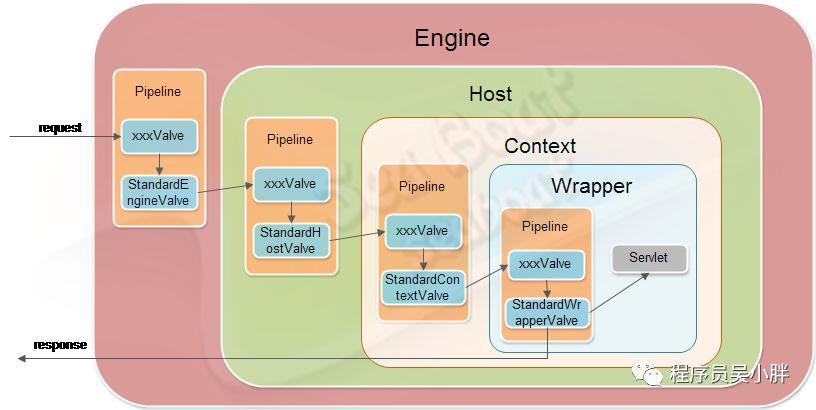
接着来看四个级别的容器分别是干啥的。
-
Engine作为顶层容器,接口比较简单,它只定义了一些基本的关联关系,它可以添加 Host 类型的子容器,没啥可说的。
-
一个 Host 在 Engine 中代表一个虚拟主机,这个虚拟主机的作用就是运行多个应用,它负责安装和展开这些应用,并且标识这个应用以便能够区分它们。它的子容器通常是 Context,它除了关联子容器外,还有就是保存一个主机应该有的信息。
-
Context 代表 Servlet 的 Context,它具备了 Servlet 运行的基本环境,理论上只要有 Context 就能运行 Servlet 了,也就是说 Tomcat 可以没有 Engine 和 Host。Context 最重要的功能就是管理它里面的 Servlet 实例,并和 Request 一起正确地找到处理请求的 Servlet。Servlet 实例在 Context 中是以 Wrapper 出现的。
-
Wrapper 代表一个 Servlet,它负责管理一个 Servlet,包括的 Servlet 的装载、初始化、执行以及资源回收。Wrapper 是最底层的容器,它没有子容器了。
Tomcat 插件分析

来看 tomcat-7.x-8.x-plugin 这个插件,这是 Skywalking 提供给 Tomcat 7 和 Tomcat 8 的插件。在其 skywalking-plugin.def 文件中定义了 TomcatInstrumentation 和 ApplicationDispatcherInstrumentation 插件类。
先看 TomcatInstrumentation.enhanceClass()方法,确定它拦截的是 Tomcat 中的哪个类呢?
protected ClassMatch enhanceClass() {
return byName("org.apache.catalina.core.StandardHostValve");
}
StandardHostValve 是 Host容器中最后一个Valve,核心方法是 invoke() 方法,该方法中会通过 request 找到匹配的 Context 对象,并调用其 Pipeline 中的第一个 Valve处理请求,大致实现如下所示:
public final void invoke(Request request, Response response){
// 省略其他非核心代码,并略作简化
Context context = request.getContext();
context.getPipeline().getFirst().invoke(request, response);
Throwable t = (Throwable) request.getAttribute(RequestDispatcher.ERROR_EXCEPTION);
if (response.isErrorReportRequired()) {
if (t != null) { // 出现异常的话,会调用 throwable()方法处理
throwable(request, response, t);
}
}
}
接着看 TomcatInstrumentation.getInstanceMethodsInterceptPoints()方法,它返回了两个 InstanceMethodsInterceptPoint 对象,一个拦截 invoke()方法,一个拦截 throwable()方法。
先来看拦截 invoke()方法的 TomcatInvokeInterceptor,它的 beforeMethod() 方法核心就是创建 EntrySpan,大致上线如下:
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments,
Class<?>[] argumentsTypes, MethodInterceptResult result) throws Throwable {
// invoke()方法的第一个参数就是 HttpServletRequest对象
HttpServletRequest request = (HttpServletRequest)allArguments[0];
// 创建一个空的 ContextCarrier对象
ContextCarrier contextCarrier = new ContextCarrier();
// 这段骚操作一会儿需要好好说说,不认真看,很容易懵逼
CarrierItem next = contextCarrier.items();
while (next.hasNext()) {
next = next.next();
next.setHeadValue(request.getHeader(next.getHeadKey()));
}
// 创建 TracingContext,创建 EntrySpan
// 这里的第一个参数就是前面多次看到的 operationName,这个场景下就是请求的 URI
AbstractSpan span = ContextManager.createEntrySpan(request.getRequestURI(), contextCarrier);
// 为 EntrySpan添加 Tag
Tags.URL.set(span, request.getRequestURL().toString());
Tags.HTTP.METHOD.set(span, request.getMethod());
span.setComponent(ComponentsDefine.TOMCAT); // 设置 component字段
SpanLayer.asHttp(span); // 设置 layer字段
}
CarrierItem 有三个核心字段:
private String headKey, headValue; // 存储键值对
private CarrierItem next; // 指向下一个 CarrierItem对象
这样, CarrierItem 既可以存储键值对,也可以串成一个链表,好吧,CarrierItem 还真实现了 Iterator 接口。
在 ContextCarrier.items() 方法中,会根据当前 Skywalking Agent 的配置创建一个 CarrierItem 链表:
public CarrierItem items() {
CarrierItemHead head;
// 同时支持 V1 和 V2两个版本(对应 Skywalking 3和6两个大版本)的代码逻辑
if (Config.Agent.ACTIVE_V2_HEADER && Config.Agent.ACTIVE_V1_HEADER) {
SW3CarrierItem carrierItem = new SW3CarrierItem(this, null);
SW6CarrierItem sw6CarrierItem = new SW6CarrierItem(this, carrierItem);
head = new CarrierItemHead(sw6CarrierItem);
} // 省略只支持 V1和 V2版本的相关代码
return head;
}
从 TomcatInvokeInterceptor .beforeMethod()方法的逻辑中可以看到,之后从 Http 请求的 Header 中获取对应的 value 值记录到对应 CarrierItem 中。setHeadValue() 方法会调用 ContextCarrier.deserialize() 方法解析该 value 值并初始化 ContextCarrier 中的各个字段,这里以 SW6CarrierItem 为例进行介绍(这里省略一些try/catch代码块和边界检查):
ContextCarrier deserialize(String text, HeaderVersion version) {
if (HeaderVersion.v2.equals(version)) {
String[] parts = text.split("//-", 9);
// parts[0] is sample flag, always trace if header exists.
this.primaryDistributedTraceId = new PropagatedTraceId(Base64.decode2UTFString(parts[1]));
this.traceSegmentId = new ID(Base64.decode2UTFString(parts[2]));
this.spanId = Integer.parseInt(parts[3]);
this.parentServiceInstanceId = Integer.parseInt(parts[4]);
this.entryServiceInstanceId = Integer.parseInt(parts[5]);
this.peerHost = Base64.decode2UTFString(parts[6]);
this.entryEndpointName = Base64.decode2UTFString(parts[7]);
this.parentEndpointName = Base64.decode2UTFString(parts[8]);
}
return this;
}
这就填满了 ContextCarrier 的 8 个字段咯,╮(╯_╰)╭ 。
接下来看,ContextManager.createEntry() 方法的实现,前面说过其核心是调用 getOrCreate() 方法获取/创建当前 TracingContext 对象,然后调用 TracingContext.createEntry() 方法创建(或是重新 start )当前 EntrySpan 对象,这里更详细的说一下一些实现细节吧。
ContextManager.createEntry() 方法首先会检测当前 ContextCarrier 是否合法,其实就是检查 ContextCarrier 的8个核心字段是否填充好了,如果合法,就证明是上游有 Trace 信息传递下来了:
public static AbstractSpan createEntrySpan(String operationName, ContextCarrier carrier) {
SamplingService samplingService = ServiceManager.INSTANCE.findService(SamplingService.class);
AbstractSpan span;
AbstractTracerContext context;
if (carrier != null && carrier.isValid()) { // 检测 ContextCarrier是否合法,
samplingService.forceSampled();
context = getOrCreate(operationName, true);
span = context.createEntrySpan(operationName);
// 从 ContextCarrier中提取上有的 TraceId、TraceSegmentRef等信息,
// 将当前 TraceSegment与上游的 Trace串联起来
context.extract(carrier);
} else { // 上游没有 Trace信息,这里就用全新的 TraceId等
context = getOrCreate(operationName, false);
span = context.createEntrySpan(operationName);
}
return span;
}
行吧,TomcatInvokeInterceptor 的 beforeMethod()方法大概就是这样,它的 afterMethod()方法就简单很多了:
public Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments,
Class<?>[] argumentsTypes, Object ret) throws Throwable {
// invoke()方法的第二个参数是 HttpServletResponse
HttpServletResponse response = (HttpServletResponse)allArguments[1];
AbstractSpan span = ContextManager.activeSpan(); // 获取当前 Span
if (response.getStatus() >= 400) {
// 如果响应码是400以上,就是标记当前Span的errorOccurred字段,还要打个 Tag
span.errorOccurred();
Tags.STATUS_CODE.set(span, Integer.toString(response.getStatus()));
}
ContextManager.stopSpan(); // 尝试关闭 Span
// FORWARD_REQUEST_FLAG的含义后面再说
ContextManager.getRuntimeContext().remove(Constants.FORWARD_REQUEST_FLAG);
return ret;
}
TracingContext.stopSpan() 方法的具体在前面已经详细分析过了,其中会调用 StackBasedTracingSpan.finish() 方法尝试关闭当前 Span,这里会检测该 Span 的 operationId 字段,如果为空,则尝试再次通过 DictionaryManager组件用 operationName 换取 operationId,具体代码就不贴了。
接下来看 tomcat-7.x-8.x-plugin 中的另一个插件类——ApplicationDispatcherInstrumentation,它拦截的是 Tomcat 的 ApplicationDispatcher.forward()方法以及 ApplicationDispatcher 的全部构造方法。 forward()方法 主要处理 forward 跳转,写过 JSP 和 Servlet 程序的童鞋应该都知道 forward 和 redirect 的知识点,不展开说了。
ForwardInterceptor的实现比较简单,其 onConstruct ()方法如下:
public void onConstruct(EnhancedInstance objInst, Object[] allArguments) {
// 记录 ApplicationDispatcher的第二个参数,即跳转到的 uri地址
objInst.setSkyWalkingDynamicField(allArguments[1]);
}
beforeMethod()方法 和 afterMethod()方法的实现大致如下:
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
MethodInterceptResult result) throws Throwable {
if (ContextManager.isActive()) {
AbstractSpan abstractTracingSpan = ContextManager.activeSpan();
Map<String, String> eventMap = new HashMap<String, String>();
eventMap.put("forward-url", objInst.getSkyWalkingDynamicField() == null ? "" : String.valueOf(objInst.getSkyWalkingDynamicField()));
// 通过 log的方式将跳转到的 uri记录到该当前 Span中
abstractTracingSpan.log(System.currentTimeMillis(), eventMap);
ContextManager.getRuntimeContext().put(Constants.FORWARD_REQUEST_FLAG, true);
}
}
// afterMethod()方法就是清除 FORWARD_REQUEST_FLAG标记而已,不再粘贴代码
到这里, tomcat-7.x-8.x-plugin 插件的具体实现就分析完了。
Dubbo 插件分析

要搞清楚 Skywalking 提供的 Dubbo 插件的工作原理,需要先了解一下 Dubbo 中的 Filter 机制。 Filter 在很多 框架中都有使用过这个概念,基本上的作用都是类似的,在请求处理前后做 一些通用的逻辑,而且Filter可以有多个,支持层层嵌套。
Dubbo 的 Filter 概念基本上符合我们正常的预期理解,而且 Dubbo 官方针对 Filter 做了很多的原生支持,包括我们熟知的 RpcContext、accesslog、monitor 功能都是通过 Filter 来实现的。 Filter 也是 Dubbo 用来实现功能扩展的重要机制, 我们可以通过自定义 Filter 实现、启停指定 Filter 来改变 Dubbo 的行为来实现需求。
行吧, 简单看一下 Dubbo Filter 相关的知识点。 首选是构造 Dubbo Filter Chain 的入口 是在 ProtocolFilterWrapper.buildInvokerChain() 方法处,它将加载到的 Dubbo Filter 实例串成一个 Chain(这里):
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
// 最开始的last是指向invoker参数的,猜都知道,这是我们提供的业务服务(Provider/Consumer)
Invoker<T> last = invoker;
// 加载Filter
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class)
.getActivateExtension(invoker.getUrl(), key, group);
// 遍历 filters集合,将 Filter封装成 Invoker并串联成一个 Chain
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new Invoker<T>() {
@Override
public Result invoke(Invocation invocation) throws RpcException {
Result asyncResult;
try {
// 执行当前 Filter的逻辑,在 Filter中会调用下一个Invoker.invoke()方法,
// 触发下一个 Filter。后面分析 MonitorFilter的实现时,会看到这个调用
asyncResult = filter.invoke(next, invocation);
} catch (Exception e) {
Filter.Listener listener = ((ListenableFilter) filter).listener();
listener.onError(e, invoker, invocation);
throw e;
}
return asyncResult;
}
// 其他方法的实现都委托给了 invoker参数(略)
};
}
// 整个调用是从CallbackRegistrationInvoker中会
return new CallbackRegistrationInvoker<>(last, filters);
}
这里的核心有两步,上面明显能看出来的是将 Filter 实例串成 Chain,另一个核心步骤就 是通过 ExtensionLoader 加载 Filter 对象,原理是SPI,但是 Dubbo 的 SPI 实现有点优化,但是原理和思想基本一样,看一下实现吧:
public List<T> getActivateExtension(URL url, String[] values, String group) {
List<T> exts = new ArrayList<T>();
// 所有用户自己配置的Filter信息(有些Filter是默认激活的,有些是配置激活的,这里这里的names就指的配置激活的Filter信息)
List<String> names = values == null ? new ArrayList<String>(0) : Arrays.asList(values);
// 如果这些名称里不包括去除default的标志(-default),default表示的是 Dubbo默认的是 Filter集合
if (! names.contains(Constants.REMOVE_VALUE_PREFIX + Constants.DEFAULT_KEY)) {
getExtensionClasses(); // 加载 Filter,会将 Filter实例放到cachedActivates集合中
for (Map.Entry<String, Activate> entry : cachedActivates.entrySet()) {
String name = entry.getKey(); // name指的是SPI读取的配置文件的key
Activate activate = entry.getValue();
//group主要是区分当前服务是 Provider端还是 Consumer端
if (isMatchGroup(group, activate.group())) {
T ext = getExtension(name);
//这里以Filter为例:三个判断条件的含义依次是:
//1.用户配置的Filter列表中不包含当前ext
//2.用户配置的Filter列表中不包含当前ext的加-的key
//3.如果用户的配置信息(url中体现)中有可以激活的配置key并且数据不为0,false,null,N/A,也就是说有正常的使用
if (! names.contains(name)
&& ! names.contains(Constants.REMOVE_VALUE_PREFIX + name)
&& isActive(activate, url)) {
exts.add(ext);
}
}
}
//根据 @Activate注解上的order属性排序
Collections.sort(exts, ActivateComparator.COMPARATOR);
}
// 进行到此步骤的时候Dubbo提供的原生的Filter已经被添加完毕了,下面处理用户自己扩展的Filter
List<T> usrs = new ArrayList<T>();
for (int i = 0; i < names.size(); i ++) {
String name = names.get(i);
// 如果单个name不是以"-"开头并且所有的key里面并不包含-'name'(也就是说如果配置成了"dubbo,-dubbo"这种的可以,这个if是进不去的)
if (! name.startsWith(Constants.REMOVE_VALUE_PREFIX)
&& ! names.contains(Constants.REMOVE_VALUE_PREFIX + name)) {
//可以通过default关键字替换Dubbo原生的Filter链,主要用来控制调用链顺序
if (Constants.DEFAULT_KEY.equals(name)) {
if (usrs.size() > 0) {
exts.addAll(0, usrs);
usrs.clear();
}
} else {
T ext = getExtension(name); //加入用户自己定义的扩展Filter
usrs.add(ext);
}
}
}
if (usrs.size() > 0) {
exts.addAll(usrs);
}
return exts;
}
介绍完 Dubbo Filter 的原理之后,我们来看 MonitorFilter 实现,它用于记录一些监控信息,来看看它的 invoke() 方法的实现:
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
if (invoker.getUrl().hasParameter(MONITOR_KEY)) { // 检测是否开启了监控
// 添加KV,记录当前时间戳
invocation.setAttachment(MONITOR_FILTER_START_TIME, String.valueOf(System.currentTimeMillis()));
// 记录并发量
getConcurrent(invoker, invocation).incrementAndGet();
}
return invoker.invoke(invocation); // 调用后续的 Dubbo Filter
}
有个地方记录开始时间、增加并发量,必然有个地方计算请求耗时、减掉并发量, 在哪里呢?在 MonitorListener 里面,它是 MonitorFilter 配套的 Listener,其 invoke() 方法实现如下:
public void onResponse(Result result, Invoker<?> invoker, Invocation invocation) {
if (invoker.getUrl().hasParameter(MONITOR_KEY)) { // 先来判断是否开启了监控功能
// 收集监控信息
collect(invoker, invocation, result, RpcContext.getContext().getRemoteHost(),
Long.valueOf(invocation.getAttachment(MONITOR_FILTER_START_TIME)), false);
// 降低并发度
getConcurrent(invoker, invocation).decrementAndGet();
}
}
在 collect()方法里面,会将监控信息整理成 URL 并缓存起来:
private void collect(Invoker<?> invoker, Invocation invocation, Result result, String remoteHost, long start, boolean error) {
URL monitorUrl = invoker.getUrl().getUrlParameter(MONITOR_KEY);
Monitor monitor = monitorFactory.getMonitor(monitorUrl);
// 将请求的处理时长、并发度以及请求结果等监控信息整理到URL中
URL statisticsURL = createStatisticsUrl(invoker, invocation, result, remoteHost, start, error);
// 缓存这个监控的URL
monitor.collect(statisticsURL);
}
DubboMonitor 实现了 Monitor 接口,其中有个 Map用于缓存 URL,然后在其构造方法中会启动一个定时任务,定时发送 URL:
// 用于缓存监控 URL
private final ConcurrentMap<Statistics, AtomicReference<long[]>> statisticsMap;
public DubboMonitor(Invoker<MonitorService> monitorInvoker, MonitorService monitorService) {
sendFuture = scheduledExecutorService.scheduleWithFixedDelay(() -> {
send(); // 发送监控
}, monitorInterval, monitorInterval, TimeUnit.MILLISECONDS);
}
在 DubboMonitor.collect()方法中会将相同的 URL 中的监控值累加,然后形成一个新的 URL 填充回 statisticsMap 集合,这里就不展开介绍了。
行了,Dubbo MonitorFilter 的基础知识介绍完了,开始 Skywalking Dubbo 插件的分析吧(终于开始正题了)。 apm-dubbo-2.7.x-plugin 插件的 skywalking-plugin.def 中定义的插件是 DubboInstrumentation,它拦截的是 MonitorFilter.invoke()方法,具体的 Interceptor 实现是 DubboInterceptor,在其 beforeMethod() 方法中会根据当前 MonitorFilter 所在的服务角色(Consumer/Provider)创建对应的 Span(ExitSpan/EntrySpan),具体实现如下:
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments,
Class<?>[] argumentsTypes, MethodInterceptResult result) throws Throwable {
Invoker invoker = (Invoker)allArguments[0];
Invocation invocation = (Invocation)allArguments[1];
RpcContext rpcContext = RpcContext.getContext();
boolean isConsumer = rpcContext.isConsumerSide();
URL requestURL = invoker.getUrl();
AbstractSpan span;
final String host = requestURL.getHost();
final int port = requestURL.getPort();
if (isConsumer) { // 检测是否为 Consumer
final ContextCarrier contextCarrier = new ContextCarrier();
// Consumer的话,需要创建 ExitSpan,具体的创建过程在后面会展开说
span = ContextManager.createExitSpan(generateOperationName(requestURL, invocation), contextCarrier, host + ":" + port);
CarrierItem next = contextCarrier.items(); // 创建 CarrierItem链表
while (next.hasNext()) {
next = next.next();
// 将当前 Trace信息序列化,然后填充到RpcContext,Dubbo在调用 Provider的时候,会把RpcContext传过去
rpcContext.getAttachments().put(next.getHeadKey(), next.getHeadValue());
}
} else { // 如果是 Provider的话
ContextCarrier contextCarrier = new ContextCarrier();
CarrierItem next = contextCarrier.items(); // 创建 CarrierItem链表
while (next.hasNext()) {
next = next.next();
// 反序列化 RpcContext中的Trace信息
next.setHeadValue(rpcContext.getAttachment(next.getHeadKey()));
}
// 创建 EntrySpan,这个过程在前面分析Tomcat插件的时候,详细分析过了
span = ContextManager.createEntrySpan(generateOperationName(requestURL, invocation), contextCarrier);
}
Tags.URL.set(span, generateRequestURL(requestURL, invocation)); // 设置 Tag
span.setComponent(ComponentsDefine.DUBBO);// 设置 component
SpanLayer.asRPCFramework(span); // 设置 SpanLayer
}
在 ContextManager.createExitSpan()方法中除了创建 ExitSpan 之外,还会调用 inject() 方法将 Trace 信息记录到 CarrierContext 中,这样后面通过CarrierItem 持久化的时候才有值。
DubboInterceptor.afterMethod() 方法实现比较简单,有异常就是通过 log 方式记录到当前 Span,最后尝试关闭当前 Span。
这一节挺长了,不总结了,本节结束撒花~~~
扫描下图二维码,关注【程序员吴小胖】
从底部 ”源码分析“菜单 即可获取
《Skywalking源码分析指北》全部文章哟~

看懂看不懂,都点个赞吧:+1:
正文到此结束
- 本文标签: consumer tag cat http 需求 parse 图片 web 参数 equals js dist UI Service App key 服务端 servlet provider 并发 线程 W3C 代码 遍历 executor apache 插件 ArrayList https build 配置 Atom CTO XML 工作原理 remote dubbo Agent find 主机 管理 cache 解析 二维码 HashMap struct 详细分析 安装 文章 TCP Collections Collection 源码 总结 缓存 tar core IDE plugin HTML list 本质 ip 同步 tk map ACE 时间 实例 IO ssl final 构造方法 src 数据 constant 程序员 value id tomcat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

