k8s系列教程2 - 核心概念和架构设计
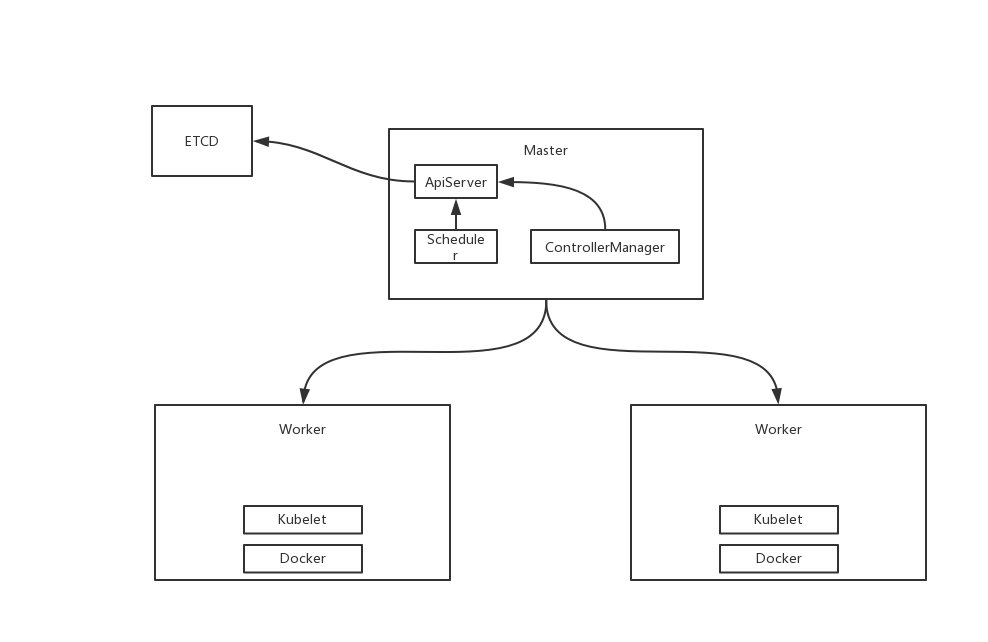
集群架构设计
Kubernetes 可以管理大规模的集群,使集群中的每一个节点彼此连接,能够像控制一台单一的计算机一样控制整个集群。
集群的节点有两种角色,一种是 master ,一种是 worker 。
- master 是集群的"大脑",负责管理整个集群:像应用的调度、更新、扩缩容等。
- worker 就是具体"干活"的,它上面事先运行着 docker 服务和 kubelet 服务( Kubernetes 的一个组件),当接收到 master 下发的"任务"后,Node 就要去完成任务(用 docker 运行一个指定的应用)
ETCD 作为存储的组件,负责存储k8s 的所有相关信息。
Scheduler 负责集群相关资源的调配,通过一系列的算法(预选、优选策略),调度某一个应用具体要运行在哪一个节点上。
ControllerManager 负责所有应用的控制,譬如应用的多副本控制。
ApiServer 是负责集群的通信,ETCD,Scheduler,ControllerManager 之间的通信都是通过该组件,是操作 kubernetes 的唯一入口。
核心概念
Deployment - 应用管理者
当我们拥有一个 Kubernetes 集群后,就可以在上面跑我们的应用了,前提是我们的应用必须支持在 docker 中运行,也就是我们要事先准备好docker镜像。
有了镜像之后,一般我们会通过Kubernetes的 Deployment 的配置文件去描述应用,比如应用叫什么名字、使用的镜像名字、要运行几个实例、需要多少的内存资源、cpu 资源等等。
有了配置文件就可以通过Kubernetes提供的命令行客户端 - kubectl 去管理这个应用了。kubectl 会跟 Kubernetes 的 master 通过RestAPI通信,最终完成应用的管理。创建应用之后,就由 Kubernetes 来保证我们的应用处于运行状态,当某个实例运行失败了或者运行着应用的 Node 突然宕机了,Kubernetes 会自动发现并在新的 Node 上调度一个新的实例,保证我们的应用始终达到我们预期的结果。

Pod - Kubernetes最小调度单位
出于易用性、灵活性、稳定性等的考虑,Kubernetes 提出了一个叫做 Pod 的概念,作为 Kubernetes 的最小调度单位。我们的应用在每个 Node 上运行的其实是一个 Pod。Pod 也只能运行在 Node 上。
那么什么是 Pod 呢?Pod 是一组容器(当然也可以只有一个)。容器本身就是一个小盒子了,Pod 相当于在容器上又包了一层小盒子。这个盒子里面的容器有什么特点呢?
- 可以共享存储。
- 有相同的网络空间,通俗点说就是有一样的ip地址,有一样的网卡和网络设置。
- 多个容器之间可以“了解”对方,比如知道其他人的镜像,知道别人定义的端口等。
其中的 Pause 容器
- 作为根容器,把其他容器link 到一起
- 负责整个pod的监控检查
至于这样设计的好处呢,还是要大家深入学习后慢慢体会啦~

ReplicaSet - 管理Pod的组件
kubernetes 官方现在已经弱化了 ReplicaSet 的概念,在实际的操作,我们一般不会接触到 ReplicaSet,但 Pod 的实际管理是由ReplicaSet负责的。
Service - 服务发现 - 找到每个Pod
上面的 Deployment 创建了,Pod 也运行起来了。如何才能访问到我们的应用呢?
最直接想到的方法就是直接通过 Pod-ip+port 去访问,但如果实例数很多呢?好,拿到所有的 Pod-ip 列表,配置到负载均衡器中,轮询访问。但上面我们说过,Pod 可能会死掉,甚至 Pod 所在的 Node 也可能宕机,Kubernetes 会自动帮我们重新创建新的Pod。再者每次更新服务的时候也会重建 Pod。而每个 Pod 都有自己的 ip。所以 Pod 的ip 是不稳定的,会经常变化的。
面对这种变化我们就要借助另一个概念:Service。它就是来专门解决这个问题的。不管Deployment的Pod有多少个,不管它是更新、销毁还是重建,Service总是能发现并维护好它的ip列表。Service对外也提供了多种入口:
- ClusterIP:Service 在集群内的唯一 ip 地址,我们可以通过这个 ip,均衡的访问到后端的 Pod,而无须关心具体的 Pod。
- NodePort:Service 会在集群的每个 Node 上都启动一个端口,我们可以通过任意Node 的这个端口来访问到 Pod。
- LoadBalancer:在 NodePort 的基础上,借助公有云环境创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort。
- ExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)。
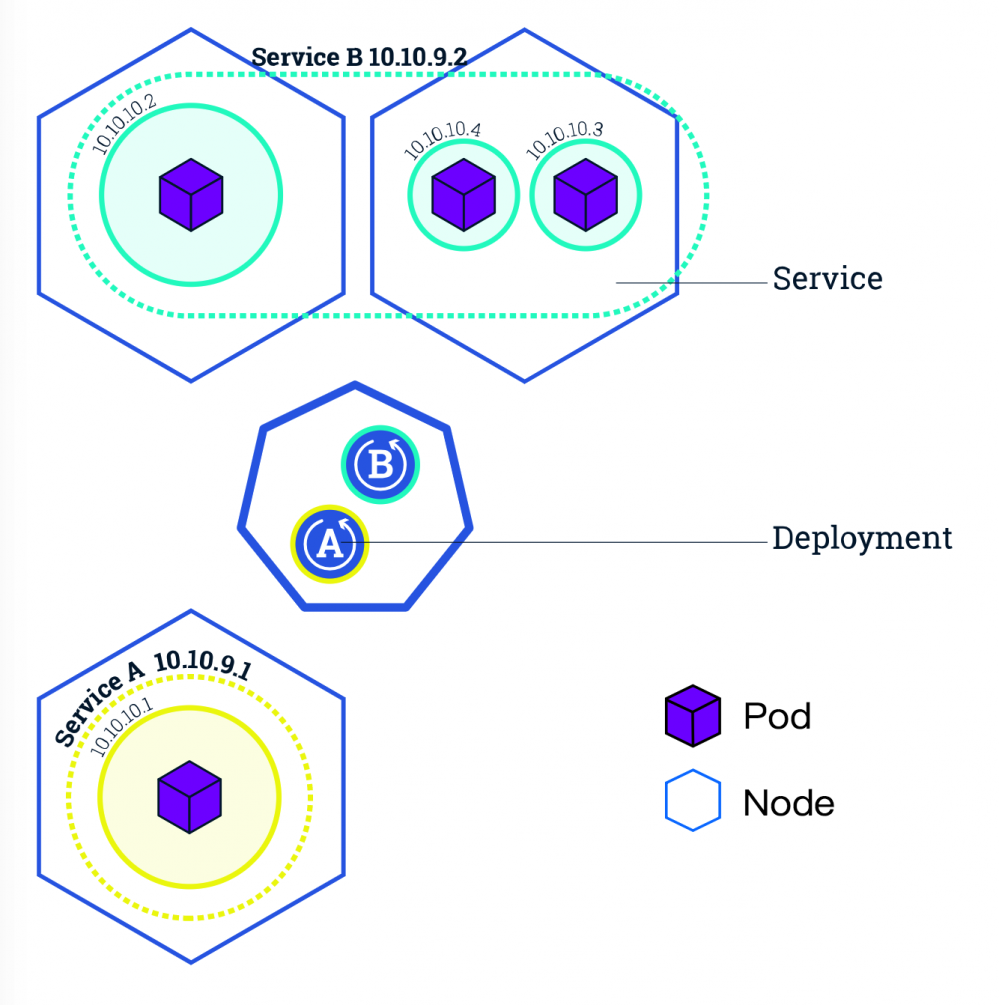
好,看似服务访问的问题解决了。但大家有没有想过,Service是如何知道它负责哪些 Pod 呢?是如何跟踪这些 Pod 变化的?
最容易想到的方法是使用 Deployment 的名字。一个 Service 对应一个 Deployment 。当然这样确实可以实现。但k ubernetes 使用了一个更加灵活、通用的设计 - Label 标签,通过给 Pod 打标签,Service 可以只负责一个 Deployment 的 Pod 也可以负责多个 Deployment 的 Pod 了。Deployment 和 Service 就可以通过 Label 解耦了。

RollingUpdate - 滚动升级
滚动升级是Kubernetes中最典型的服务升级方案,主要思路是一边增加新版本应用的实例数,一边减少旧版本应用的实例数,直到新版本的实例数达到预期,旧版本的实例数减少为0,滚动升级结束。在整个升级过程中,服务一直处于可用状态。并且可以在任意时刻回滚到旧版本。

参考: https://coding.imooc.com/lear...
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

